 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTPV: Parameter Perturbations Through the Lens of Test Prediction Variance
Dec 11, 2025We identify test prediction variance (TPV) -- the first-order sensitivity of model outputs to parameter perturbations around a trained solution -- as a unifying quantity that links several classical observations about generalization in deep networks. TPV is a fully label-free object whose trace form separates the geometry of the trained model from the specific perturbation mechanism, allowing a broad family of parameter perturbations like SGD noise, label noise, finite-precision noise, and other post-training perturbations to be analyzed under a single framework. Theoretically, we show that TPV estimated on the training set converges to its test-set value in the overparameterized limit, providing the first result that prediction variance under local parameter perturbations can be inferred from training inputs alone. Empirically, TPV exhibits a striking stability across datasets and architectures -- including extremely narrow networks -- and correlates well with clean test loss. Finally, we demonstrate that modeling pruning as a TPV perturbation yields a simple label-free importance measure that performs competitively with state-of-the-art pruning methods, illustrating the practical utility of TPV. Code available at github.com/devansharpit/TPV.
Causal Layering via Conditional Entropy
Jan 19, 2024Causal discovery aims to recover information about an unobserved causal graph from the observable data it generates. Layerings are orderings of the variables which place causes before effects. In this paper, we provide ways to recover layerings of a graph by accessing the data via a conditional entropy oracle, when distributions are discrete. Our algorithms work by repeatedly removing sources or sinks from the graph. Under appropriate assumptions and conditioning, we can separate the sources or sinks from the remainder of the nodes by comparing their conditional entropy to the unconditional entropy of their noise. Our algorithms are provably correct and run in worst-case quadratic time. The main assumptions are faithfulness and injective noise, and either known noise entropies or weakly monotonically increasing noise entropies along directed paths. In addition, we require one of either a very mild extension of faithfulness, or strictly monotonically increasing noise entropies, or expanding noise injectivity to include an additional single argument in the structural functions.
Editing Arbitrary Propositions in LLMs without Subject Labels
Jan 15, 2024Large Language Model (LLM) editing modifies factual information in LLMs. Locate-and-Edit (L\&E) methods accomplish this by finding where relevant information is stored within the neural network, and editing the weights at that location. The goal of editing is to modify the response of an LLM to a proposition independently of its phrasing, while not modifying its response to other related propositions. Existing methods are limited to binary propositions, which represent straightforward binary relations between a subject and an object. Furthermore, existing methods rely on semantic subject labels, which may not be available or even be well-defined in practice. In this paper, we show that both of these issues can be effectively skirted with a simple and fast localization method called Gradient Tracing (GT). This localization method allows editing arbitrary propositions instead of just binary ones, and does so without the need for subject labels. As propositions always have a truth value, our experiments prompt an LLM as a boolean classifier, and edit its T/F response to propositions. Our method applies GT for location tracing, and then edit the model at that location using a mild variant of Rank-One Model Editing (ROME). On datasets of binary propositions derived from the CounterFact dataset, we show that our method -- without access to subject labels -- performs close to state-of-the-art L\&E methods which has access subject labels. We then introduce a new dataset, Factual Accuracy Classification Test (FACT), which includes non-binary propositions and for which subject labels are not generally applicable, and therefore is beyond the scope of existing L\&E methods. Nevertheless, we show that with our method editing is possible on FACT.
BOLAA: Benchmarking and Orchestrating LLM-augmented Autonomous Agents
Aug 11, 2023The massive successes of large language models (LLMs) encourage the emerging exploration of LLM-augmented Autonomous Agents (LAAs). An LAA is able to generate actions with its core LLM and interact with environments, which facilitates the ability to resolve complex tasks by conditioning on past interactions such as observations and actions. Since the investigation of LAA is still very recent, limited explorations are available. Therefore, we provide a comprehensive comparison of LAA in terms of both agent architectures and LLM backbones. Additionally, we propose a new strategy to orchestrate multiple LAAs such that each labor LAA focuses on one type of action, \textit{i.e.} BOLAA, where a controller manages the communication among multiple agents. We conduct simulations on both decision-making and multi-step reasoning environments, which comprehensively justify the capacity of LAAs. Our performance results provide quantitative suggestions for designing LAA architectures and the optimal choice of LLMs, as well as the compatibility of both. We release our implementation code of LAAs to the public at \url{https://github.com/salesforce/BOLAA}.
