 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPR: Leveraging LLMs for Topic and Phrase Suggestion to Facilitate Comprehensive Product Reviews
Apr 18, 2025Consumers often heavily rely on online product reviews, analyzing both quantitative ratings and textual descriptions to assess product quality. However, existing research hasn't adequately addressed how to systematically encourage the creation of comprehensive reviews that capture both customers sentiment and detailed product feature analysis. This paper presents CPR, a novel methodology that leverages the power of Large Language Models (LLMs) and Topic Modeling to guide users in crafting insightful and well-rounded reviews. Our approach employs a three-stage process: first, we present users with product-specific terms for rating; second, we generate targeted phrase suggestions based on these ratings; and third, we integrate user-written text through topic modeling, ensuring all key aspects are addressed. We evaluate CPR using text-to-text LLMs, comparing its performance against real-world customer reviews from Walmart. Our results demonstrate that CPR effectively identifies relevant product terms, even for new products lacking prior reviews, and provides sentiment-aligned phrase suggestions, saving users time and enhancing reviews quality. Quantitative analysis reveals a 12.3% improvement in BLEU score over baseline methods, further supported by manual evaluation of generated phrases. We conclude by discussing potential extensions and future research directions.
PAE: LLM-based Product Attribute Extraction for E-Commerce Fashion Trends
May 27, 2024
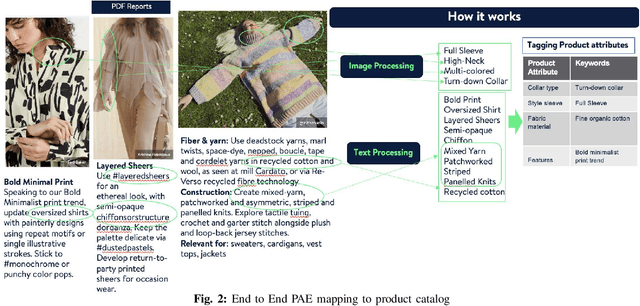
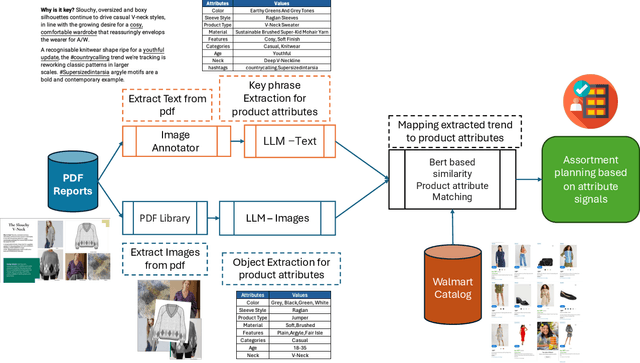

Product attribute extraction is an growing field in e-commerce business, with several applications including product ranking, product recommendation, future assortment planning and improving online shopping customer experiences. Understanding the customer needs is critical part of online business, specifically fashion products. Retailers uses assortment planning to determine the mix of products to offer in each store and channel, stay responsive to market dynamics and to manage inventory and catalogs. The goal is to offer the right styles, in the right sizes and colors, through the right channels. When shoppers find products that meet their needs and desires, they are more likely to return for future purchases, fostering customer loyalty. Product attributes are a key factor in assortment planning. In this paper we present PAE, a product attribute extraction algorithm for future trend reports consisting text and images in PDF format. Most existing methods focus on attribute extraction from titles or product descriptions or utilize visual information from existing product images. Compared to the prior works, our work focuses on attribute extraction from PDF files where upcoming fashion trends are explained. This work proposes a more comprehensive framework that fully utilizes the different modalities for attribute extraction and help retailers to plan the assortment in advance. Our contributions are three-fold: (a) We develop PAE, an efficient framework to extract attributes from unstructured data (text and images); (b) We provide catalog matching methodology based on BERT representations to discover the existing attributes using upcoming attribute values; (c) We conduct extensive experiments with several baselines and show that PAE is an effective, flexible and on par or superior (avg 92.5% F1-Score) framework to existing state-of-the-art for attribute value extraction task.
