 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriEval: A Resource-Efficient Pipeline for LLM Bias, Toxicity, and Truthfulness Assessment
Jun 02, 2026LLMs have evolved from basic chatbots to the backbone of the AI ecosystem, now widely used in healthcare, schools, and government services. The domain-wide adoption of LLMs necessitates continuous evaluation to ensure their safety and fairness. Common issues encountered after deploying LLMs include inconsistent outputs and hallucinations of incorrect information. Although numerous LLM evaluation tools exist, most are limited to testing a single parameter at a time or require massive computational resources that are not accessible to most researchers. TriEval addresses these challenges by evaluating LLM outputs across multiple parameters, including bias, toxicity, and truthfulness together, while minimizing computing resources. The pipeline is compatible with both open- and closed-source models and runs on a standard laptop without a GPU cluster. TriEval has been tested on four models: Llama 3 8B, Mistral 7B, Gemma 2 9B, and Claude Haiku. The results show clear differences between open-source and closed-source models, especially in terms of toxicity and truthfulness. TriEval is being released as open source to enable broader access for researchers with limited computational resources.
CodeEvolve: LLM-Driven Evolutionary Optimization with Runtime-Enriched Target Selection for Multi-Language Code Enhancement
May 06, 2026We present CodeEvolve, an evolutionary framework for improving program performance and code quality with Large Language Models (LLMs). CodeEvolve extends OpenEvolve with runtime-guided target selection, Monte Carlo Tree Search (MCTS), automated code refinement, and language-specific evaluation pipelines for Java and Salesforce Apex. The system uses Java Flight Recorder (JFR) profiles to build weighted component graphs and select optimization targets that account for most execution cost, reducing reliance on manual bottleneck identification. For each target, CodeEvolve generates candidate edits, evaluates them through build validation, unit tests, performance checks, static analysis, and LLM-based review, and retains only variants that preserve functional correctness. Across real-world optimization tasks, CodeEvolve improves performance and code metrics while maintaining correctness. On a large enterprise Java codebase, it achieves an average speedup of 15.22$\times$ across seven hotspot functions and outperforms single-pass LLM optimization on five of them. An ablation study on Apex optimization shows that the full MCTS-augmented configuration produces 19.5 valid programs out of 20 on average, indicating that search, filtering, and refinement each contribute to more reliable optimization.
Fine-grained large-scale content recommendations for MSX sellers
Jul 09, 2024



One of the most critical tasks of Microsoft sellers is to meticulously track and nurture potential business opportunities through proactive engagement and tailored solutions. Recommender systems play a central role to help sellers achieve their goals. In this paper, we present a content recommendation model which surfaces various types of content (technical documentation, comparison with competitor products, customer success stories etc.) that sellers can share with their customers or use for their own self-learning. The model operates at the opportunity level which is the lowest possible granularity and the most relevant one for sellers. It is based on semantic matching between metadata from the contents and carefully selected attributes of the opportunities. Considering the volume of seller-managed opportunities in organizations such as Microsoft, we show how to perform efficient semantic matching over a very large number of opportunity-content combinations. The main challenge is to ensure that the top-5 relevant contents for each opportunity are recommended out of a total of $\approx 40,000$ published contents. We achieve this target through an extensive comparison of different model architectures and feature selection. Finally, we further examine the quality of the recommendations in a quantitative manner using a combination of human domain experts as well as by using the recently proposed "LLM as a judge" framework.
A case study of Generative AI in MSX Sales Copilot: Improving seller productivity with a real-time question-answering system for content recommendation
Jan 04, 2024In this paper, we design a real-time question-answering system specifically targeted for helping sellers get relevant material/documentation they can share live with their customers or refer to during a call. Taking the Seismic content repository as a relatively large scale example of a diverse dataset of sales material, we demonstrate how LLM embeddings of sellers' queries can be matched with the relevant content. We achieve this by engineering prompts in an elaborate fashion that makes use of the rich set of meta-features available for documents and sellers. Using a bi-encoder with cross-encoder re-ranker architecture, we show how the solution returns the most relevant content recommendations in just a few seconds even for large datasets. Our recommender system is deployed as an AML endpoint for real-time inferencing and has been integrated into a Copilot interface that is now deployed in the production version of the Dynamics CRM, known as MSX, used daily by Microsoft sellers.
