 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToto 2.0: Time Series Forecasting Enters the Scaling Era
May 19, 2026We show that time series foundation models scale: a single training recipe produces reliable forecast-quality improvements from 4M to 2.5B parameters. We release Toto 2.0, a family of five open-weights forecasting models trained under this recipe. The Toto 2.0 family sets a new state of the art on three forecasting benchmarks: BOOM, our observability benchmark; GIFT-Eval, the standard general-purpose benchmark; and the recent contamination-resistant TIME benchmark. This report describes our experimental results and details the design decisions behind Toto 2.0: its architecture and training recipe, training data, and the u-muP hyperparameter transfer pipeline. All five base checkpoints are released under Apache 2.0.
Moirai-MoE: Empowering Time Series Foundation Models with Sparse Mixture of Experts
Oct 14, 2024



Time series foundation models have demonstrated impressive performance as zero-shot forecasters. However, achieving effectively unified training on time series remains an open challenge. Existing approaches introduce some level of model specialization to account for the highly heterogeneous nature of time series data. For instance, Moirai pursues unified training by employing multiple input/output projection layers, each tailored to handle time series at a specific frequency. Similarly, TimesFM maintains a frequency embedding dictionary for this purpose. We identify two major drawbacks to this human-imposed frequency-level model specialization: (1) Frequency is not a reliable indicator of the underlying patterns in time series. For example, time series with different frequencies can display similar patterns, while those with the same frequency may exhibit varied patterns. (2) Non-stationarity is an inherent property of real-world time series, leading to varied distributions even within a short context window of a single time series. Frequency-level specialization is too coarse-grained to capture this level of diversity. To address these limitations, this paper introduces Moirai-MoE, using a single input/output projection layer while delegating the modeling of diverse time series patterns to the sparse mixture of experts (MoE) within Transformers. With these designs, Moirai-MoE reduces reliance on human-defined heuristics and enables automatic token-level specialization. Extensive experiments on 39 datasets demonstrate the superiority of Moirai-MoE over existing foundation models in both in-distribution and zero-shot scenarios. Furthermore, this study conducts comprehensive model analyses to explore the inner workings of time series MoE foundation models and provides valuable insights for future research.
GIFT-Eval: A Benchmark For General Time Series Forecasting Model Evaluation
Oct 14, 2024



Time series foundation models excel in zero-shot forecasting, handling diverse tasks without explicit training. However, the advancement of these models has been hindered by the lack of comprehensive benchmarks. To address this gap, we introduce the General Time Series Forecasting Model Evaluation, GIFT-Eval, a pioneering benchmark aimed at promoting evaluation across diverse datasets. GIFT-Eval encompasses 28 datasets over 144,000 time series and 177 million data points, spanning seven domains, 10 frequencies, multivariate inputs, and prediction lengths ranging from short to long-term forecasts. To facilitate the effective pretraining and evaluation of foundation models, we also provide a non-leaking pretraining dataset containing approximately 230 billion data points. Additionally, we provide a comprehensive analysis of 17 baselines, which includes statistical models, deep learning models, and foundation models. We discuss each model in the context of various benchmark characteristics and offer a qualitative analysis that spans both deep learning and foundation models. We believe the insights from this analysis, along with access to this new standard zero-shot time series forecasting benchmark, will guide future developments in time series foundation models. The codebase, datasets, and a leaderboard showing all the results in detail will be available soon.
UniTST: Effectively Modeling Inter-Series and Intra-Series Dependencies for Multivariate Time Series Forecasting
Jun 07, 2024



Transformer-based models have emerged as powerful tools for multivariate time series forecasting (MTSF). However, existing Transformer models often fall short of capturing both intricate dependencies across variate and temporal dimensions in MTS data. Some recent models are proposed to separately capture variate and temporal dependencies through either two sequential or parallel attention mechanisms. However, these methods cannot directly and explicitly learn the intricate inter-series and intra-series dependencies. In this work, we first demonstrate that these dependencies are very important as they usually exist in real-world data. To directly model these dependencies, we propose a transformer-based model UniTST containing a unified attention mechanism on the flattened patch tokens. Additionally, we add a dispatcher module which reduces the complexity and makes the model feasible for a potentially large number of variates. Although our proposed model employs a simple architecture, it offers compelling performance as shown in our extensive experiments on several datasets for time series forecasting.
Unified Training of Universal Time Series Forecasting Transformers
Feb 04, 2024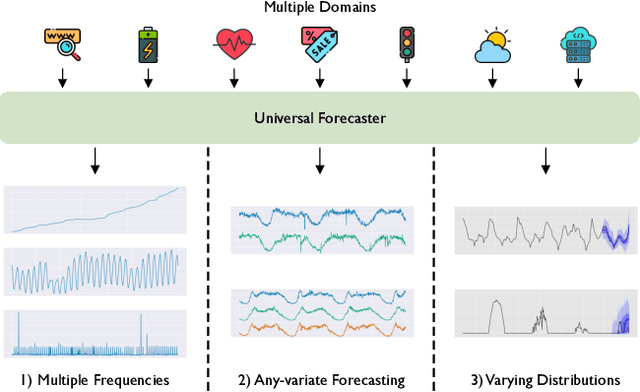