Retroformer: Retrospective Large Language Agents with Policy Gradient Optimization
Aug 04, 2023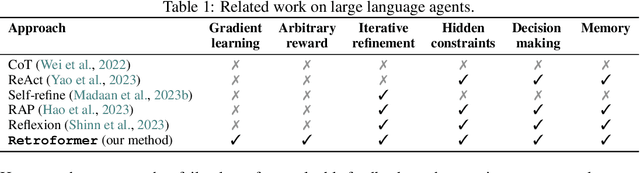
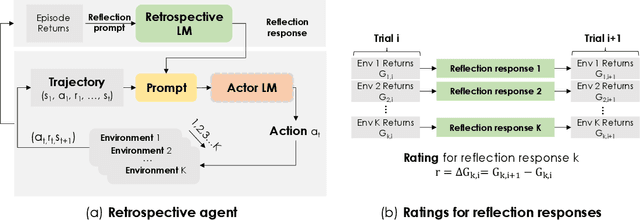
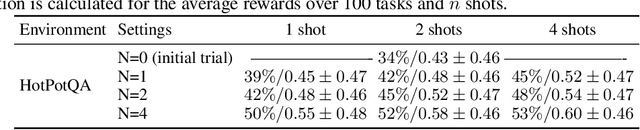
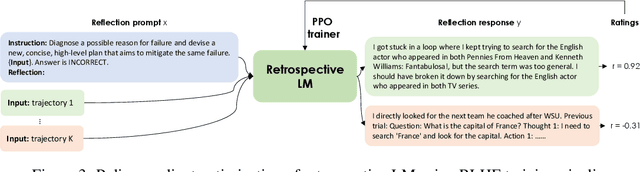
Recent months have seen the emergence of a powerful new trend in which large language models (LLMs) are augmented to become autonomous language agents capable of performing objective oriented multi-step tasks on their own, rather than merely responding to queries from human users. Most existing language agents, however, are not optimized using environment-specific rewards. Although some agents enable iterative refinement through verbal feedback, they do not reason and plan in ways that are compatible with gradient-based learning from rewards. This paper introduces a principled framework for reinforcing large language agents by learning a retrospective model, which automatically tunes the language agent prompts from environment feedback through policy gradient. Specifically, our proposed agent architecture learns from rewards across multiple environments and tasks, for fine-tuning a pre-trained language model which refines the language agent prompt by summarizing the root cause of prior failed attempts and proposing action plans. Experimental results on various tasks demonstrate that the language agents improve over time and that our approach considerably outperforms baselines that do not properly leverage gradients from the environment. This demonstrates that using policy gradient optimization to improve language agents, for which we believe our work is one of the first, seems promising and can be applied to optimize other models in the agent architecture to enhance agent performances over time.
REX: Rapid Exploration and eXploitation for AI Agents
Jul 18, 2023



In this paper, we propose an enhanced approach for Rapid Exploration and eXploitation for AI Agents called REX. Existing AutoGPT-style techniques have inherent limitations, such as a heavy reliance on precise descriptions for decision-making, and the lack of a systematic approach to leverage try-and-fail procedures akin to traditional Reinforcement Learning (RL). REX introduces an additional layer of rewards and integrates concepts similar to Upper Confidence Bound (UCB) scores, leading to more robust and efficient AI agent performance. This approach has the advantage of enabling the utilization of offline behaviors from logs and allowing seamless integration with existing foundation models while it does not require any model fine-tuning. Through comparative analysis with existing methods such as Chain-of-Thoughts(CoT) and Reasoning viA Planning(RAP), REX-based methods demonstrate comparable performance and, in certain cases, even surpass the results achieved by these existing techniques. Notably, REX-based methods exhibit remarkable reductions in execution time, enhancing their practical applicability across a diverse set of scenarios.