Modeling and Mining Multi-Aspect Graphs With Scalable Streaming Tensor Decomposition
Oct 10, 2022Graphs emerge in almost every real-world application domain, ranging from online social networks all the way to health data and movie viewership patterns. Typically, such real-world graphs are big and dynamic, in the sense that they evolve over time. Furthermore, graphs usually contain multi-aspect information i.e. in a social network, we can have the "means of communication" between nodes, such as who messages whom, who calls whom, and who comments on whose timeline and so on. How can we model and mine useful patterns, such as communities of nodes in that graph, from such multi-aspect graphs? How can we identify dynamic patterns in those graphs, and how can we deal with streaming data, when the volume of data to be processed is very large? In order to answer those questions, in this thesis, we propose novel tensor-based methods for mining static and dynamic multi-aspect graphs. In general, a tensor is a higher-order generalization of a matrix that can represent high-dimensional multi-aspect data such as time-evolving networks, collaboration networks, and spatio-temporal data like Electroencephalography (EEG) brain measurements. The thesis is organized in two synergistic thrusts: First, we focus on static multi-aspect graphs, where the goal is to identify coherent communities and patterns between nodes by leveraging the tensor structure in the data. Second, as our graphs evolve dynamically, we focus on handling such streaming updates in the data without having to re-compute the decomposition, but incrementally update the existing results.
Adaptive Granularity in Tensors: A Quest for Interpretable Structure
Dec 19, 2019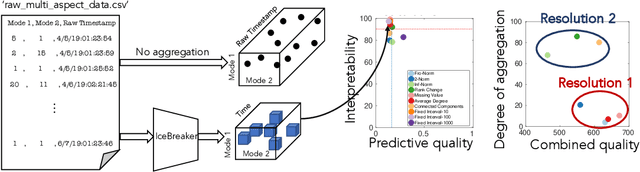

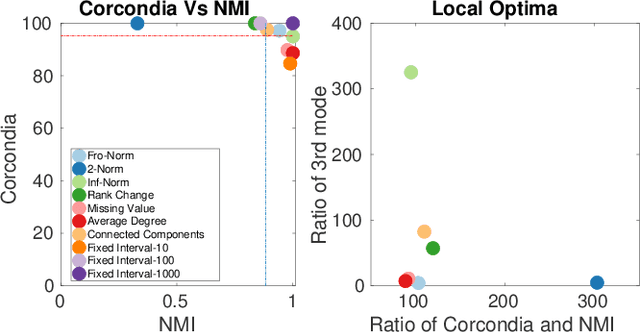
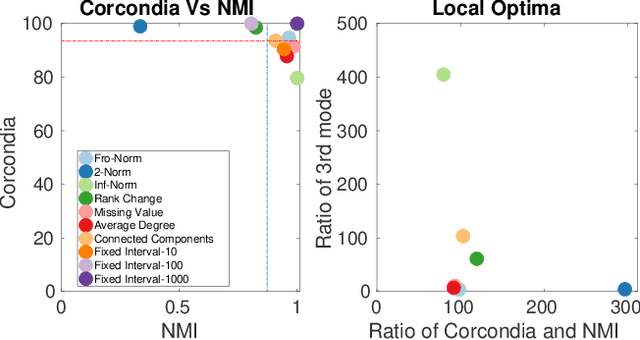
Data collected at very frequent intervals is usually extremely sparse and has no structure that is exploitable by modern tensor decomposition algorithms. Thus the utility of such tensors is low, in terms of the amount of interpretable and exploitable structure that one can extract from them. In this paper, we introduce the problem of finding a tensor of adaptive aggregated granularity that can be decomposed to reveal meaningful latent concepts (structures) from datasets that, in their original form, are not amenable to tensor analysis. Such datasets fall under the broad category of sparse point processes that evolve over space and/or time. To the best of our knowledge, this is the first work that explores adaptive granularity aggregation in tensors. Furthermore, we formally define the problem and discuss what different definitions of "good structure" can be in practice, and show that optimal solution is of prohibitive combinatorial complexity. Subsequently, we propose an efficient and effective greedy algorithm which follows a number of intuitive decision criteria that locally maximize the "goodness of structure", resulting in high-quality tensors. We evaluate our method on both semi-synthetic data where ground truth is known and real datasets for which we do not have any ground truth. In both cases, our proposed method constructs tensors that have very high structure quality. Finally, our proposed method is able to discover different natural resolutions of a multi-aspect dataset, which can lead to multi-resolution analysis.