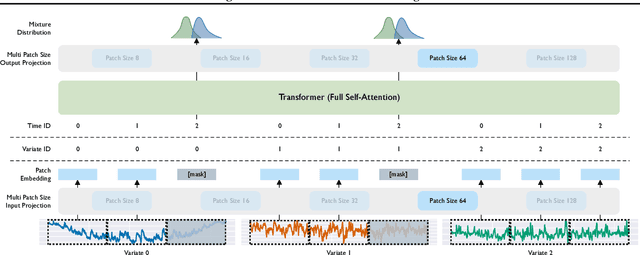

Deep learning for time series forecasting has traditionally operated within a one-model-per-dataset framework, limiting its potential to leverage the game-changing impact of large pre-trained models. The concept of universal forecasting, emerging from pre-training on a vast collection of time series datasets, envisions a single Large Time Series Model capable of addressing diverse downstream forecasting tasks. However, constructing such a model poses unique challenges specific to time series data: i) cross-frequency learning, ii) accommodating an arbitrary number of variates for multivariate time series, and iii) addressing the varying distributional properties inherent in large-scale data. To address these challenges, we present novel enhancements to the conventional time series Transformer architecture, resulting in our proposed Masked Encoder-based Universal Time Series Forecasting Transformer (Moirai). Trained on our newly introduced Large-scale Open Time Series Archive (LOTSA) featuring over 27B observations across nine domains, Moirai achieves competitive or superior performance as a zero-shot forecaster when compared to full-shot models. Code, model weights, and data will be released.
Pushing the Limits of Pre-training for Time Series Forecasting in the CloudOps Domain
Oct 10, 2023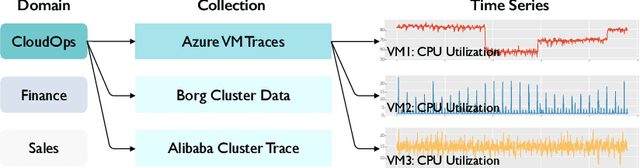