On the Unlikelihood of D-Separation
Mar 10, 2023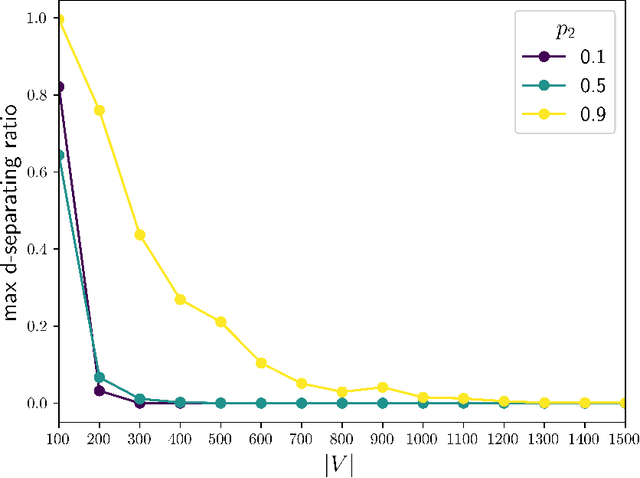
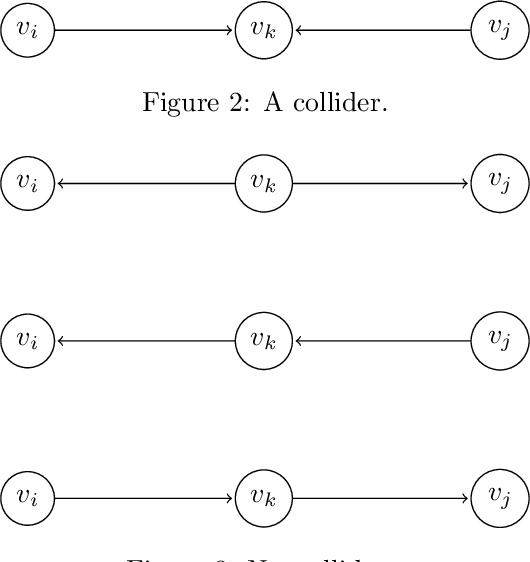
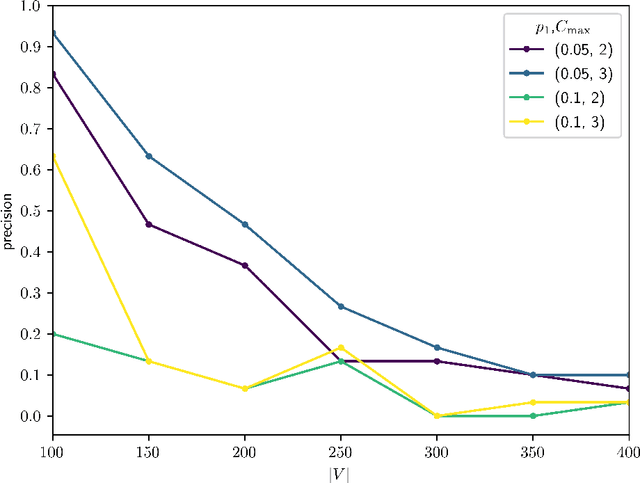
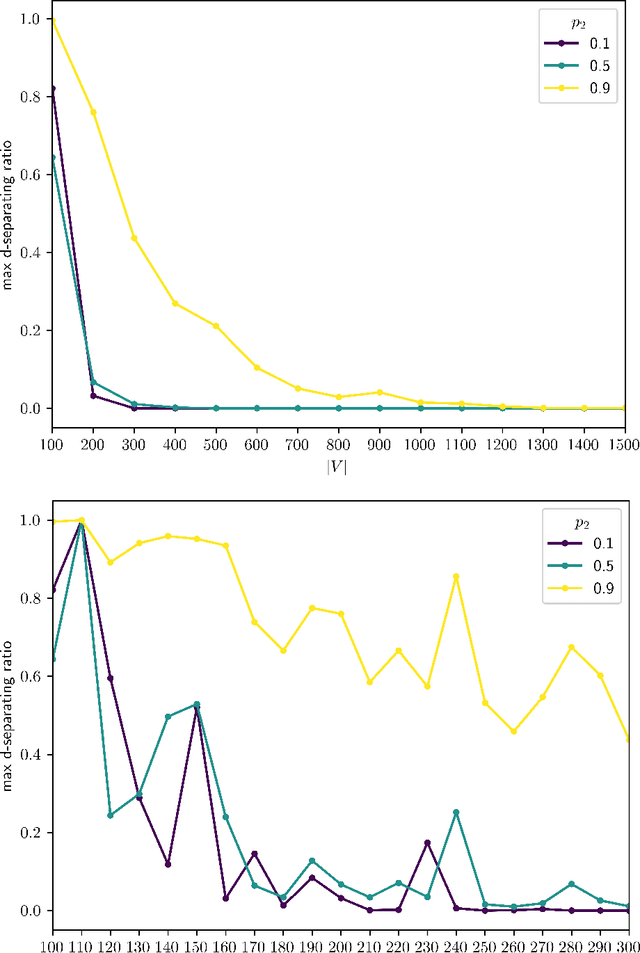
Causal discovery aims to recover a causal graph from data generated by it; constraint based methods do so by searching for a d-separating conditioning set of nodes in the graph via an oracle. In this paper, we provide analytic evidence that on large graphs, d-separation is a rare phenomenon, even when guaranteed to exist, unless the graph is extremely sparse. We then provide an analytic average case analysis of the PC Algorithm for causal discovery, as well as a variant of the SGS Algorithm we call UniformSGS. We consider a set $V=\{v_1,\ldots,v_n\}$ of nodes, and generate a random DAG $G=(V,E)$ where $(v_a, v_b) \in E$ with i.i.d. probability $p_1$ if $a<b$ and $0$ if $a > b$. We provide upper bounds on the probability that a subset of $V-\{x,y\}$ d-separates $x$ and $y$, conditional on $x$ and $y$ being d-separable; our upper bounds decay exponentially fast to $0$ as $|V| \rightarrow \infty$. For the PC Algorithm, while it is known that its worst-case guarantees fail on non-sparse graphs, we show that the same is true for the average case, and that the sparsity requirement is quite demanding: for good performance, the density must go to $0$ as $|V| \rightarrow \infty$ even in the average case. For UniformSGS, while it is known that the running time is exponential for existing edges, we show that in the average case, that is the expected running time for most non-existing edges as well.
