 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIME: MIMicking Emotions for Empathetic Response Generation
Oct 04, 2020

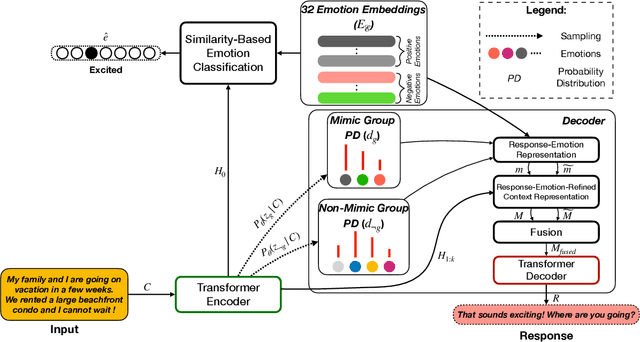
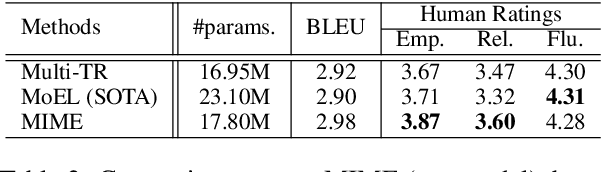
Current approaches to empathetic response generation view the set of emotions expressed in the input text as a flat structure, where all the emotions are treated uniformly. We argue that empathetic responses often mimic the emotion of the user to a varying degree, depending on its positivity or negativity and content. We show that the consideration of this polarity-based emotion clusters and emotional mimicry results in improved empathy and contextual relevance of the response as compared to the state-of-the-art. Also, we introduce stochasticity into the emotion mixture that yields emotionally more varied empathetic responses than the previous work. We demonstrate the importance of these factors to empathetic response generation using both automatic- and human-based evaluations. The implementation of MIME is publicly available at https://github.com/declare-lab/MIME.
Model Agnostic Defence against Backdoor Attacks in Machine Learning
Aug 28, 2019
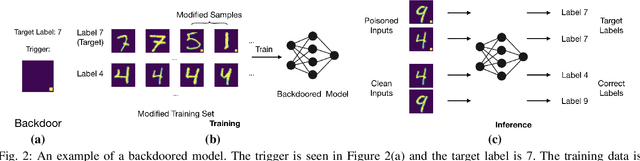


Machine Learning (ML) has automated a multitude of our day-to-day decision making domains such as education, employment and driving automation. The continued success of ML largely depends on our ability to trust the model we are using. Recently, a new class of attacks called Backdoor Attacks have been developed. These attacks undermine the user's trust in ML models. In this work, we present NEO, a model agnostic framework to detect and mitigate such backdoor attacks in image classification ML models. For a given image classification model, our approach analyses the inputs it receives and determines if the model is backdoored. In addition to this feature, we also mitigate these attacks by determining the correct predictions of the poisoned images. An appealing feature of NEO is that it can, for the first time, isolate and reconstruct the backdoor trigger. NEO is also the first defence methodology, to the best of our knowledge that is completely blackbox. We have implemented NEO and evaluated it against three state of the art poisoned models. These models include highly critical applications such as traffic sign detection (USTS) and facial detection. In our evaluation, we show that NEO can detect $\approx$88\% of the poisoned inputs on average and it is as fast as 4.4 ms per input image. We also reconstruct the poisoned input for the user to effectively test their systems.