 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAequeVox: Automated Fairness Testing of Speech Recognition Systems
Oct 19, 2021
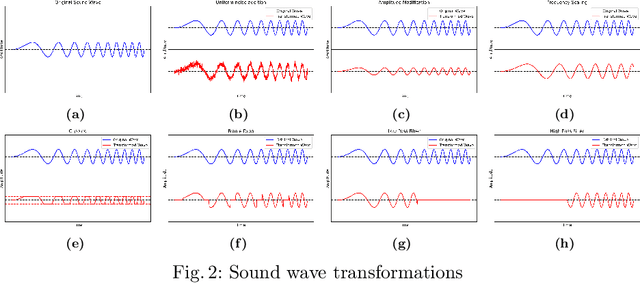

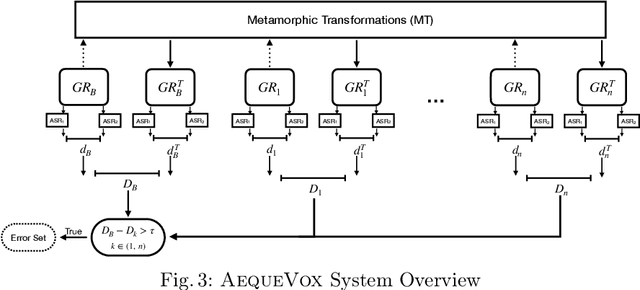
Automatic Speech Recognition (ASR) systems have become ubiquitous. They can be found in a variety of form factors and are increasingly important in our daily lives. As such, ensuring that these systems are equitable to different subgroups of the population is crucial. In this paper, we introduce, AequeVox, an automated testing framework for evaluating the fairness of ASR systems. AequeVox simulates different environments to assess the effectiveness of ASR systems for different populations. In addition, we investigate whether the chosen simulations are comprehensible to humans. We further propose a fault localization technique capable of identifying words that are not robust to these varying environments. Both components of AequeVox are able to operate in the absence of ground truth data. We evaluated AequeVox on speech from four different datasets using three different commercial ASRs. Our experiments reveal that non-native English, female and Nigerian English speakers generate 109%, 528.5% and 156.9% more errors, on average than native English, male and UK Midlands speakers, respectively. Our user study also reveals that 82.9% of the simulations (employed through speech transformations) had a comprehensibility rating above seven (out of ten), with the lowest rating being 6.78. This further validates the fairness violations discovered by AequeVox. Finally, we show that the non-robust words, as predicted by the fault localization technique embodied in AequeVox, show 223.8% more errors than the predicted robust words across all ASRs.
Astraea: Grammar-based Fairness Testing
Oct 06, 2020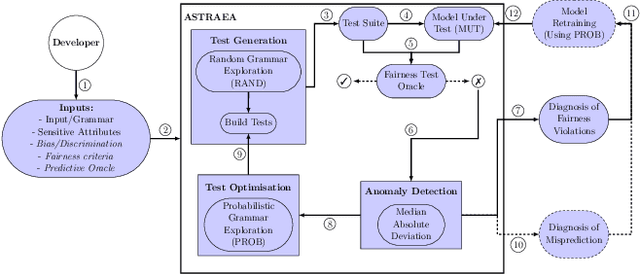


Software often produces biased outputs. In particular, machine learning (ML) based software are known to produce erroneous predictions when processing discriminatory inputs. Such unfair program behavior can be caused by societal bias. In the last few years, Amazon, Microsoft and Google have provided software services that produce unfair outputs, mostly due to societal bias (e.g. gender or race). In such events, developers are saddled with the task of conducting fairness testing. Fairness testing is challenging; developers are tasked with generating discriminatory inputs that reveal and explain biases. We propose a grammar-based fairness testing approach (called ASTRAEA) which leverages context-free grammars to generate discriminatory inputs that reveal fairness violations in software systems. Using probabilistic grammars, ASTRAEA also provides fault diagnosis by isolating the cause of observed software bias. ASTRAEA's diagnoses facilitate the improvement of ML fairness. ASTRAEA was evaluated on 18 software systems that provide three major natural language processing (NLP) services. In our evaluation, ASTRAEA generated fairness violations with a rate of ~18%. ASTRAEA generated over 573K discriminatory test cases and found over 102K fairness violations. Furthermore, ASTRAEA improves software fairness by ~76%, via model-retraining.
Exposing Backdoors in Robust Machine Learning Models
Feb 25, 2020
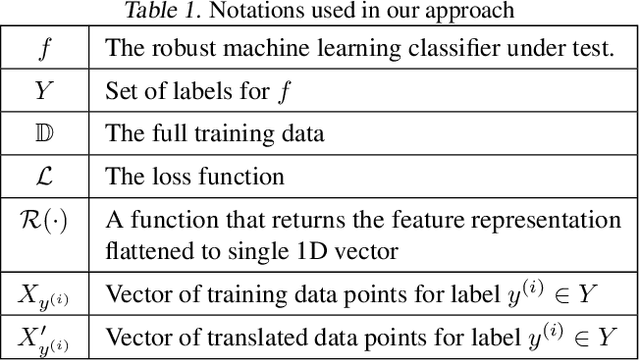