Salesforce CausalAI Library: A Fast and Scalable Framework for Causal Analysis of Time Series and Tabular Data
Jan 25, 2023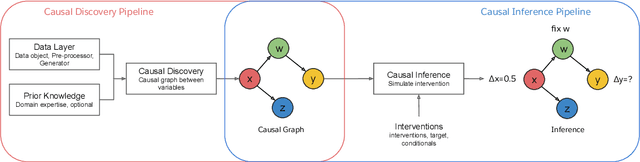

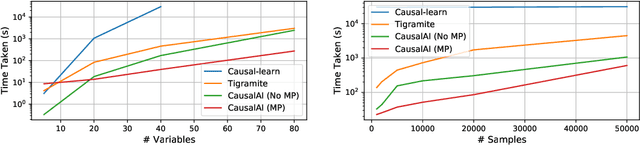
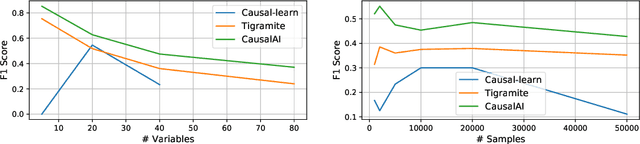
We introduce the Salesforce CausalAI Library, an open-source library for causal analysis using observational data. It supports causal discovery and causal inference for tabular and time series data, of both discrete and continuous types. This library includes algorithms that handle linear and non-linear causal relationships between variables, and uses multi-processing for speed-up. We also include a data generator capable of generating synthetic data with specified structural equation model for both the aforementioned data formats and types, that helps users control the ground-truth causal process while investigating various algorithms. Finally, we provide a user interface (UI) that allows users to perform causal analysis on data without coding. The goal of this library is to provide a fast and flexible solution for a variety of problems in the domain of causality. This technical report describes the Salesforce CausalAI API along with its capabilities, the implementations of the supported algorithms, and experiments demonstrating their performance and speed. Our library is available at \url{https://github.com/salesforce/causalai}.
