 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained large-scale content recommendations for MSX sellers
Jul 09, 2024



One of the most critical tasks of Microsoft sellers is to meticulously track and nurture potential business opportunities through proactive engagement and tailored solutions. Recommender systems play a central role to help sellers achieve their goals. In this paper, we present a content recommendation model which surfaces various types of content (technical documentation, comparison with competitor products, customer success stories etc.) that sellers can share with their customers or use for their own self-learning. The model operates at the opportunity level which is the lowest possible granularity and the most relevant one for sellers. It is based on semantic matching between metadata from the contents and carefully selected attributes of the opportunities. Considering the volume of seller-managed opportunities in organizations such as Microsoft, we show how to perform efficient semantic matching over a very large number of opportunity-content combinations. The main challenge is to ensure that the top-5 relevant contents for each opportunity are recommended out of a total of $\approx 40,000$ published contents. We achieve this target through an extensive comparison of different model architectures and feature selection. Finally, we further examine the quality of the recommendations in a quantitative manner using a combination of human domain experts as well as by using the recently proposed "LLM as a judge" framework.
A case study of Generative AI in MSX Sales Copilot: Improving seller productivity with a real-time question-answering system for content recommendation
Jan 04, 2024In this paper, we design a real-time question-answering system specifically targeted for helping sellers get relevant material/documentation they can share live with their customers or refer to during a call. Taking the Seismic content repository as a relatively large scale example of a diverse dataset of sales material, we demonstrate how LLM embeddings of sellers' queries can be matched with the relevant content. We achieve this by engineering prompts in an elaborate fashion that makes use of the rich set of meta-features available for documents and sellers. Using a bi-encoder with cross-encoder re-ranker architecture, we show how the solution returns the most relevant content recommendations in just a few seconds even for large datasets. Our recommender system is deployed as an AML endpoint for real-time inferencing and has been integrated into a Copilot interface that is now deployed in the production version of the Dynamics CRM, known as MSX, used daily by Microsoft sellers.
Adaptive Granularity in Tensors: A Quest for Interpretable Structure
Dec 19, 2019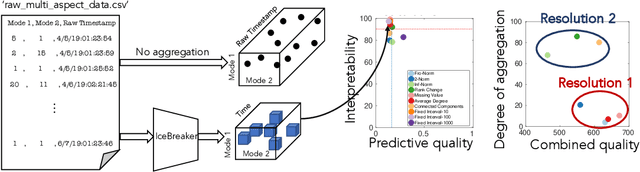

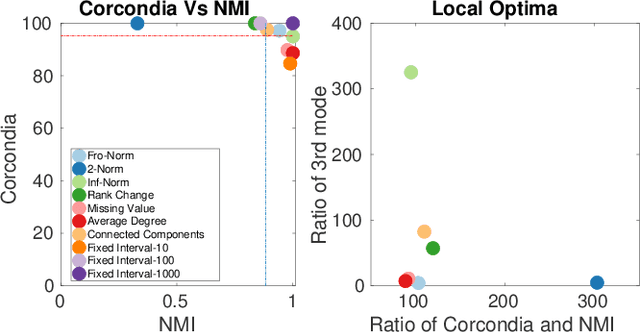
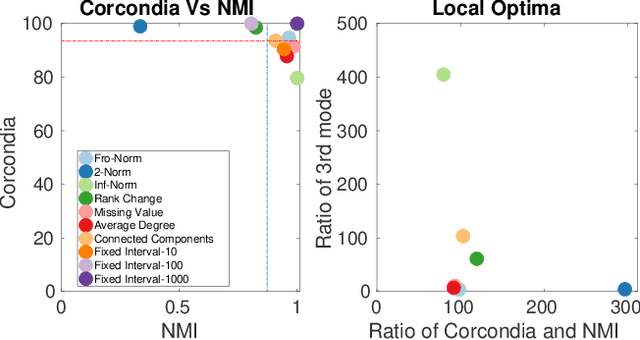
Data collected at very frequent intervals is usually extremely sparse and has no structure that is exploitable by modern tensor decomposition algorithms. Thus the utility of such tensors is low, in terms of the amount of interpretable and exploitable structure that one can extract from them. In this paper, we introduce the problem of finding a tensor of adaptive aggregated granularity that can be decomposed to reveal meaningful latent concepts (structures) from datasets that, in their original form, are not amenable to tensor analysis. Such datasets fall under the broad category of sparse point processes that evolve over space and/or time. To the best of our knowledge, this is the first work that explores adaptive granularity aggregation in tensors. Furthermore, we formally define the problem and discuss what different definitions of "good structure" can be in practice, and show that optimal solution is of prohibitive combinatorial complexity. Subsequently, we propose an efficient and effective greedy algorithm which follows a number of intuitive decision criteria that locally maximize the "goodness of structure", resulting in high-quality tensors. We evaluate our method on both semi-synthetic data where ground truth is known and real datasets for which we do not have any ground truth. In both cases, our proposed method constructs tensors that have very high structure quality. Finally, our proposed method is able to discover different natural resolutions of a multi-aspect dataset, which can lead to multi-resolution analysis.
OCTen: Online Compression-based Tensor Decomposition
Jul 03, 2018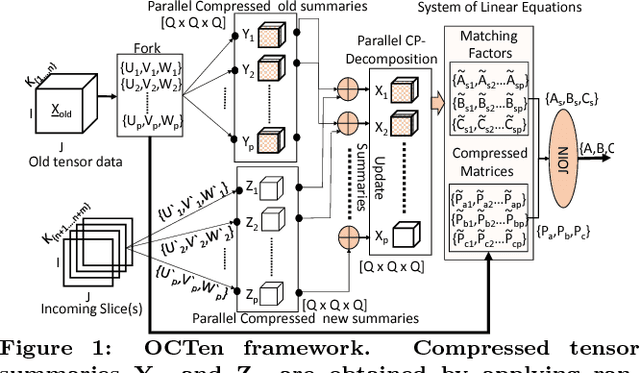

