 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearching, fast and slow, through product catalogs
Jan 01, 2024String matching algorithms in the presence of abbreviations, such as in Stock Keeping Unit (SKU) product catalogs, remains a relatively unexplored topic. In this paper, we present a unified architecture for SKU search that provides both a real-time suggestion system (based on a Trie data structure) as well as a lower latency search system (making use of character level TF-IDF in combination with language model vector embeddings) where users initiate the search process explicitly. We carry out ablation studies that justify designing a complex search system composed of multiple components to address the delicate trade-off between speed and accuracy. Using SKU search in the Dynamics CRM as an example, we show how our system vastly outperforms, in all aspects, the results provided by the default search engine. Finally, we show how SKU descriptions may be enhanced via generative text models (using gpt-3.5-turbo) so that the consumers of the search results may get more context and a generally better experience when presented with the results of their SKU search.
Domain specificity and data efficiency in typo tolerant spell checkers: the case of search in online marketplaces
Aug 03, 2023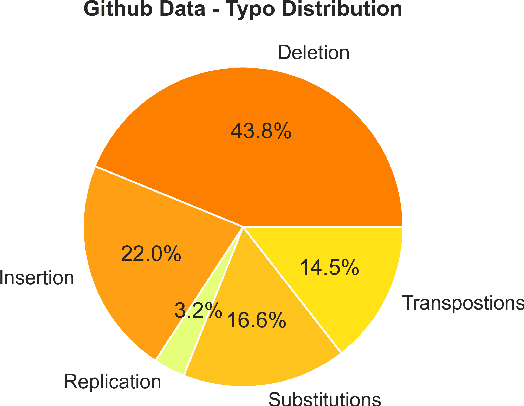
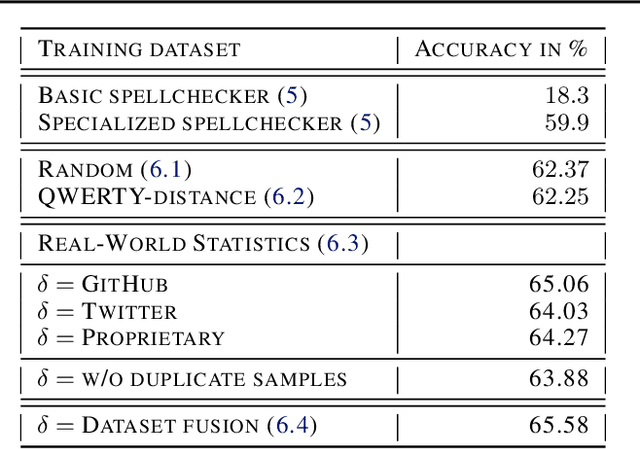
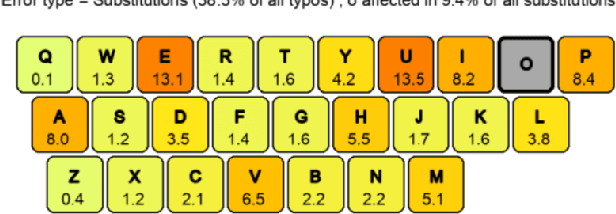
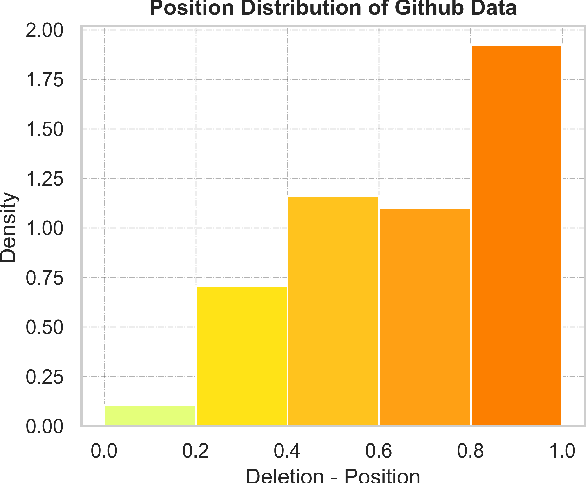
Typographical errors are a major source of frustration for visitors of online marketplaces. Because of the domain-specific nature of these marketplaces and the very short queries users tend to search for, traditional spell cheking solutions do not perform well in correcting typos. We present a data augmentation method to address the lack of annotated typo data and train a recurrent neural network to learn context-limited domain-specific embeddings. Those embeddings are deployed in a real-time inferencing API for the Microsoft AppSource marketplace to find the closest match between a misspelled user query and the available product names. Our data efficient solution shows that controlled high quality synthetic data may be a powerful tool especially considering the current climate of large language models which rely on prohibitively huge and often uncontrolled datasets.