Ensemble of Averages: Improving Model Selection and Boosting Performance in Domain Generalization
Oct 26, 2021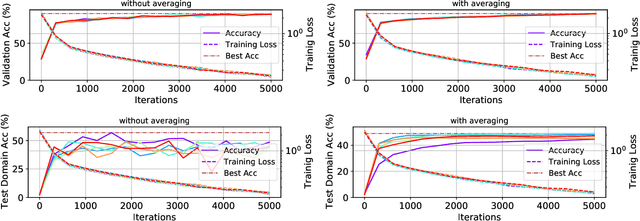
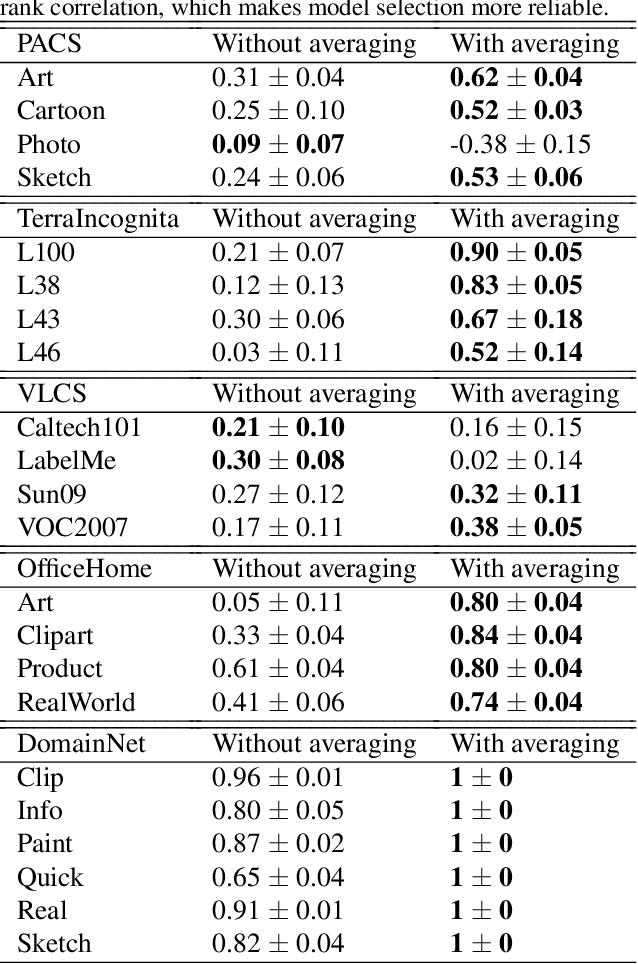

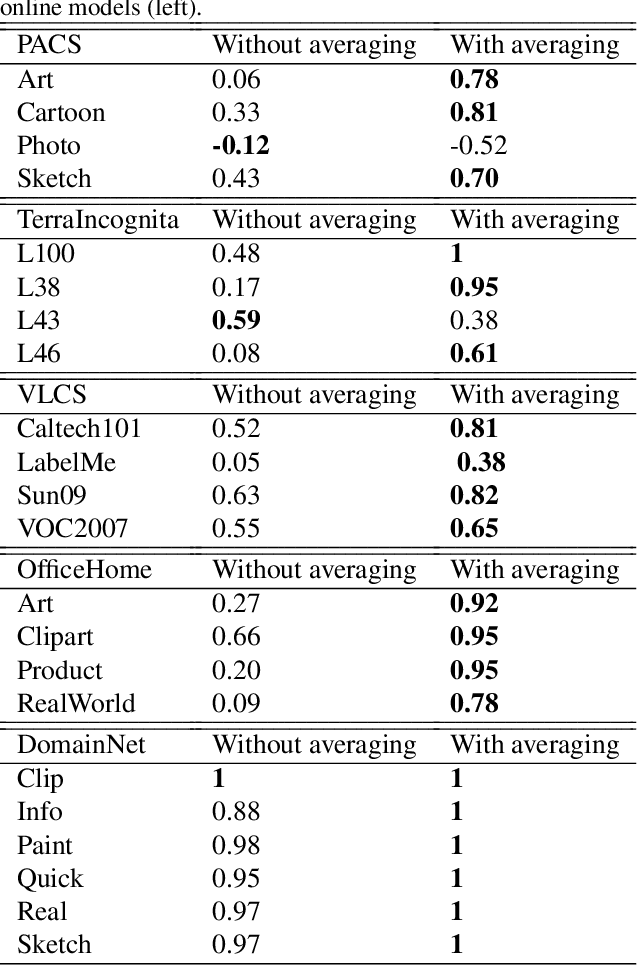
In Domain Generalization (DG) settings, models trained on a given set of training domains have notoriously chaotic performance on distribution shifted test domains, and stochasticity in optimization (e.g. seed) plays a big role. This makes deep learning models unreliable in real world settings. We first show that a simple protocol for averaging model parameters along the optimization path, starting early during training, both significantly boosts domain generalization and diminishes the impact of stochasticity by improving the rank correlation between the in-domain validation accuracy and out-domain test accuracy, which is crucial for reliable model selection. Next, we show that an ensemble of independently trained models also has a chaotic behavior in the DG setting. Taking advantage of our observation, we show that instead of ensembling unaveraged models, ensembling moving average models (EoA) from different runs does increase stability and further boosts performance. On the DomainBed benchmark, when using a ResNet-50 pre-trained on ImageNet, this ensemble of averages achieves $88.6\%$ on PACS, $79.1\%$ on VLCS, $72.5\%$ on OfficeHome, $52.3\%$ on TerraIncognita, and $47.4\%$ on DomainNet, an average of $68.0\%$, beating ERM (w/o model averaging) by $\sim 4\%$. We also evaluate a model that is pre-trained on a larger dataset, where we show EoA achieves an average accuracy of $72.7\%$, beating its corresponding ERM baseline by $5\%$.