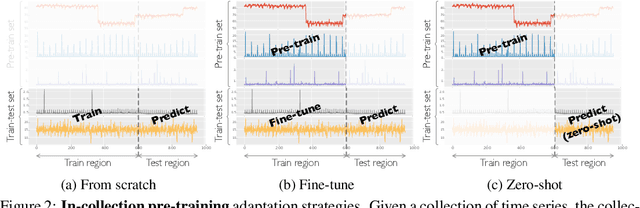

Time series has been left behind in the era of pre-training and transfer learning. While research in the fields of natural language processing and computer vision are enjoying progressively larger datasets to train massive models, the most popular time series datasets consist of only tens of thousands of time steps, limiting our ability to study the effectiveness of pre-training and scaling. Recent studies have also cast doubt on the need for expressive models and scale. To alleviate these issues, we introduce three large-scale time series forecasting datasets from the cloud operations (CloudOps) domain, the largest having billions of observations, enabling further study into pre-training and scaling of time series models. We build the empirical groundwork for studying pre-training and scaling of time series models and pave the way for future research by identifying a promising candidate architecture. We show that it is a strong zero-shot baseline and benefits from further scaling, both in model and dataset size. Accompanying these datasets and results is a suite of comprehensive benchmark results comparing classical and deep learning baselines to our pre-trained method - achieving a 27% reduction in error on the largest dataset. Code and datasets will be released.
AI for IT Operations on Cloud Platforms: Reviews, Opportunities and Challenges
Apr 10, 2023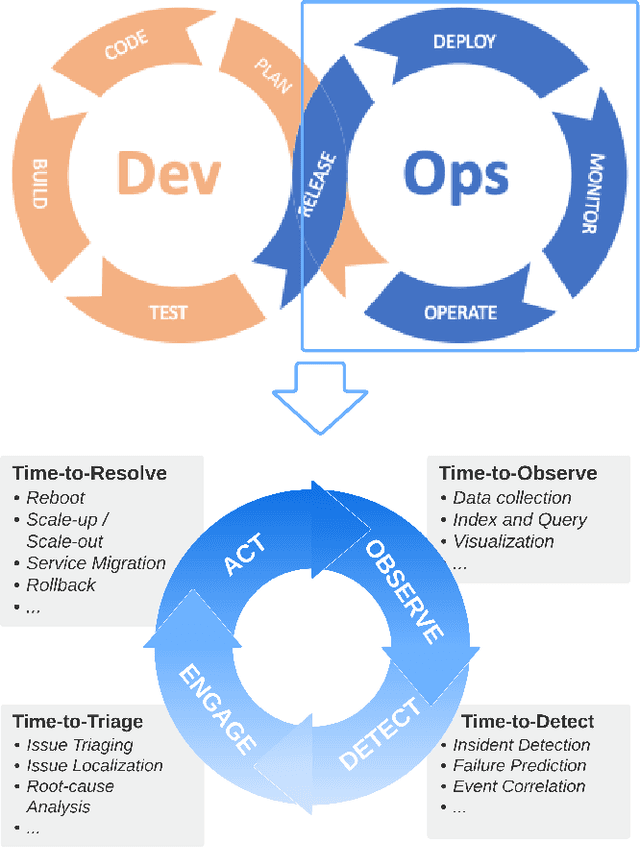
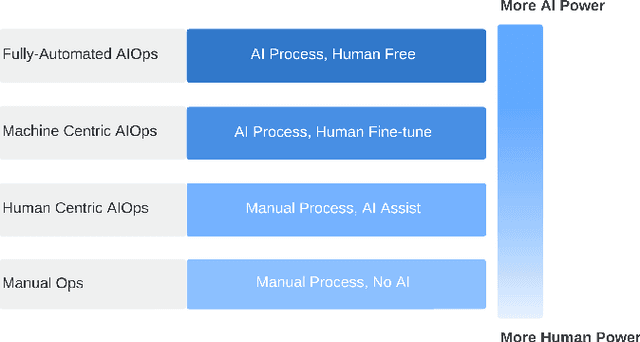
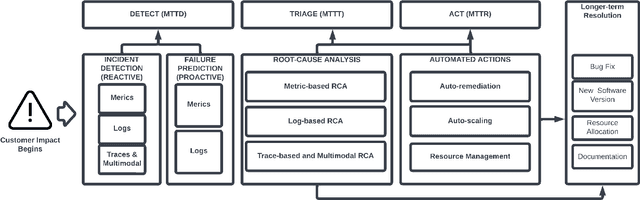
Artificial Intelligence for IT operations (AIOps) aims to combine the power of AI with the big data generated by IT Operations processes, particularly in cloud infrastructures, to provide actionable insights with the primary goal of maximizing availability. There are a wide variety of problems to address, and multiple use-cases, where AI capabilities can be leveraged to enhance operational efficiency. Here we provide a review of the AIOps vision, trends challenges and opportunities, specifically focusing on the underlying AI techniques. We discuss in depth the key types of data emitted by IT Operations activities, the scale and challenges in analyzing them, and where they can be helpful. We categorize the key AIOps tasks as - incident detection, failure prediction, root cause analysis and automated actions. We discuss the problem formulation for each task, and then present a taxonomy of techniques to solve these problems. We also identify relatively under explored topics, especially those that could significantly benefit from advances in AI literature. We also provide insights into the trends in this field, and what are the key investment opportunities.
DeepTIMe: Deep Time-Index Meta-Learning for Non-Stationary Time-Series Forecasting
Jul 14, 2022


