 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Deduplication Techniques for Economic Research Paper Titles with a Focus on Semantic Similarity using NLP and LLMs
Oct 02, 2024This study investigates efficient deduplication techniques for a large NLP dataset of economic research paper titles. We explore various pairing methods alongside established distance measures (Levenshtein distance, cosine similarity) and a sBERT model for semantic evaluation. Our findings suggest a potentially low prevalence of duplicates based on the observed semantic similarity across different methods. Further exploration with a human-annotated ground truth set is completed for a more conclusive assessment. The result supports findings from the NLP, LLM based distance metrics.
NaijaHate: Evaluating Hate Speech Detection on Nigerian Twitter Using Representative Data
Mar 28, 2024



To address the global issue of hateful content proliferating in online platforms, hate speech detection (HSD) models are typically developed on datasets collected in the United States, thereby failing to generalize to English dialects from the Majority World. Furthermore, HSD models are often evaluated on curated samples, raising concerns about overestimating model performance in real-world settings. In this work, we introduce NaijaHate, the first dataset annotated for HSD which contains a representative sample of Nigerian tweets. We demonstrate that HSD evaluated on biased datasets traditionally used in the literature largely overestimates real-world performance on representative data. We also propose NaijaXLM-T, a pretrained model tailored to the Nigerian Twitter context, and establish the key role played by domain-adaptive pretraining and finetuning in maximizing HSD performance. Finally, we show that in this context, a human-in-the-loop approach to content moderation where humans review 1% of Nigerian tweets flagged as hateful would enable to moderate 60% of all hateful content. Taken together, these results pave the way towards robust HSD systems and a better protection of social media users from hateful content in low-resource settings.
Word Order Matters when you Increase Masking
Nov 08, 2022Word order, an essential property of natural languages, is injected in Transformer-based neural language models using position encoding. However, recent experiments have shown that explicit position encoding is not always useful, since some models without such feature managed to achieve state-of-the art performance on some tasks. To understand better this phenomenon, we examine the effect of removing position encodings on the pre-training objective itself (i.e., masked language modelling), to test whether models can reconstruct position information from co-occurrences alone. We do so by controlling the amount of masked tokens in the input sentence, as a proxy to affect the importance of position information for the task. We find that the necessity of position information increases with the amount of masking, and that masked language models without position encodings are not able to reconstruct this information on the task. These findings point towards a direct relationship between the amount of masking and the ability of Transformers to capture order-sensitive aspects of language using position encoding.
State-of-the-art generalisation research in NLP: a taxonomy and review
Oct 10, 2022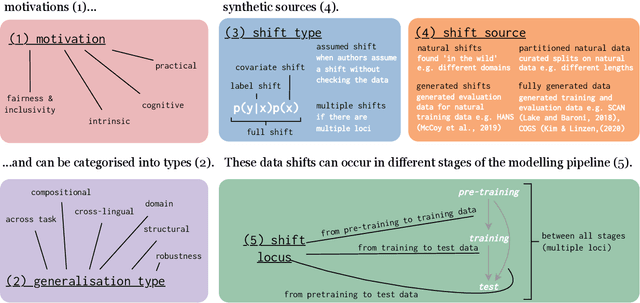
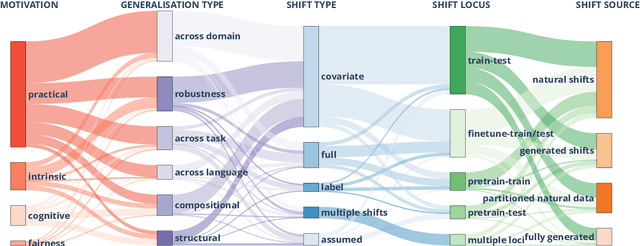
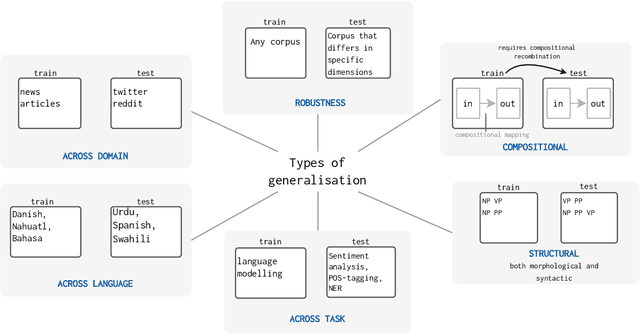

