 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Half-Precision for GNN Training
Nov 02, 2024Recent trends in lower precision, e.g. half-precision floating point, training have shown improved system performance and reduced memory usage for Deep Learning while maintaining accuracy. However, current GNN systems cannot achieve such goals for GNN, as our analyses show that they massively underperform while showing abnormal accuracy when using half-precision. These systems suffer from value overflow issues due to lowered precision, under-utilization of hardware resources, and poor training performance. To mitigate this, we introduce HalfGNN, a half-precision based GNN system. HalfGNN proposes novel techniques: new vector operations for half-precision data types that improve data load and reduction performance, and discretized SpMM that overcomes the value overflow and natively provides workload balancing. Such techniques improve hardware utilization, reduce memory usage, and remove atomic writes. Evaluations show that HalfGNN achieves on average of 2.30X speedup in training time over DGL (float-based) for GAT, GCN, and GIN respectively while achieving similar accuracy, and saving 2.67X memory.
GNNBENCH: Fair and Productive Benchmarking for Single-GPU GNN System
Apr 05, 2024We hypothesize that the absence of a standardized benchmark has allowed several fundamental pitfalls in GNN System design and evaluation that the community has overlooked. In this work, we propose GNNBench, a plug-and-play benchmarking platform focused on system innovation. GNNBench presents a new protocol to exchange their captive tensor data, supports custom classes in System APIs, and allows automatic integration of the same system module to many deep learning frameworks, such as PyTorch and TensorFlow. To demonstrate the importance of such a benchmark framework, we integrated several GNN systems. Our results show that integration with GNNBench helped us identify several measurement issues that deserve attention from the community.
Single-GPU GNN Systems: Traps and Pitfalls
Feb 05, 2024The current graph neural network (GNN) systems have established a clear trend of not showing training accuracy results, and directly or indirectly relying on smaller datasets for evaluations majorly. Our in-depth analysis shows that it leads to a chain of pitfalls in the system design and evaluation process, questioning the practicality of many of the proposed system optimizations, and affecting conclusions and lessons learned. We analyze many single-GPU systems and show the fundamental impact of these pitfalls. We further develop hypotheses, recommendations, and evaluation methodologies, and provide future directions. Finally, a new reference system is developed to establish a new line of optimizations rooted in solving the system-design pitfalls efficiently and practically. The proposed design can productively be integrated into prior works, thereby truly advancing the state-of-the-art.
Weakly supervised information extraction from inscrutable handwritten document images
Jun 12, 2023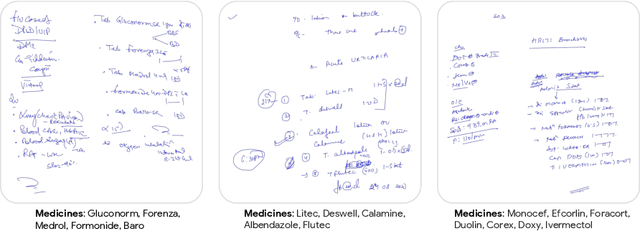

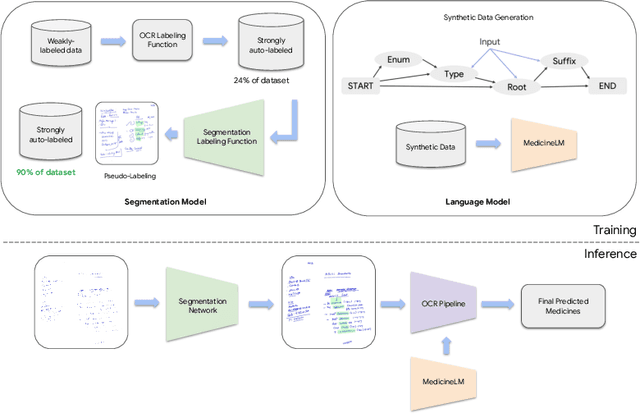
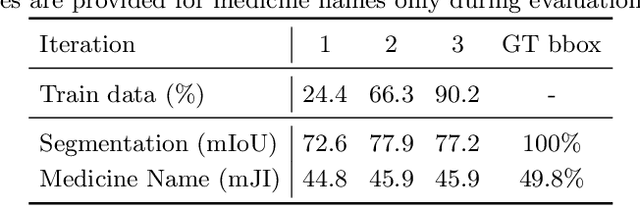
State-of-the-art information extraction methods are limited by OCR errors. They work well for printed text in form-like documents, but unstructured, handwritten documents still remain a challenge. Adapting existing models to domain-specific training data is quite expensive, because of two factors, 1) limited availability of the domain-specific documents (such as handwritten prescriptions, lab notes, etc.), and 2) annotations become even more challenging as one needs domain-specific knowledge to decode inscrutable handwritten document images. In this work, we focus on the complex problem of extracting medicine names from handwritten prescriptions using only weakly labeled data. The data consists of images along with the list of medicine names in it, but not their location in the image. We solve the problem by first identifying the regions of interest, i.e., medicine lines from just weak labels and then injecting a domain-specific medicine language model learned using only synthetically generated data. Compared to off-the-shelf state-of-the-art methods, our approach performs >2.5x better in medicine names extraction from prescriptions.
