 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Model Alignment Using Direct Preference Optimization
Nov 21, 2023



Large language models (LLMs) are fine-tuned using human comparison data with Reinforcement Learning from Human Feedback (RLHF) methods to make them better aligned with users' preferences. In contrast to LLMs, human preference learning has not been widely explored in text-to-image diffusion models; the best existing approach is to fine-tune a pretrained model using carefully curated high quality images and captions to improve visual appeal and text alignment. We propose Diffusion-DPO, a method to align diffusion models to human preferences by directly optimizing on human comparison data. Diffusion-DPO is adapted from the recently developed Direct Preference Optimization (DPO), a simpler alternative to RLHF which directly optimizes a policy that best satisfies human preferences under a classification objective. We re-formulate DPO to account for a diffusion model notion of likelihood, utilizing the evidence lower bound to derive a differentiable objective. Using the Pick-a-Pic dataset of 851K crowdsourced pairwise preferences, we fine-tune the base model of the state-of-the-art Stable Diffusion XL (SDXL)-1.0 model with Diffusion-DPO. Our fine-tuned base model significantly outperforms both base SDXL-1.0 and the larger SDXL-1.0 model consisting of an additional refinement model in human evaluation, improving visual appeal and prompt alignment. We also develop a variant that uses AI feedback and has comparable performance to training on human preferences, opening the door for scaling of diffusion model alignment methods.
End-to-End Diffusion Latent Optimization Improves Classifier Guidance
Mar 23, 2023Classifier guidance -- using the gradients of an image classifier to steer the generations of a diffusion model -- has the potential to dramatically expand the creative control over image generation and editing. However, currently classifier guidance requires either training new noise-aware models to obtain accurate gradients or using a one-step denoising approximation of the final generation, which leads to misaligned gradients and sub-optimal control. We highlight this approximation's shortcomings and propose a novel guidance method: Direct Optimization of Diffusion Latents (DOODL), which enables plug-and-play guidance by optimizing diffusion latents w.r.t. the gradients of a pre-trained classifier on the true generated pixels, using an invertible diffusion process to achieve memory-efficient backpropagation. Showcasing the potential of more precise guidance, DOODL outperforms one-step classifier guidance on computational and human evaluation metrics across different forms of guidance: using CLIP guidance to improve generations of complex prompts from DrawBench, using fine-grained visual classifiers to expand the vocabulary of Stable Diffusion, enabling image-conditioned generation with a CLIP visual encoder, and improving image aesthetics using an aesthetic scoring network.
EDICT: Exact Diffusion Inversion via Coupled Transformations
Nov 22, 2022
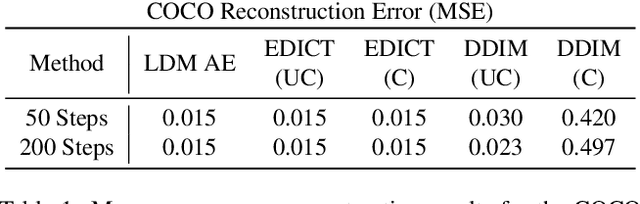

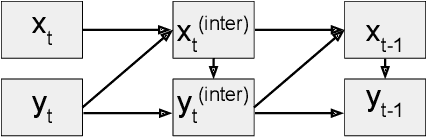
Finding an initial noise vector that produces an input image when fed into the diffusion process (known as inversion) is an important problem in denoising diffusion models (DDMs), with applications for real image editing. The state-of-the-art approach for real image editing with inversion uses denoising diffusion implicit models (DDIMs) to deterministically noise the image to the intermediate state along the path that the denoising would follow given the original conditioning. However, DDIM inversion for real images is unstable as it relies on local linearization assumptions, which result in the propagation of errors, leading to incorrect image reconstruction and loss of content. To alleviate these problems, we propose Exact Diffusion Inversion via Coupled Transformations (EDICT), an inversion method that draws inspiration from affine coupling layers. EDICT enables mathematically exact inversion of real and model-generated images by maintaining two coupled noise vectors which are used to invert each other in an alternating fashion. Using Stable Diffusion, a state-of-the-art latent diffusion model, we demonstrate that EDICT successfully reconstructs real images with high fidelity. On complex image datasets like MS-COCO, EDICT reconstruction significantly outperforms DDIM, improving the mean square error of reconstruction by a factor of two. Using noise vectors inverted from real images, EDICT enables a wide range of image edits--from local and global semantic edits to image stylization--while maintaining fidelity to the original image structure. EDICT requires no model training/finetuning, prompt tuning, or extra data and can be combined with any pretrained DDM. Code will be made available shortly.