The ability to generalise well is one of the primary desiderata of natural language processing (NLP). Yet, what `good generalisation' entails and how it should be evaluated is not well understood, nor are there any common standards to evaluate it. In this paper, we aim to lay the ground-work to improve both of these issues. We present a taxonomy for characterising and understanding generalisation research in NLP, we use that taxonomy to present a comprehensive map of published generalisation studies, and we make recommendations for which areas might deserve attention in the future. Our taxonomy is based on an extensive literature review of generalisation research, and contains five axes along which studies can differ: their main motivation, the type of generalisation they aim to solve, the type of data shift they consider, the source by which this data shift is obtained, and the locus of the shift within the modelling pipeline. We use our taxonomy to classify over 400 previous papers that test generalisation, for a total of more than 600 individual experiments. Considering the results of this review, we present an in-depth analysis of the current state of generalisation research in NLP, and make recommendations for the future. Along with this paper, we release a webpage where the results of our review can be dynamically explored, and which we intend to up-date as new NLP generalisation studies are published. With this work, we aim to make steps towards making state-of-the-art generalisation testing the new status quo in NLP.
Subject Verb Agreement Error Patterns in Meaningless Sentences: Humans vs. BERT
Sep 21, 2022


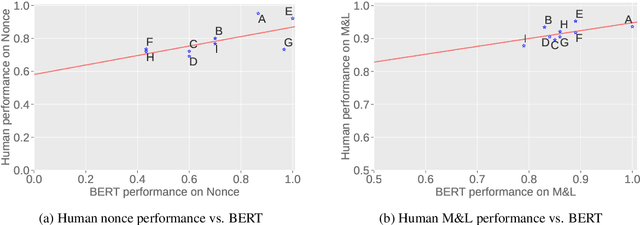
Both humans and neural language models are able to perform subject-verb number agreement (SVA). In principle, semantics shouldn't interfere with this task, which only requires syntactic knowledge. In this work we test whether meaning interferes with this type of agreement in English in syntactic structures of various complexities. To do so, we generate both semantically well-formed and nonsensical items. We compare the performance of BERT-base to that of humans, obtained with a psycholinguistic online crowdsourcing experiment. We find that BERT and humans are both sensitive to our semantic manipulation: They fail more often when presented with nonsensical items, especially when their syntactic structure features an attractor (a noun phrase between the subject and the verb that has not the same number as the subject). We also find that the effect of meaningfulness on SVA errors is stronger for BERT than for humans, showing higher lexical sensitivity of the former on this task.
Probing for the Usage of Grammatical Number
Apr 21, 2022
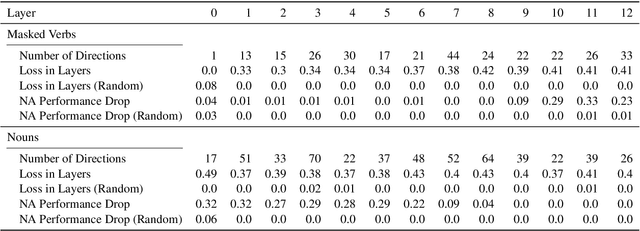

