 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriveML: An R Package for Driverless Machine Learning
May 01, 2020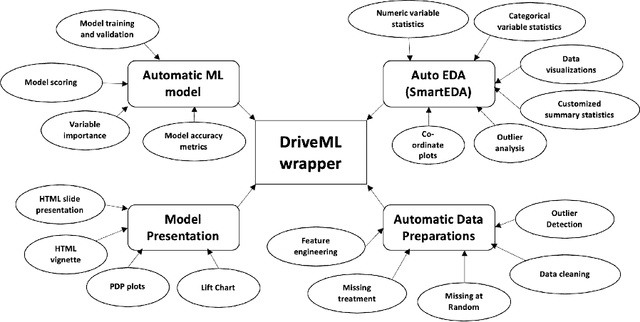
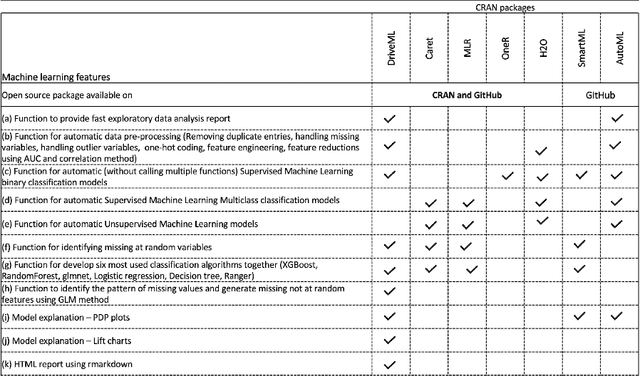
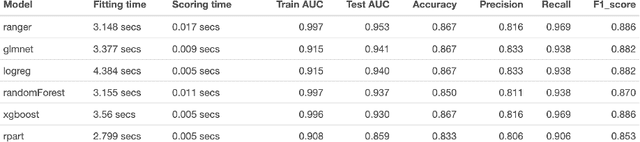
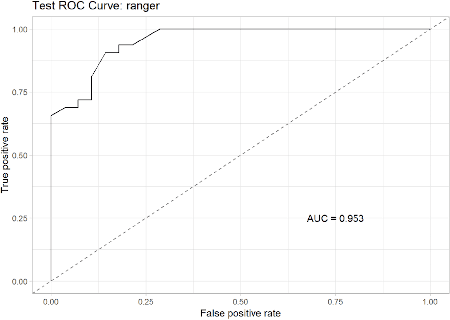
In recent years, the concept of automated machine learning has become very popular. Automated Machine Learning (AutoML) mainly refers to the automated methods for model selection and hyper-parameter optimization of various algorithms such as random forests, gradient boosting, neural networks, etc. In this paper, we introduce a new package i.e. DriveML for automated machine learning. DriveML helps in implementing some of the pillars of an automated machine learning pipeline such as automated data preparation, feature engineering, model building and model explanation by running the function instead of writing lengthy R codes. The DriveML package is available in CRAN. We compare the DriveML package with other relevant packages in CRAN/Github and find that DriveML performs the best across different parameters. We also provide an illustration by applying the DriveML package with default configuration on a real world dataset. Overall, the main benefits of DriveML are in development time savings, reduce developer's errors, optimal tuning of machine learning models and reproducibility.