Motion Informed Needle Segmentation in Ultrasound Images
Dec 05, 2023



Segmenting a moving needle in ultrasound images is challenging due to the presence of artifacts, noise, and needle occlusion. This task becomes even more demanding in scenarios where data availability is limited. Convolutional Neural Networks (CNNs) have been successful in many computer vision applications, but struggle to accurately segment needles without considering their motion. In this paper, we present a novel approach for needle segmentation that combines classical Kalman Filter (KF) techniques with data-driven learning, incorporating both needle features and needle motion. Our method offers two key contributions. First, we propose a compatible framework that seamlessly integrates into commonly used encoder-decoder style architectures. Second, we demonstrate superior performance compared to recent state-of-the-art needle segmentation models using our novel convolutional neural network (CNN) based KF-inspired block, achieving a 15\% reduction in pixel-wise needle tip error and an 8\% reduction in length error. Third, to our knowledge we are the first to implement a learnable filter to incorporate non-linear needle motion for improving needle segmentation.
PyRCA: A Library for Metric-based Root Cause Analysis
Jun 20, 2023We introduce PyRCA, an open-source Python machine learning library of Root Cause Analysis (RCA) for Artificial Intelligence for IT Operations (AIOps). It provides a holistic framework to uncover the complicated metric causal dependencies and automatically locate root causes of incidents. It offers a unified interface for multiple commonly used RCA models, encompassing both graph construction and scoring tasks. This library aims to provide IT operations staff, data scientists, and researchers a one-step solution to rapid model development, model evaluation and deployment to online applications. In particular, our library includes various causal discovery methods to support causal graph construction, and multiple types of root cause scoring methods inspired by Bayesian analysis, graph analysis and causal analysis, etc. Our GUI dashboard offers practitioners an intuitive point-and-click interface, empowering them to easily inject expert knowledge through human interaction. With the ability to visualize causal graphs and the root cause of incidents, practitioners can quickly gain insights and improve their workflow efficiency. This technical report introduces PyRCA's architecture and major functionalities, while also presenting benchmark performance numbers in comparison to various baseline models. Additionally, we demonstrate PyRCA's capabilities through several example use cases.