A central quest of probing is to uncover how pre-trained models encode a linguistic property within their representations. An encoding, however, might be spurious-i.e., the model might not rely on it when making predictions. In this paper, we try to find encodings that the model actually uses, introducing a usage-based probing setup. We first choose a behavioral task which cannot be solved without using the linguistic property. Then, we attempt to remove the property by intervening on the model's representations. We contend that, if an encoding is used by the model, its removal should harm the performance on the chosen behavioral task. As a case study, we focus on how BERT encodes grammatical number, and on how it uses this encoding to solve the number agreement task. Experimentally, we find that BERT relies on a linear encoding of grammatical number to produce the correct behavioral output. We also find that BERT uses a separate encoding of grammatical number for nouns and verbs. Finally, we identify in which layers information about grammatical number is transferred from a noun to its head verb.
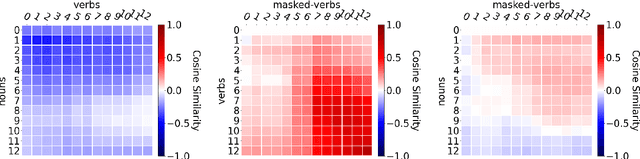
Does BERT really agree ? Fine-grained Analysis of Lexical Dependence on a Syntactic Task
Apr 14, 2022
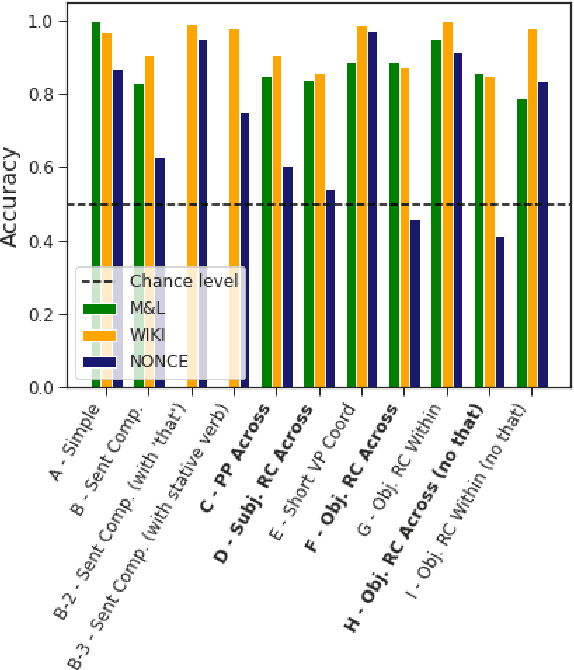
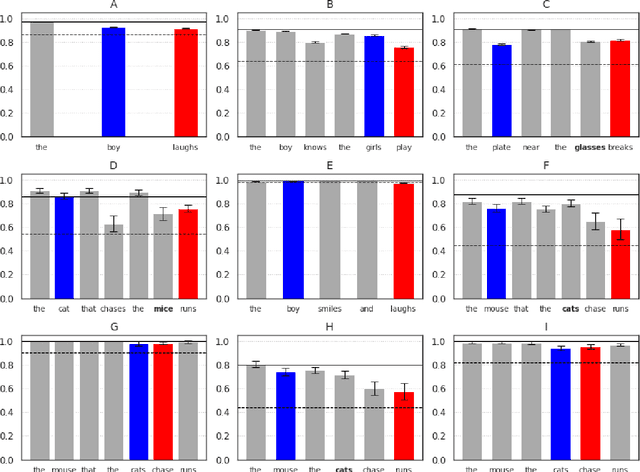

Although transformer-based Neural Language Models demonstrate impressive performance on a variety of tasks, their generalization abilities are not well understood. They have been shown to perform strongly on subject-verb number agreement in a wide array of settings, suggesting that they learned to track syntactic dependencies during their training even without explicit supervision. In this paper, we examine the extent to which BERT is able to perform lexically-independent subject-verb number agreement (NA) on targeted syntactic templates. To do so, we disrupt the lexical patterns found in naturally occurring stimuli for each targeted structure in a novel fine-grained analysis of BERT's behavior. Our results on nonce sentences suggest that the model generalizes well for simple templates, but fails to perform lexically-independent syntactic generalization when as little as one attractor is present.