Activation Regression for Continuous Domain Generalization with Applications to Crop Classification
Apr 14, 2022

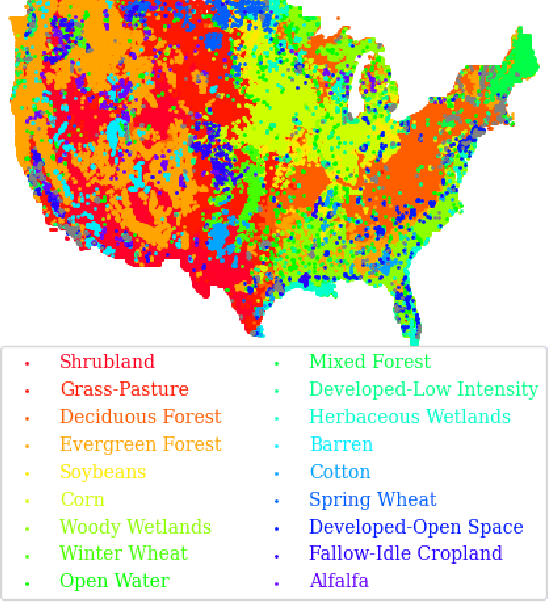

Geographic variance in satellite imagery impacts the ability of machine learning models to generalise to new regions. In this paper, we model geographic generalisation in medium resolution Landsat-8 satellite imagery as a continuous domain adaptation problem, demonstrating how models generalise better with appropriate domain knowledge. We develop a dataset spatially distributed across the entire continental United States, providing macroscopic insight into the effects of geography on crop classification in multi-spectral and temporally distributed satellite imagery. Our method demonstrates improved generalisability from 1) passing geographically correlated climate variables along with the satellite data to a Transformer model and 2) regressing on the model features to reconstruct these domain variables. Combined, we provide a novel perspective on geographic generalisation in satellite imagery and a simple-yet-effective approach to leverage domain knowledge. Code is available at: \url{https://github.com/samar-khanna/cropmap}
Learning Rich Nearest Neighbor Representations from Self-supervised Ensembles
Oct 19, 2021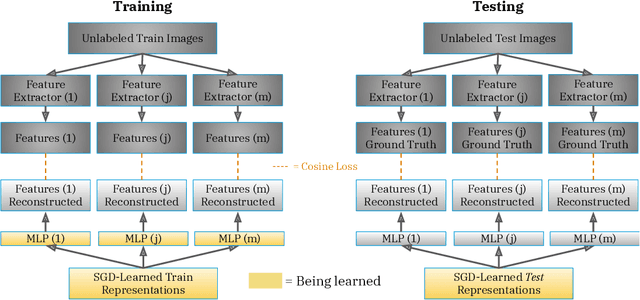
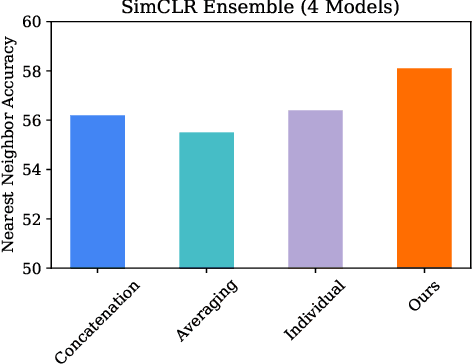
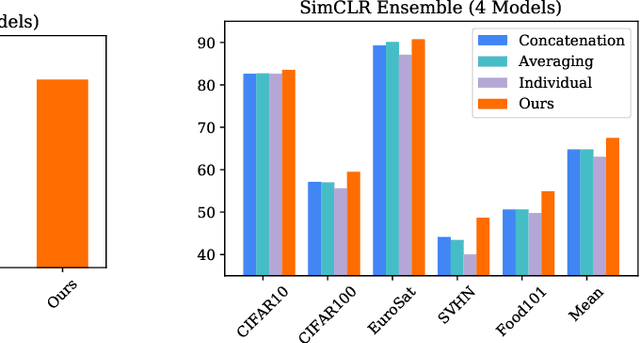
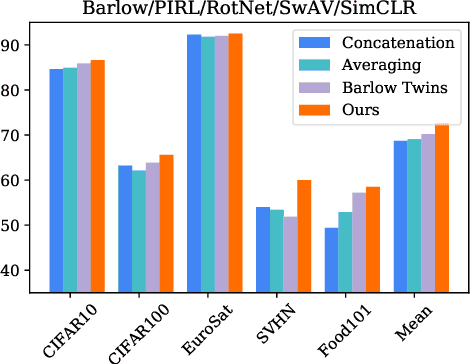
Pretraining convolutional neural networks via self-supervision, and applying them in transfer learning, is an incredibly fast-growing field that is rapidly and iteratively improving performance across practically all image domains. Meanwhile, model ensembling is one of the most universally applicable techniques in supervised learning literature and practice, offering a simple solution to reliably improve performance. But how to optimally combine self-supervised models to maximize representation quality has largely remained unaddressed. In this work, we provide a framework to perform self-supervised model ensembling via a novel method of learning representations directly through gradient descent at inference time. This technique improves representation quality, as measured by k-nearest neighbors, both on the in-domain dataset and in the transfer setting, with models transferable from the former setting to the latter. Additionally, this direct learning of feature through backpropagation improves representations from even a single model, echoing the improvements found in self-distillation.