Deep Learning to Address Candidate Generation and Cold Start Challenges in Recommender Systems: A Research Survey
Jul 17, 2019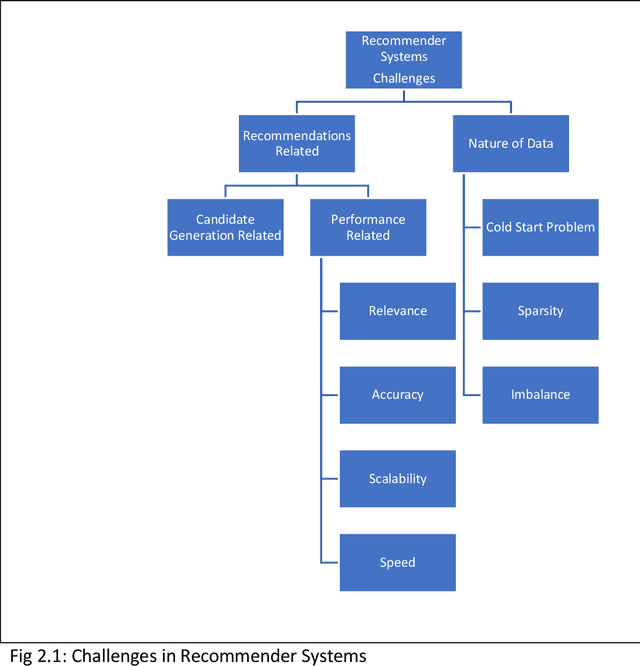
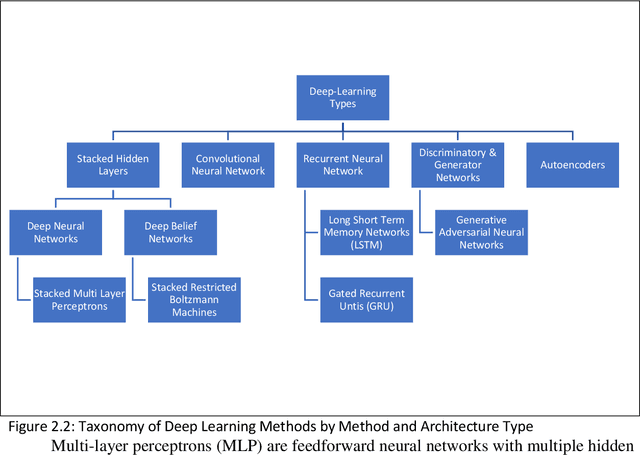
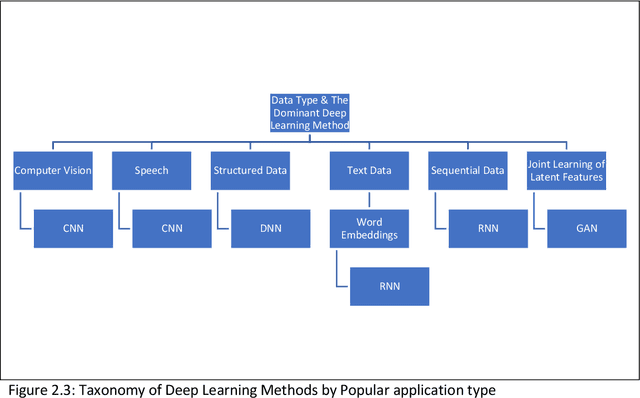
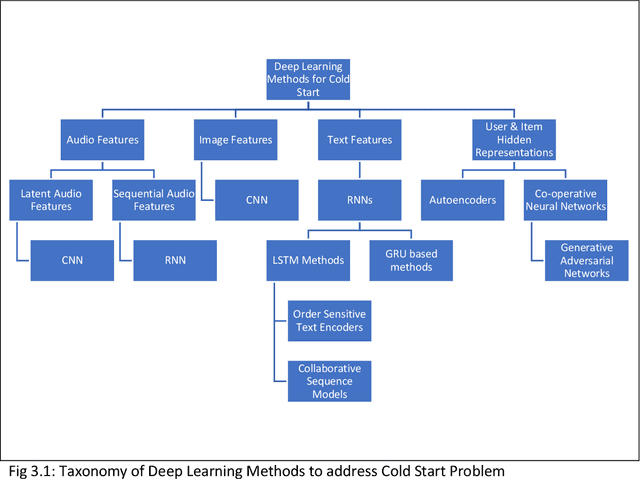
Among the machine learning applications to business, recommender systems would take one of the top places when it comes to success and adoption. They help the user in accelerating the process of search while helping businesses maximize sales. Post phenomenal success in computer vision and speech recognition, deep learning methods are beginning to get applied to recommender systems. Current survey papers on deep learning in recommender systems provide a historical overview and taxonomy of recommender systems based on type. Our paper addresses the gaps of providing a taxonomy of deep learning approaches to address recommender systems problems in the areas of cold start and candidate generation in recommender systems. We outline different challenges in recommender systems into those related to the recommendations themselves (include relevance, speed, accuracy and scalability), those related to the nature of the data (cold start problem, imbalance and sparsity) and candidate generation. We then provide a taxonomy of deep learning techniques to address these challenges. Deep learning techniques are mapped to the different challenges in recommender systems providing an overview of how deep learning techniques can be used to address them. We contribute a taxonomy of deep learning techniques to address the cold start and candidate generation problems in recommender systems. Cold Start is addressed through additional features (for audio, images, text) and by learning hidden user and item representations. Candidate generation has been addressed by separate networks, RNNs, autoencoders and hybrid methods. We also summarize the advantages and limitations of these techniques while outlining areas for future research.