AI for IT Operations on Cloud Platforms: Reviews, Opportunities and Challenges
Apr 10, 2023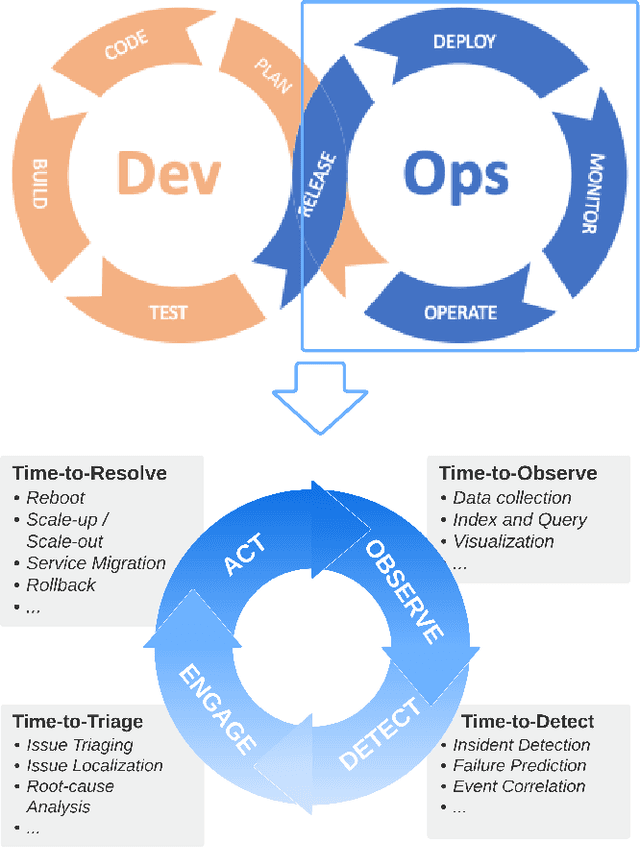
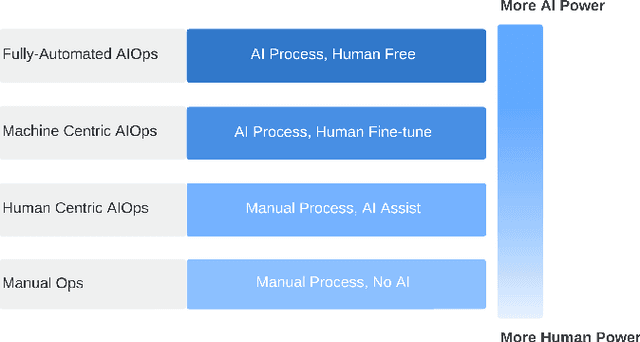
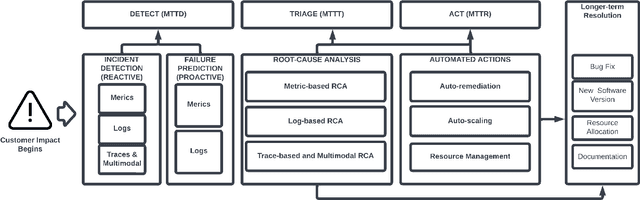
Artificial Intelligence for IT operations (AIOps) aims to combine the power of AI with the big data generated by IT Operations processes, particularly in cloud infrastructures, to provide actionable insights with the primary goal of maximizing availability. There are a wide variety of problems to address, and multiple use-cases, where AI capabilities can be leveraged to enhance operational efficiency. Here we provide a review of the AIOps vision, trends challenges and opportunities, specifically focusing on the underlying AI techniques. We discuss in depth the key types of data emitted by IT Operations activities, the scale and challenges in analyzing them, and where they can be helpful. We categorize the key AIOps tasks as - incident detection, failure prediction, root cause analysis and automated actions. We discuss the problem formulation for each task, and then present a taxonomy of techniques to solve these problems. We also identify relatively under explored topics, especially those that could significantly benefit from advances in AI literature. We also provide insights into the trends in this field, and what are the key investment opportunities.
Merlion: A Machine Learning Library for Time Series
Sep 20, 2021
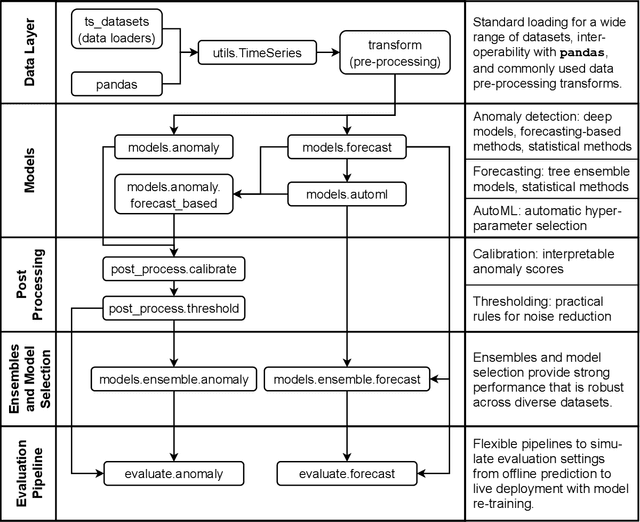
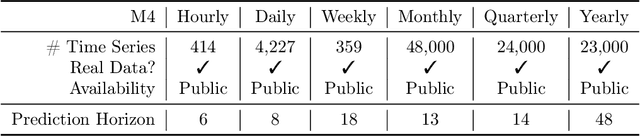

We introduce Merlion, an open-source machine learning library for time series. It features a unified interface for many commonly used models and datasets for anomaly detection and forecasting on both univariate and multivariate time series, along with standard pre/post-processing layers. It has several modules to improve ease-of-use, including visualization, anomaly score calibration to improve interpetability, AutoML for hyperparameter tuning and model selection, and model ensembling. Merlion also provides a unique evaluation framework that simulates the live deployment and re-training of a model in production. This library aims to provide engineers and researchers a one-stop solution to rapidly develop models for their specific time series needs and benchmark them across multiple time series datasets. In this technical report, we highlight Merlion's architecture and major functionalities, and we report benchmark numbers across different baseline models and ensembles.