Extending and Analyzing Self-Supervised Learning Across Domains
Apr 24, 2020
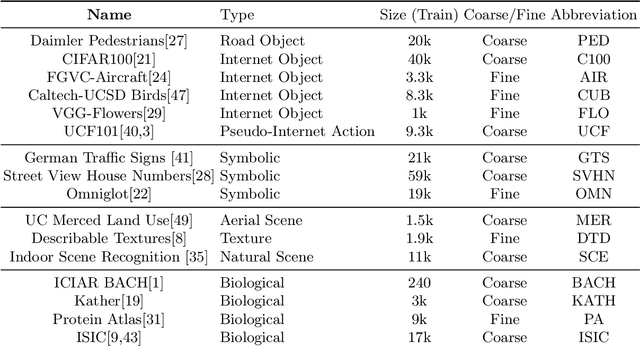
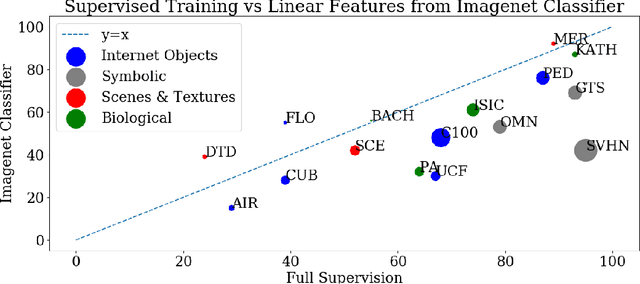
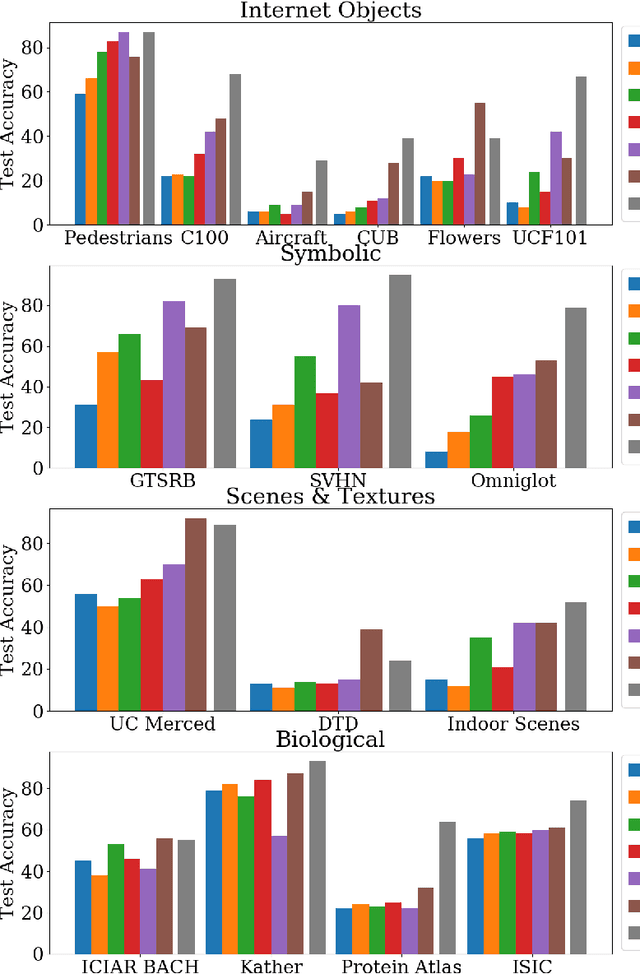
Self-supervised representation learning has achieved impressive results in recent years, with experiments primarily coming on ImageNet or other similarly large internet imagery datasets. There has been little to no work with these methods on other smaller domains, such as satellite, textural, or biological imagery. We experiment with several popular methods on an unprecedented variety of domains. We discover, among other findings, that Rotation is by far the most semantically meaningful task, with much of the performance of Jigsaw and Instance Discrimination being attributable to the nature of their induced distribution rather than semantic understanding. Additionally, there are several areas, such as fine-grain classification, where all tasks underperform. We quantitatively and qualitatively diagnose the reasons for these failures and successes via novel experiments studying pretext generalization, random labelings, and implicit dimensionality. Code and models are available at https://github.com/BramSW/Extending_SSRL_Across_Domains/.