The introduction of robust optimisation has pushed the state-of-the-art in defending against adversarial attacks. However, the behaviour of such optimisation has not been studied in the light of a fundamentally different class of attacks called backdoors. In this paper, we demonstrate that adversarially robust models are susceptible to backdoor attacks. Subsequently, we observe that backdoors are reflected in the feature representation of such models. Then, this is leveraged to detect backdoor-infected models. Specifically, we use feature clustering to effectively detect backdoor-infected robust Deep Neural Networks (DNNs). In our evaluation of major classification tasks, our approach effectively detects robust DNNs infected with backdoors. Our investigation reveals that salient features of adversarially robust DNNs break the stealthy nature of backdoor attacks.
Callisto: Entropy based test generation and data quality assessment for Machine Learning Systems
Dec 11, 2019

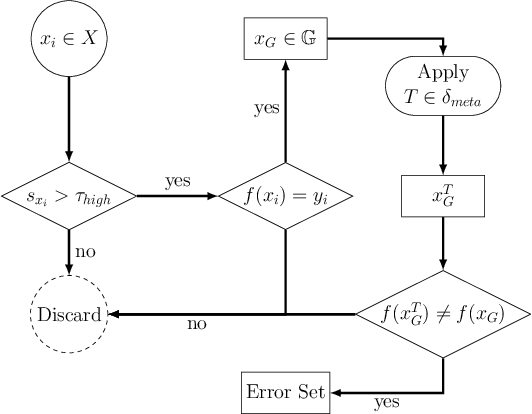
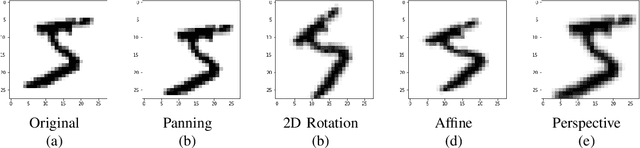
Machine Learning (ML) has seen massive progress in the last decade and as a result, there is a pressing need for validating ML-based systems. To this end, we propose, design and evaluate CALLISTO - a novel test generation and data quality assessment framework. To the best of our knowledge, CALLISTO is the first blackbox framework to leverage the uncertainty in the prediction and systematically generate new test cases for ML classifiers. Our evaluation of CALLISTO on four real world data sets reveals thousands of errors. We also show that leveraging the uncertainty in prediction can increase the number of erroneous test cases up to a factor of 20, as compared to when no such knowledge is used for testing. CALLISTO has the capability to detect low quality data in the datasets that may contain mislabelled data. We conduct and present an extensive user study to validate the results of CALLISTO on identifying low quality data from four state-of-the-art real world datasets.
Model Agnostic Defence against Backdoor Attacks in Machine Learning
Aug 28, 2019
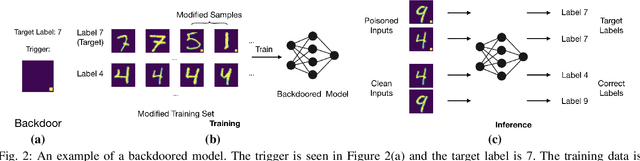


Machine Learning (ML) has automated a multitude of our day-to-day decision making domains such as education, employment and driving automation. The continued success of ML largely depends on our ability to trust the model we are using. Recently, a new class of attacks called Backdoor Attacks have been developed. These attacks undermine the user's trust in ML models. In this work, we present NEO, a model agnostic framework to detect and mitigate such backdoor attacks in image classification ML models. For a given image classification model, our approach analyses the inputs it receives and determines if the model is backdoored. In addition to this feature, we also mitigate these attacks by determining the correct predictions of the poisoned images. An appealing feature of NEO is that it can, for the first time, isolate and reconstruct the backdoor trigger. NEO is also the first defence methodology, to the best of our knowledge that is completely blackbox. We have implemented NEO and evaluated it against three state of the art poisoned models. These models include highly critical applications such as traffic sign detection (USTS) and facial detection. In our evaluation, we show that NEO can detect $\approx$88\% of the poisoned inputs on average and it is as fast as 4.4 ms per input image. We also reconstruct the poisoned input for the user to effectively test their systems.
Grammar Based Directed Testing of Machine Learning Systems
Feb 26, 2019

