 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Unlikelihood of D-Separation
Paper and Code
Mar 10, 2023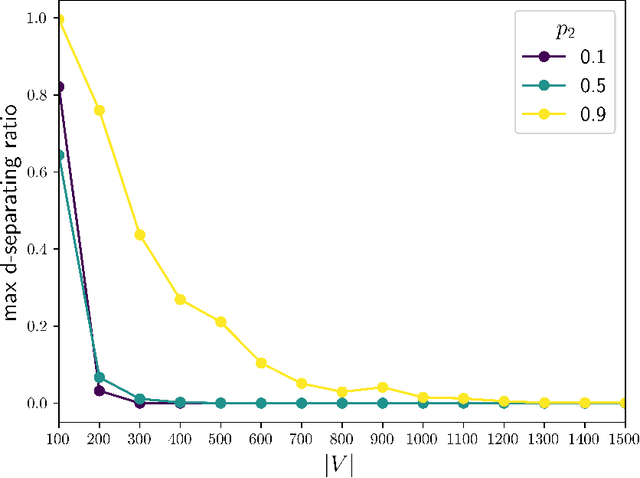
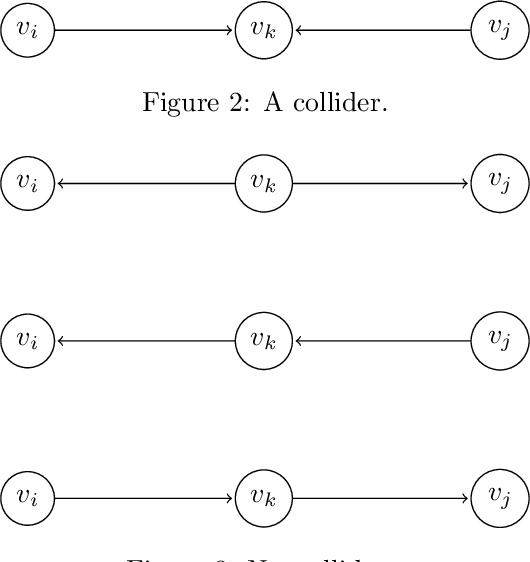
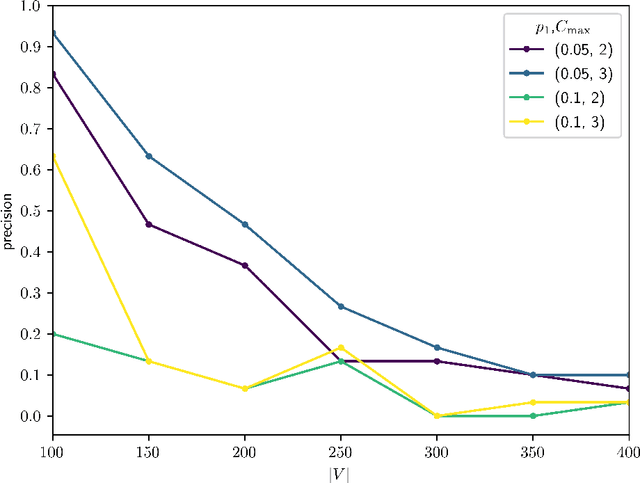
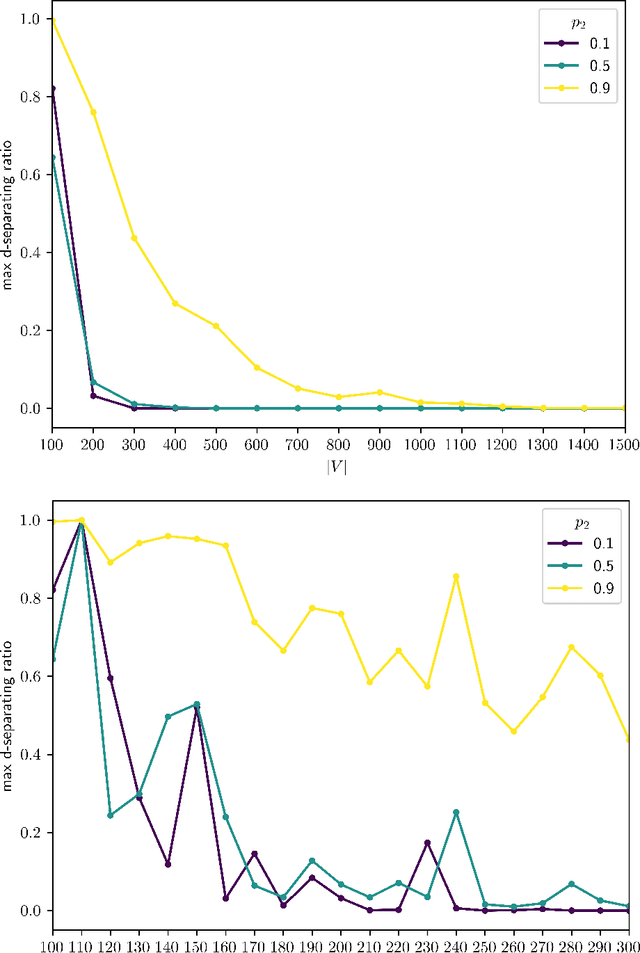
Causal discovery aims to recover a causal graph from data generated by it; constraint based methods do so by searching for a d-separating conditioning set of nodes in the graph via an oracle. In this paper, we provide analytic evidence that on large graphs, d-separation is a rare phenomenon, even when guaranteed to exist, unless the graph is extremely sparse. We then provide an analytic average case analysis of the PC Algorithm for causal discovery, as well as a variant of the SGS Algorithm we call UniformSGS. We consider a set $V=\{v_1,\ldots,v_n\}$ of nodes, and generate a random DAG $G=(V,E)$ where $(v_a, v_b) \in E$ with i.i.d. probability $p_1$ if $a<b$ and $0$ if $a > b$. We provide upper bounds on the probability that a subset of $V-\{x,y\}$ d-separates $x$ and $y$, conditional on $x$ and $y$ being d-separable; our upper bounds decay exponentially fast to $0$ as $|V| \rightarrow \infty$. For the PC Algorithm, while it is known that its worst-case guarantees fail on non-sparse graphs, we show that the same is true for the average case, and that the sparsity requirement is quite demanding: for good performance, the density must go to $0$ as $|V| \rightarrow \infty$ even in the average case. For UniformSGS, while it is known that the running time is exponential for existing edges, we show that in the average case, that is the expected running time for most non-existing edges as well.