A Modified Bayesian Optimization based Hyper-Parameter Tuning Approach for Extreme Gradient Boosting
Apr 10, 2020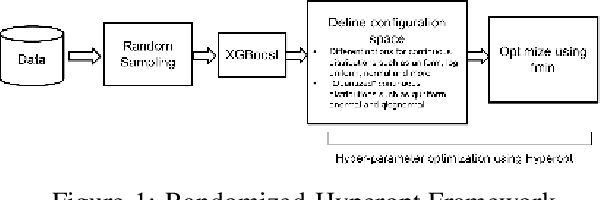
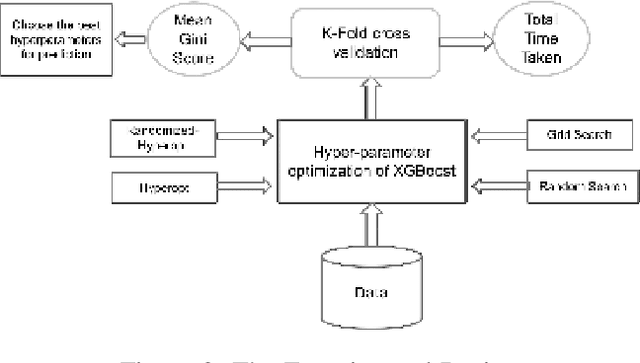
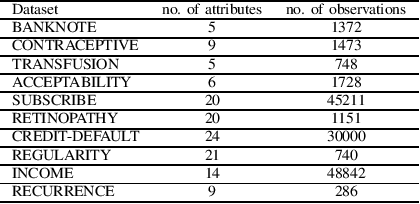
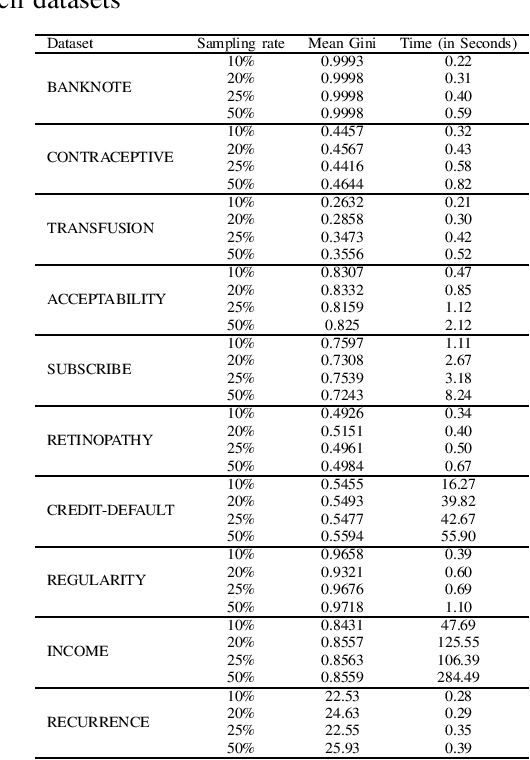
It is already reported in the literature that the performance of a machine learning algorithm is greatly impacted by performing proper Hyper-Parameter optimization. One of the ways to perform Hyper-Parameter optimization is by manual search but that is time consuming. Some of the common approaches for performing Hyper-Parameter optimization are Grid search Random search and Bayesian optimization using Hyperopt. In this paper, we propose a brand new approach for hyperparameter improvement i.e. Randomized-Hyperopt and then tune the hyperparameters of the XGBoost i.e. the Extreme Gradient Boosting algorithm on ten datasets by applying Random search, Randomized-Hyperopt, Hyperopt and Grid Search. The performances of each of these four techniques were compared by taking both the prediction accuracy and the execution time into consideration. We find that the Randomized-Hyperopt performs better than the other three conventional methods for hyper-paramter optimization of XGBoost.
Deep Learning to Address Candidate Generation and Cold Start Challenges in Recommender Systems: A Research Survey
Jul 17, 2019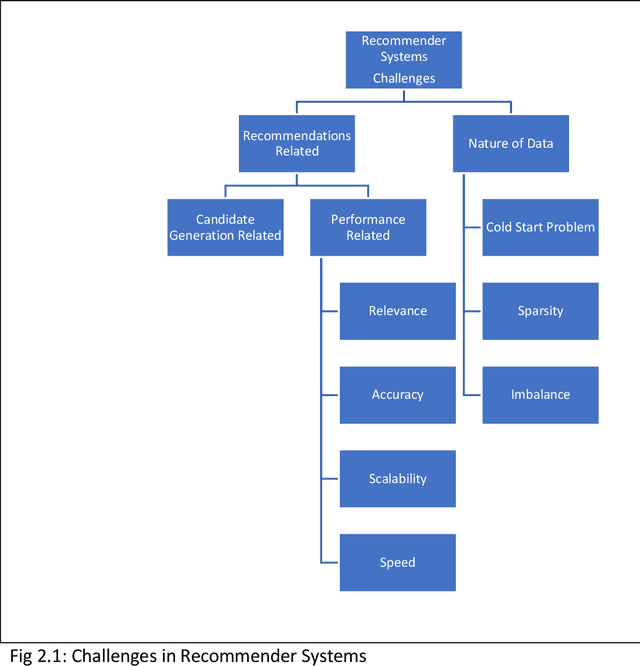
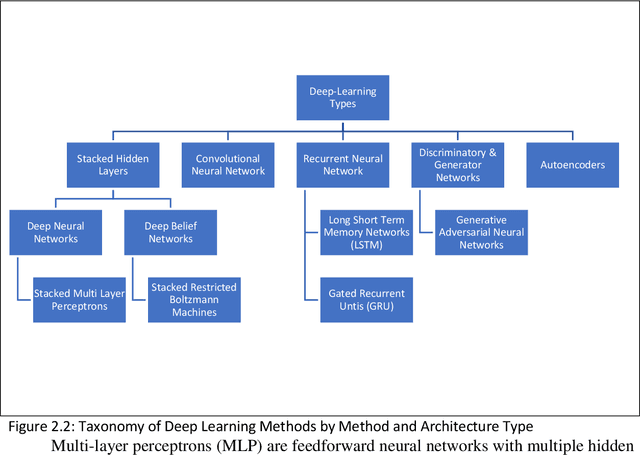
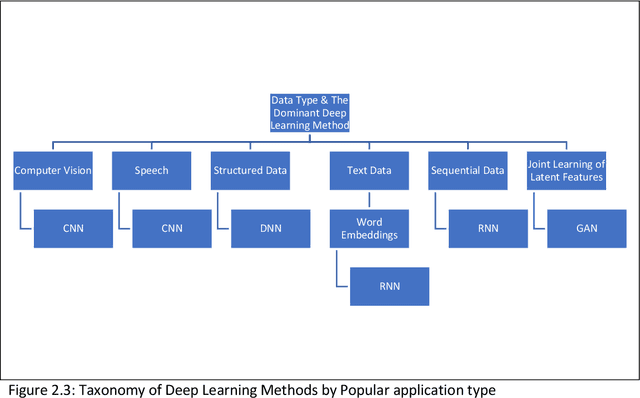
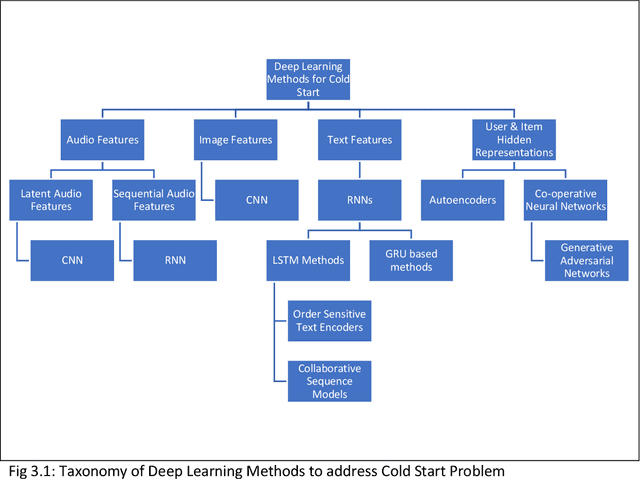
Among the machine learning applications to business, recommender systems would take one of the top places when it comes to success and adoption. They help the user in accelerating the process of search while helping businesses maximize sales. Post phenomenal success in computer vision and speech recognition, deep learning methods are beginning to get applied to recommender systems. Current survey papers on deep learning in recommender systems provide a historical overview and taxonomy of recommender systems based on type. Our paper addresses the gaps of providing a taxonomy of deep learning approaches to address recommender systems problems in the areas of cold start and candidate generation in recommender systems. We outline different challenges in recommender systems into those related to the recommendations themselves (include relevance, speed, accuracy and scalability), those related to the nature of the data (cold start problem, imbalance and sparsity) and candidate generation. We then provide a taxonomy of deep learning techniques to address these challenges. Deep learning techniques are mapped to the different challenges in recommender systems providing an overview of how deep learning techniques can be used to address them. We contribute a taxonomy of deep learning techniques to address the cold start and candidate generation problems in recommender systems. Cold Start is addressed through additional features (for audio, images, text) and by learning hidden user and item representations. Candidate generation has been addressed by separate networks, RNNs, autoencoders and hybrid methods. We also summarize the advantages and limitations of these techniques while outlining areas for future research.