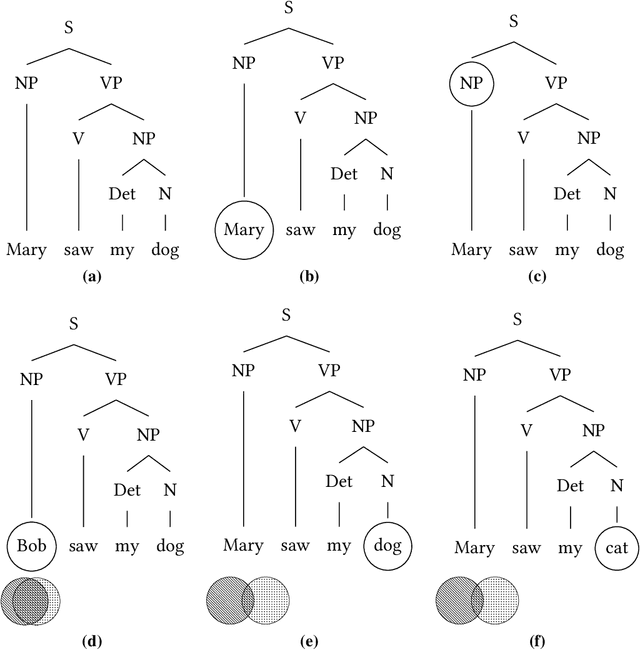

The massive progress of machine learning has seen its application over a variety of domains in the past decade. But how do we develop a systematic, scalable and modular strategy to validate machine-learning systems? We present, to the best of our knowledge, the first approach, which provides a systematic test framework for machine-learning systems that accepts grammar-based inputs. Our OGMA approach automatically discovers erroneous behaviours in classifiers and leverages these erroneous behaviours to improve the respective models. OGMA leverages inherent robustness properties present in any well trained machine-learning model to direct test generation and thus, implementing a scalable test generation methodology. To evaluate our OGMA approach, we have tested it on three real world natural language processing (NLP) classifiers. We have found thousands of erroneous behaviours in these systems. We also compare OGMA with a random test generation approach and observe that OGMA is more effective than such random test generation by up to 489%.
Automated Directed Fairness Testing
Jul 31, 2018

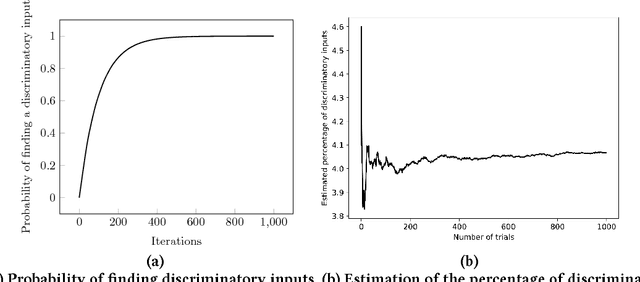
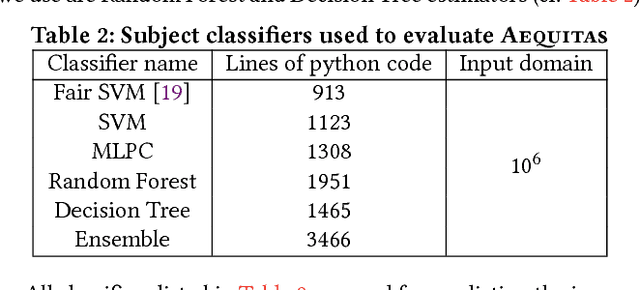
Fairness is a critical trait in decision making. As machine-learning models are increasingly being used in sensitive application domains (e.g. education and employment) for decision making, it is crucial that the decisions computed by such models are free of unintended bias. But how can we automatically validate the fairness of arbitrary machine-learning models? For a given machine-learning model and a set of sensitive input parameters, our AEQUITAS approach automatically discovers discriminatory inputs that highlight fairness violation. At the core of AEQUITAS are three novel strategies to employ probabilistic search over the input space with the objective of uncovering fairness violation. Our AEQUITAS approach leverages inherent robustness property in common machine-learning models to design and implement scalable test generation methodologies. An appealing feature of our generated test inputs is that they can be systematically added to the training set of the underlying model and improve its fairness. To this end, we design a fully automated module that guarantees to improve the fairness of the underlying model. We implemented AEQUITAS and we have evaluated it on six state-of-the-art classifiers, including a classifier that was designed with fairness constraints. We show that AEQUITAS effectively generates inputs to uncover fairness violation in all the subject classifiers and systematically improves the fairness of the respective models using the generated test inputs. In our evaluation, AEQUITAS generates up to 70% discriminatory inputs (w.r.t. the total number of inputs generated) and leverages these inputs to improve the fairness up to 94%.
* In Proceedings of the 2018 33rd ACM/IEEE International Conference on Automated Software Engineering (ASE 18), September 3-7, 2018, Montpellier, France