Few-Shot Generalization for Single-Image 3D Reconstruction via Priors
Sep 03, 2019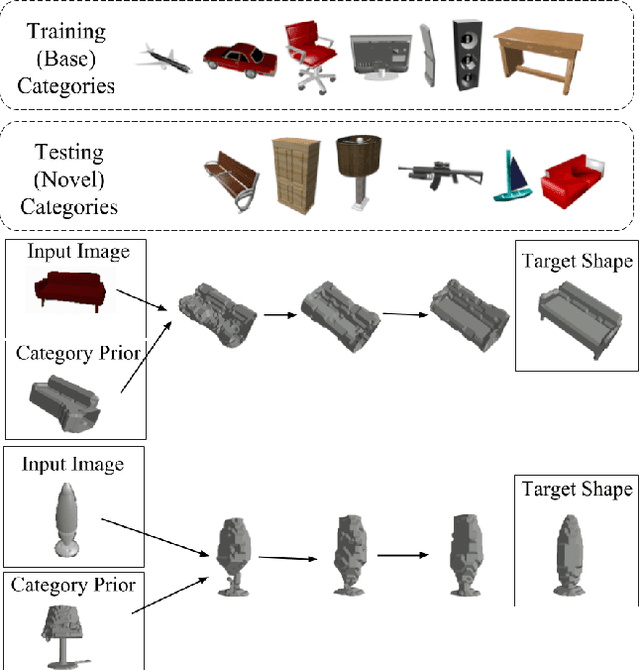
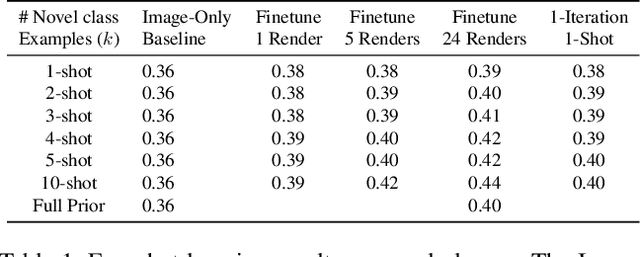
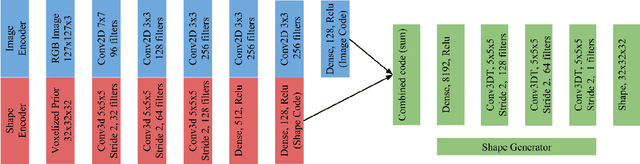
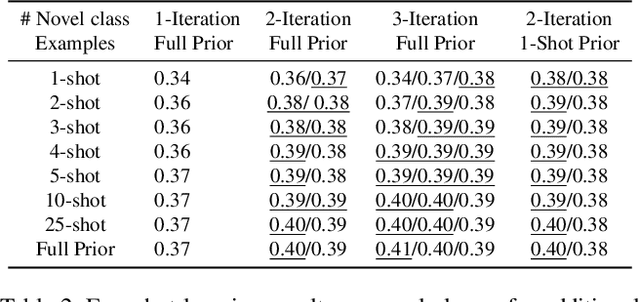
Recent work on single-view 3D reconstruction shows impressive results, but has been restricted to a few fixed categories where extensive training data is available. The problem of generalizing these models to new classes with limited training data is largely open. To address this problem, we present a new model architecture that reframes single-view 3D reconstruction as learnt, category agnostic refinement of a provided, category-specific prior. The provided prior shape for a novel class can be obtained from as few as one 3D shape from this class. Our model can start reconstructing objects from the novel class using this prior without seeing any training image for this class and without any retraining. Our model outperforms category-agnostic baselines and remains competitive with more sophisticated baselines that finetune on the novel categories. Additionally, our network is capable of improving the reconstruction given multiple views despite not being trained on task of multi-view reconstruction.