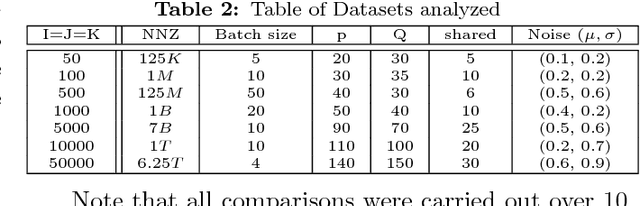
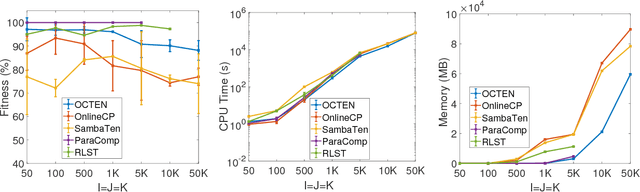
Tensor decompositions are powerful tools for large data analytics as they jointly model multiple aspects of data into one framework and enable the discovery of the latent structures and higher-order correlations within the data. One of the most widely studied and used decompositions, especially in data mining and machine learning, is the Canonical Polyadic or CP decomposition. However, today's datasets are not static and these datasets often dynamically growing and changing with time. To operate on such large data, we present OCTen the first ever compression-based online parallel implementation for the CP decomposition. We conduct an extensive empirical analysis of the algorithms in terms of fitness, memory used and CPU time, and in order to demonstrate the compression and scalability of the method, we apply OCTen to big tensor data. Indicatively, OCTen performs on-par or better than state-of-the-art online and online methods in terms of decomposition accuracy and efficiency, while saving up to 40-200 % memory space.
Identifying and Alleviating Concept Drift in Streaming Tensor Decomposition
Apr 25, 2018
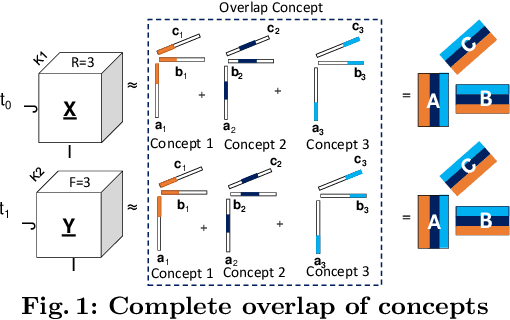
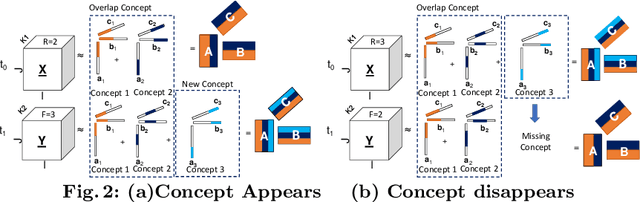
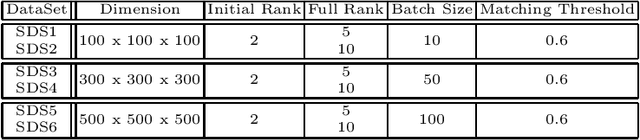
Tensor decompositions are used in various data mining applications from social network to medical applications and are extremely useful in discovering latent structures or concepts in the data. Many real-world applications are dynamic in nature and so are their data. To deal with this dynamic nature of data, there exist a variety of online tensor decomposition algorithms. A central assumption in all those algorithms is that the number of latent concepts remains fixed throughout the en- tire stream. However, this need not be the case. Every incoming batch in the stream may have a different number of latent concepts, and the difference in latent concepts from one tensor batch to another can provide insights into how our findings in a particular application behave and deviate over time. In this paper, we define "concept" and "concept drift" in the context of streaming tensor decomposition, as the manifestation of the variability of latent concepts throughout the stream. Furthermore, we introduce SeekAndDestroy, an algorithm that detects concept drift in streaming tensor decomposition and is able to produce results robust to that drift. To the best of our knowledge, this is the first work that investigates concept drift in streaming tensor decomposition. We extensively evaluate SeekAndDestroy on synthetic datasets, which exhibit a wide variety of realistic drift. Our experiments demonstrate the effectiveness of SeekAndDestroy, both in the detection of concept drift and in the alleviation of its effects, producing results with similar quality to decomposing the entire tensor in one shot. Additionally, in real datasets, SeekAndDestroy outperforms other streaming baselines, while discovering novel useful components.