 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Rich Nearest Neighbor Representations from Self-supervised Ensembles
Paper and Code
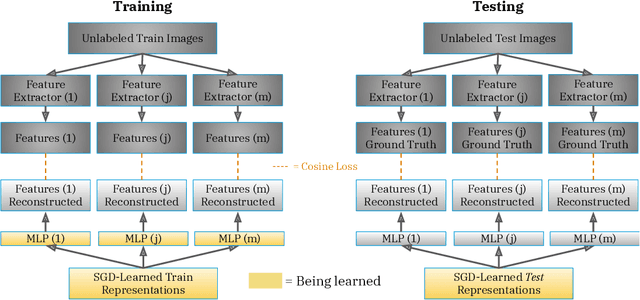
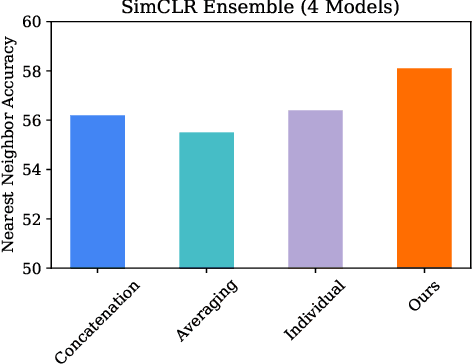
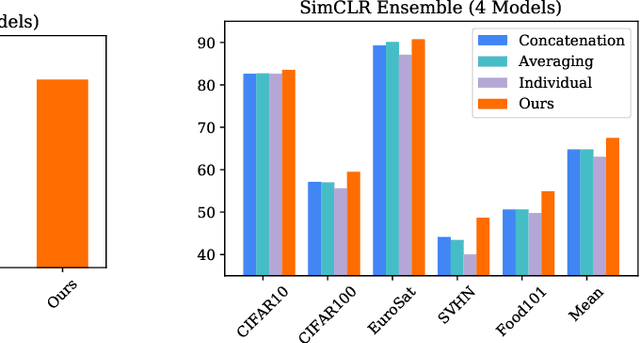
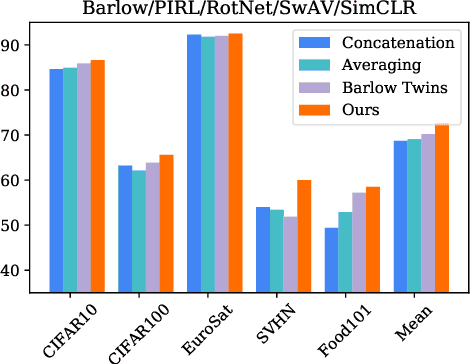
Pretraining convolutional neural networks via self-supervision, and applying them in transfer learning, is an incredibly fast-growing field that is rapidly and iteratively improving performance across practically all image domains. Meanwhile, model ensembling is one of the most universally applicable techniques in supervised learning literature and practice, offering a simple solution to reliably improve performance. But how to optimally combine self-supervised models to maximize representation quality has largely remained unaddressed. In this work, we provide a framework to perform self-supervised model ensembling via a novel method of learning representations directly through gradient descent at inference time. This technique improves representation quality, as measured by k-nearest neighbors, both on the in-domain dataset and in the transfer setting, with models transferable from the former setting to the latter. Additionally, this direct learning of feature through backpropagation improves representations from even a single model, echoing the improvements found in self-distillation.