 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain specificity and data efficiency in typo tolerant spell checkers: the case of search in online marketplaces
Paper and Code
Aug 03, 2023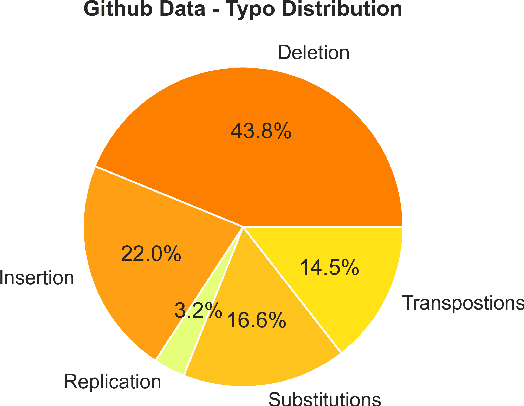
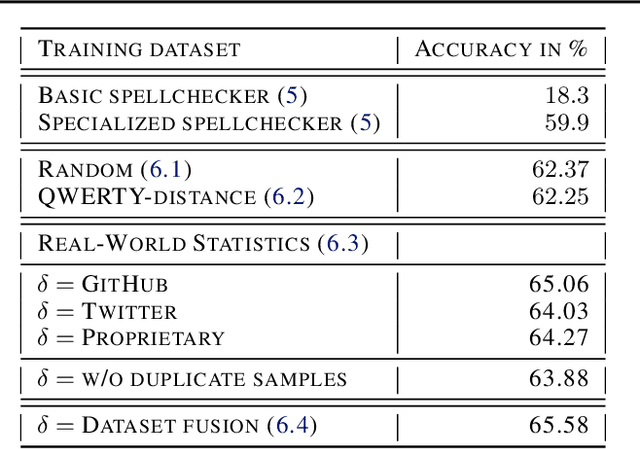
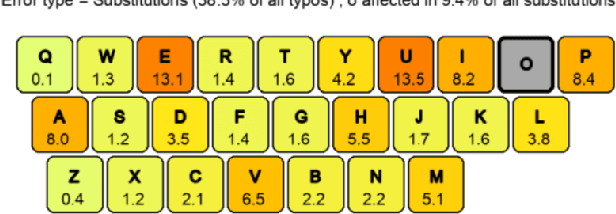
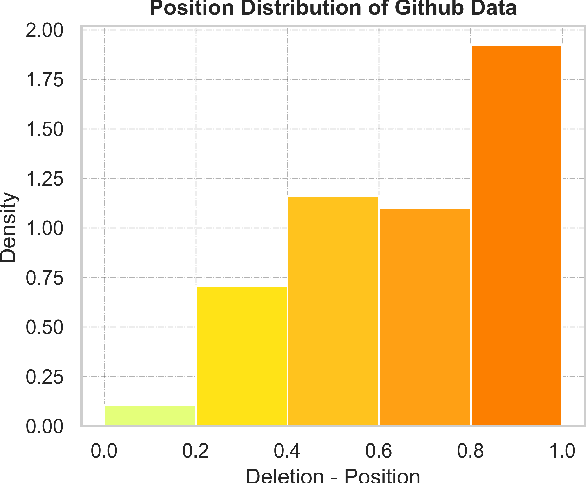
Typographical errors are a major source of frustration for visitors of online marketplaces. Because of the domain-specific nature of these marketplaces and the very short queries users tend to search for, traditional spell cheking solutions do not perform well in correcting typos. We present a data augmentation method to address the lack of annotated typo data and train a recurrent neural network to learn context-limited domain-specific embeddings. Those embeddings are deployed in a real-time inferencing API for the Microsoft AppSource marketplace to find the closest match between a misspelled user query and the available product names. Our data efficient solution shows that controlled high quality synthetic data may be a powerful tool especially considering the current climate of large language models which rely on prohibitively huge and often uncontrolled datasets.