OCTen: Online Compression-based Tensor Decomposition
Jul 03, 2018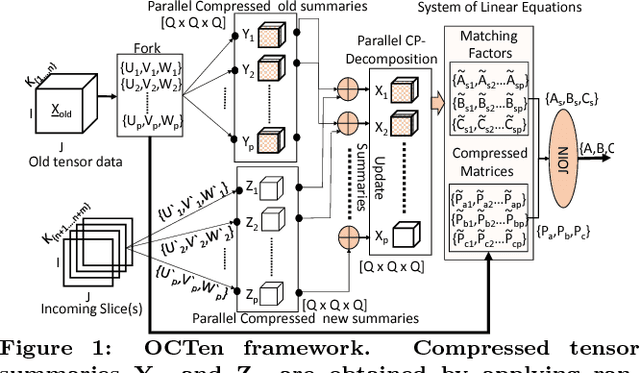

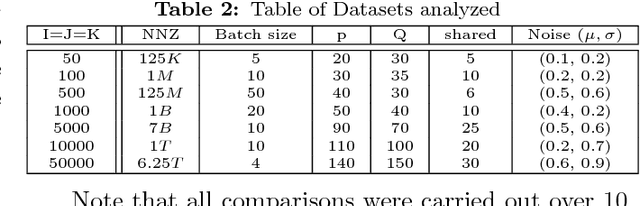
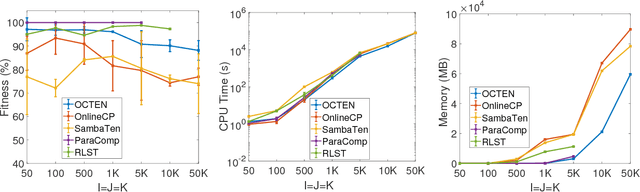
Tensor decompositions are powerful tools for large data analytics as they jointly model multiple aspects of data into one framework and enable the discovery of the latent structures and higher-order correlations within the data. One of the most widely studied and used decompositions, especially in data mining and machine learning, is the Canonical Polyadic or CP decomposition. However, today's datasets are not static and these datasets often dynamically growing and changing with time. To operate on such large data, we present OCTen the first ever compression-based online parallel implementation for the CP decomposition. We conduct an extensive empirical analysis of the algorithms in terms of fitness, memory used and CPU time, and in order to demonstrate the compression and scalability of the method, we apply OCTen to big tensor data. Indicatively, OCTen performs on-par or better than state-of-the-art online and online methods in terms of decomposition accuracy and efficiency, while saving up to 40-200 % memory space.