DriveML: An R Package for Driverless Machine Learning
May 01, 2020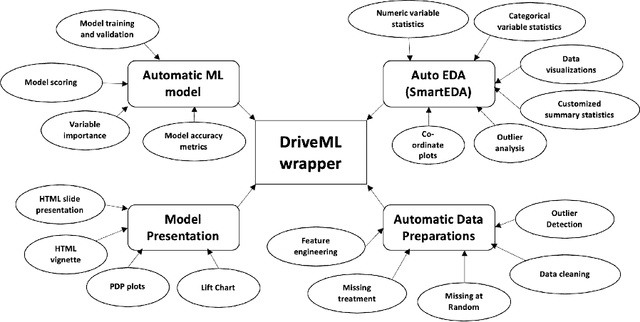
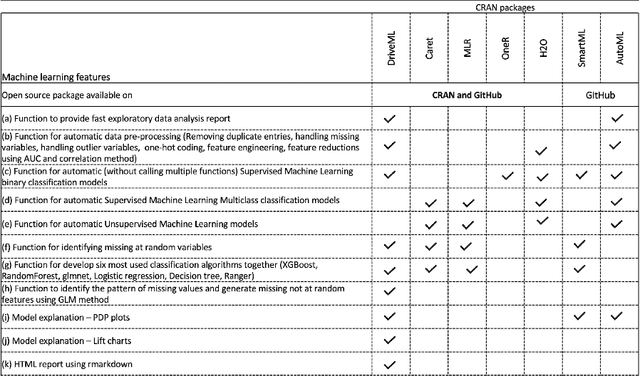
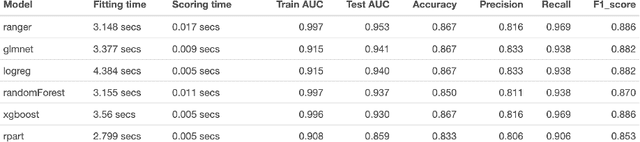
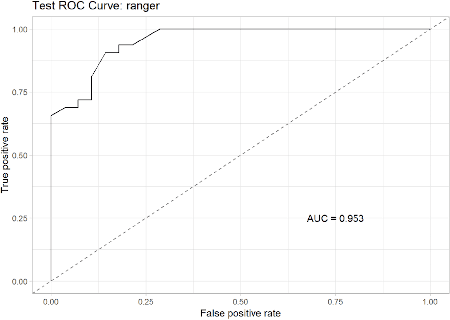
In recent years, the concept of automated machine learning has become very popular. Automated Machine Learning (AutoML) mainly refers to the automated methods for model selection and hyper-parameter optimization of various algorithms such as random forests, gradient boosting, neural networks, etc. In this paper, we introduce a new package i.e. DriveML for automated machine learning. DriveML helps in implementing some of the pillars of an automated machine learning pipeline such as automated data preparation, feature engineering, model building and model explanation by running the function instead of writing lengthy R codes. The DriveML package is available in CRAN. We compare the DriveML package with other relevant packages in CRAN/Github and find that DriveML performs the best across different parameters. We also provide an illustration by applying the DriveML package with default configuration on a real world dataset. Overall, the main benefits of DriveML are in development time savings, reduce developer's errors, optimal tuning of machine learning models and reproducibility.