Momentum Contrastive Autoencoder: Using Contrastive Learning for Latent Space Distribution Matching in WAE
Oct 19, 2021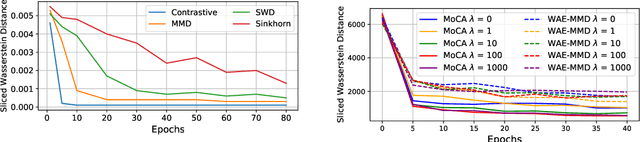
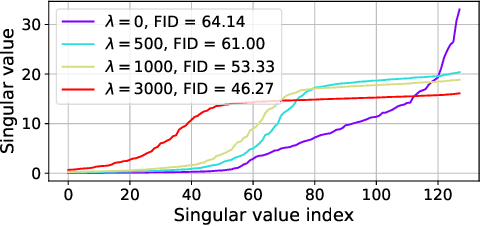
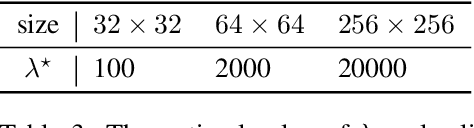
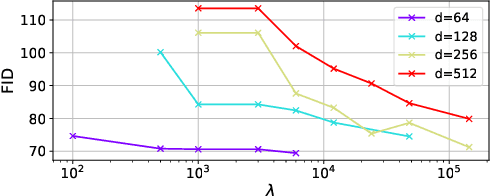
Wasserstein autoencoder (WAE) shows that matching two distributions is equivalent to minimizing a simple autoencoder (AE) loss under the constraint that the latent space of this AE matches a pre-specified prior distribution. This latent space distribution matching is a core component of WAE, and a challenging task. In this paper, we propose to use the contrastive learning framework that has been shown to be effective for self-supervised representation learning, as a means to resolve this problem. We do so by exploiting the fact that contrastive learning objectives optimize the latent space distribution to be uniform over the unit hyper-sphere, which can be easily sampled from. We show that using the contrastive learning framework to optimize the WAE loss achieves faster convergence and more stable optimization compared with existing popular algorithms for WAE. This is also reflected in the FID scores on CelebA and CIFAR-10 datasets, and the realistic generated image quality on the CelebA-HQ dataset.