 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained large-scale content recommendations for MSX sellers
Jul 09, 2024



One of the most critical tasks of Microsoft sellers is to meticulously track and nurture potential business opportunities through proactive engagement and tailored solutions. Recommender systems play a central role to help sellers achieve their goals. In this paper, we present a content recommendation model which surfaces various types of content (technical documentation, comparison with competitor products, customer success stories etc.) that sellers can share with their customers or use for their own self-learning. The model operates at the opportunity level which is the lowest possible granularity and the most relevant one for sellers. It is based on semantic matching between metadata from the contents and carefully selected attributes of the opportunities. Considering the volume of seller-managed opportunities in organizations such as Microsoft, we show how to perform efficient semantic matching over a very large number of opportunity-content combinations. The main challenge is to ensure that the top-5 relevant contents for each opportunity are recommended out of a total of $\approx 40,000$ published contents. We achieve this target through an extensive comparison of different model architectures and feature selection. Finally, we further examine the quality of the recommendations in a quantitative manner using a combination of human domain experts as well as by using the recently proposed "LLM as a judge" framework.
A case study of Generative AI in MSX Sales Copilot: Improving seller productivity with a real-time question-answering system for content recommendation
Jan 04, 2024In this paper, we design a real-time question-answering system specifically targeted for helping sellers get relevant material/documentation they can share live with their customers or refer to during a call. Taking the Seismic content repository as a relatively large scale example of a diverse dataset of sales material, we demonstrate how LLM embeddings of sellers' queries can be matched with the relevant content. We achieve this by engineering prompts in an elaborate fashion that makes use of the rich set of meta-features available for documents and sellers. Using a bi-encoder with cross-encoder re-ranker architecture, we show how the solution returns the most relevant content recommendations in just a few seconds even for large datasets. Our recommender system is deployed as an AML endpoint for real-time inferencing and has been integrated into a Copilot interface that is now deployed in the production version of the Dynamics CRM, known as MSX, used daily by Microsoft sellers.
Searching, fast and slow, through product catalogs
Jan 01, 2024String matching algorithms in the presence of abbreviations, such as in Stock Keeping Unit (SKU) product catalogs, remains a relatively unexplored topic. In this paper, we present a unified architecture for SKU search that provides both a real-time suggestion system (based on a Trie data structure) as well as a lower latency search system (making use of character level TF-IDF in combination with language model vector embeddings) where users initiate the search process explicitly. We carry out ablation studies that justify designing a complex search system composed of multiple components to address the delicate trade-off between speed and accuracy. Using SKU search in the Dynamics CRM as an example, we show how our system vastly outperforms, in all aspects, the results provided by the default search engine. Finally, we show how SKU descriptions may be enhanced via generative text models (using gpt-3.5-turbo) so that the consumers of the search results may get more context and a generally better experience when presented with the results of their SKU search.
Domain specificity and data efficiency in typo tolerant spell checkers: the case of search in online marketplaces
Aug 03, 2023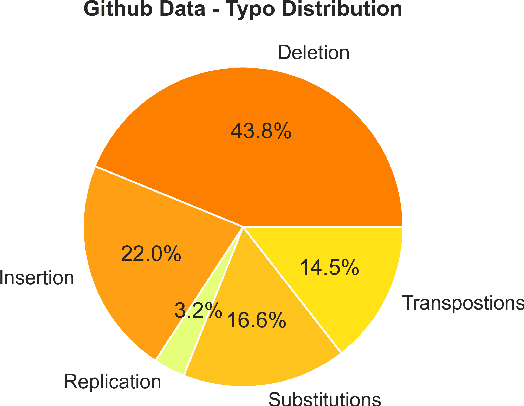
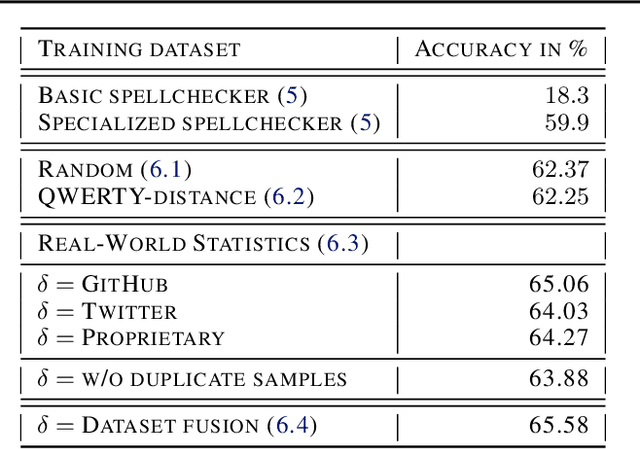
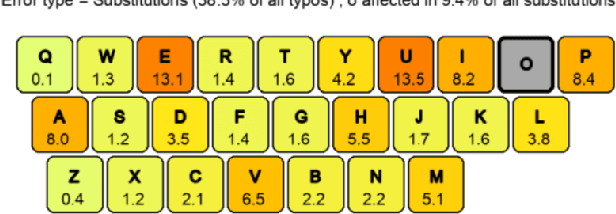
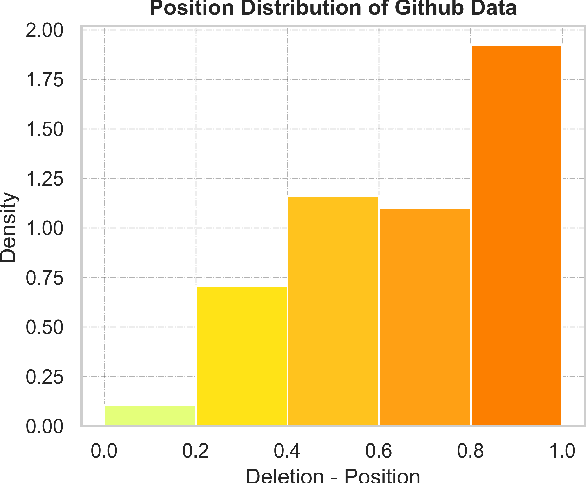
Typographical errors are a major source of frustration for visitors of online marketplaces. Because of the domain-specific nature of these marketplaces and the very short queries users tend to search for, traditional spell cheking solutions do not perform well in correcting typos. We present a data augmentation method to address the lack of annotated typo data and train a recurrent neural network to learn context-limited domain-specific embeddings. Those embeddings are deployed in a real-time inferencing API for the Microsoft AppSource marketplace to find the closest match between a misspelled user query and the available product names. Our data efficient solution shows that controlled high quality synthetic data may be a powerful tool especially considering the current climate of large language models which rely on prohibitively huge and often uncontrolled datasets.