t-PINE: Tensor-based Predictable and Interpretable Node Embeddings
May 03, 2018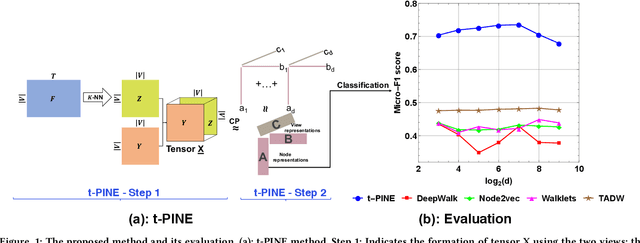

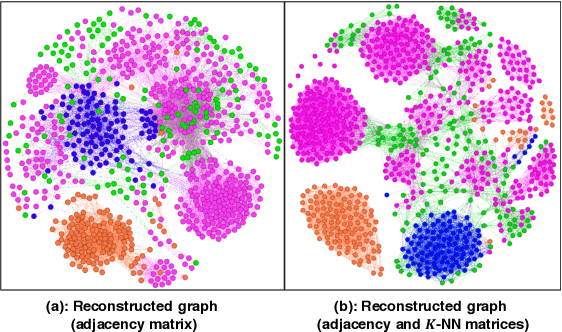
Graph representations have increasingly grown in popularity during the last years. Existing representation learning approaches explicitly encode network structure. Despite their good performance in downstream processes (e.g., node classification, link prediction), there is still room for improvement in different aspects, like efficacy, visualization, and interpretability. In this paper, we propose, t-PINE, a method that addresses these limitations. Contrary to baseline methods, which generally learn explicit graph representations by solely using an adjacency matrix, t-PINE avails a multi-view information graph, the adjacency matrix represents the first view, and a nearest neighbor adjacency, computed over the node features, is the second view, in order to learn explicit and implicit node representations, using the Canonical Polyadic (a.k.a. CP) decomposition. We argue that the implicit and the explicit mapping from a higher-dimensional to a lower-dimensional vector space is the key to learn more useful, highly predictable, and gracefully interpretable representations. Having good interpretable representations provides a good guidance to understand how each view contributes to the representation learning process. In addition, it helps us to exclude unrelated dimensions. Extensive experiments show that t-PINE drastically outperforms baseline methods by up to 158.6% with respect to Micro-F1, in several multi-label classification problems, while it has high visualization and interpretability utility.
Identifying and Alleviating Concept Drift in Streaming Tensor Decomposition
Apr 25, 2018
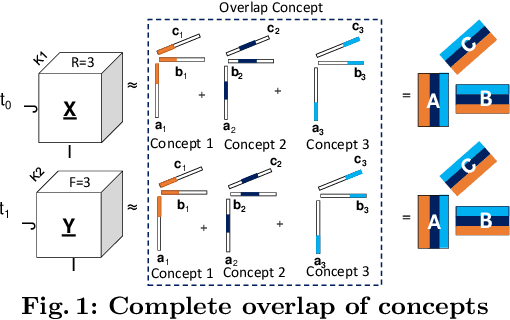
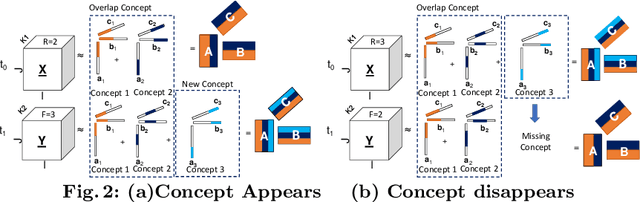
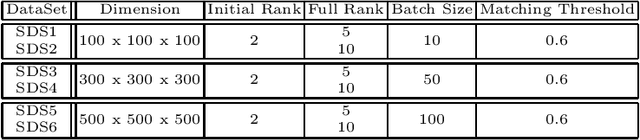
Tensor decompositions are used in various data mining applications from social network to medical applications and are extremely useful in discovering latent structures or concepts in the data. Many real-world applications are dynamic in nature and so are their data. To deal with this dynamic nature of data, there exist a variety of online tensor decomposition algorithms. A central assumption in all those algorithms is that the number of latent concepts remains fixed throughout the en- tire stream. However, this need not be the case. Every incoming batch in the stream may have a different number of latent concepts, and the difference in latent concepts from one tensor batch to another can provide insights into how our findings in a particular application behave and deviate over time. In this paper, we define "concept" and "concept drift" in the context of streaming tensor decomposition, as the manifestation of the variability of latent concepts throughout the stream. Furthermore, we introduce SeekAndDestroy, an algorithm that detects concept drift in streaming tensor decomposition and is able to produce results robust to that drift. To the best of our knowledge, this is the first work that investigates concept drift in streaming tensor decomposition. We extensively evaluate SeekAndDestroy on synthetic datasets, which exhibit a wide variety of realistic drift. Our experiments demonstrate the effectiveness of SeekAndDestroy, both in the detection of concept drift and in the alleviation of its effects, producing results with similar quality to decomposing the entire tensor in one shot. Additionally, in real datasets, SeekAndDestroy outperforms other streaming baselines, while discovering novel useful components.