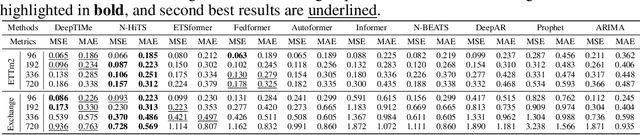
Deep learning has been actively applied to time-series forecasting, leading to a deluge of new autoregressive model architectures. Yet, despite the attractive properties of time-index based models, such as being a continuous signal function over time leading to smooth representations, little attention has been given to them. Indeed, while naive deep time-index based models are far more expressive than the manually predefined function representations of classical time-index based models, they are inadequate for forecasting due to the lack of inductive biases, and the non-stationarity of time-series. In this paper, we propose DeepTIMe, a deep time-index based model trained via a meta-learning formulation which overcomes these limitations, yielding an efficient and accurate forecasting model. Extensive experiments on real world datasets demonstrate that our approach achieves competitive results with state-of-the-art methods, and is highly efficient. Code is available at https://github.com/salesforce/DeepTIMe.
CoST: Contrastive Learning of Disentangled Seasonal-Trend Representations for Time Series Forecasting
Feb 03, 2022

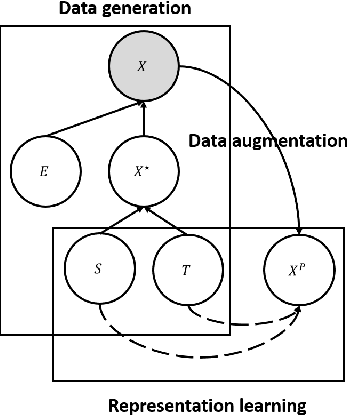

Deep learning has been actively studied for time series forecasting, and the mainstream paradigm is based on the end-to-end training of neural network architectures, ranging from classical LSTM/RNNs to more recent TCNs and Transformers. Motivated by the recent success of representation learning in computer vision and natural language processing, we argue that a more promising paradigm for time series forecasting, is to first learn disentangled feature representations, followed by a simple regression fine-tuning step -- we justify such a paradigm from a causal perspective. Following this principle, we propose a new time series representation learning framework for time series forecasting named CoST, which applies contrastive learning methods to learn disentangled seasonal-trend representations. CoST comprises both time domain and frequency domain contrastive losses to learn discriminative trend and seasonal representations, respectively. Extensive experiments on real-world datasets show that CoST consistently outperforms the state-of-the-art methods by a considerable margin, achieving a 21.3\% improvement in MSE on multivariate benchmarks. It is also robust to various choices of backbone encoders, as well as downstream regressors.
ETSformer: Exponential Smoothing Transformers for Time-series Forecasting
Feb 03, 2022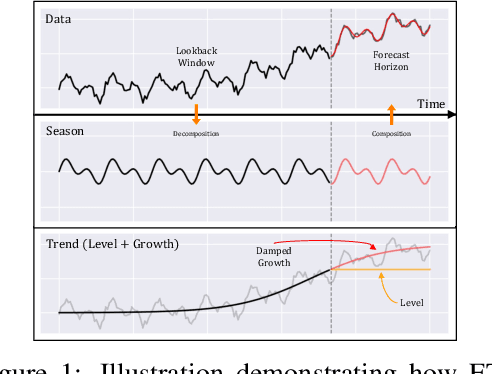


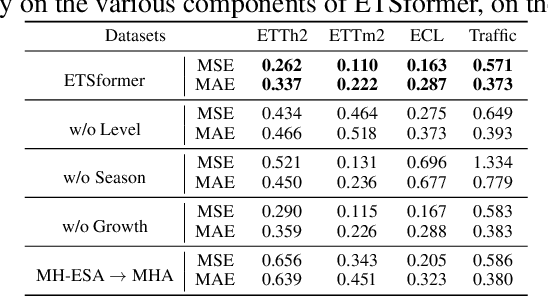
Transformers have been actively studied for time-series forecasting in recent years. While often showing promising results in various scenarios, traditional Transformers are not designed to fully exploit the characteristics of time-series data and thus suffer some fundamental limitations, e.g., they generally lack of decomposition capability and interpretability, and are neither effective nor efficient for long-term forecasting. In this paper, we propose ETSFormer, a novel time-series Transformer architecture, which exploits the principle of exponential smoothing in improving Transformers for time-series forecasting. In particular, inspired by the classical exponential smoothing methods in time-series forecasting, we propose the novel exponential smoothing attention (ESA) and frequency attention (FA) to replace the self-attention mechanism in vanilla Transformers, thus improving both accuracy and efficiency. Based on these, we redesign the Transformer architecture with modular decomposition blocks such that it can learn to decompose the time-series data into interpretable time-series components such as level, growth and seasonality. Extensive experiments on various time-series benchmarks validate the efficacy and advantages of the proposed method. The code and models of our implementations will be released.