 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMomentum Contrastive Autoencoder: Using Contrastive Learning for Latent Space Distribution Matching in WAE
Paper and Code
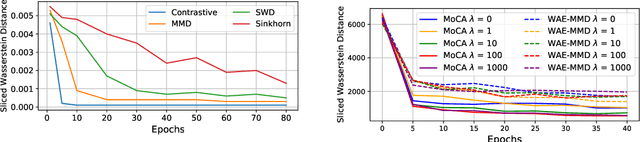
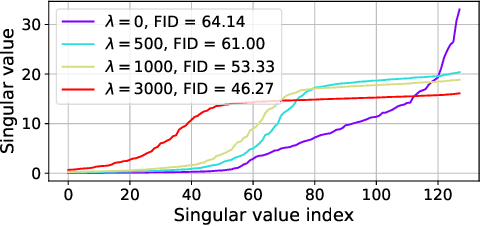
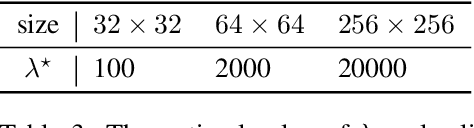
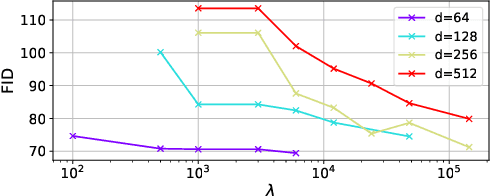
Wasserstein autoencoder (WAE) shows that matching two distributions is equivalent to minimizing a simple autoencoder (AE) loss under the constraint that the latent space of this AE matches a pre-specified prior distribution. This latent space distribution matching is a core component of WAE, and a challenging task. In this paper, we propose to use the contrastive learning framework that has been shown to be effective for self-supervised representation learning, as a means to resolve this problem. We do so by exploiting the fact that contrastive learning objectives optimize the latent space distribution to be uniform over the unit hyper-sphere, which can be easily sampled from. We show that using the contrastive learning framework to optimize the WAE loss achieves faster convergence and more stable optimization compared with existing popular algorithms for WAE. This is also reflected in the FID scores on CelebA and CIFAR-10 datasets, and the realistic generated image quality on the CelebA-HQ dataset.