 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete representations in neural models of spoken language
May 12, 2021
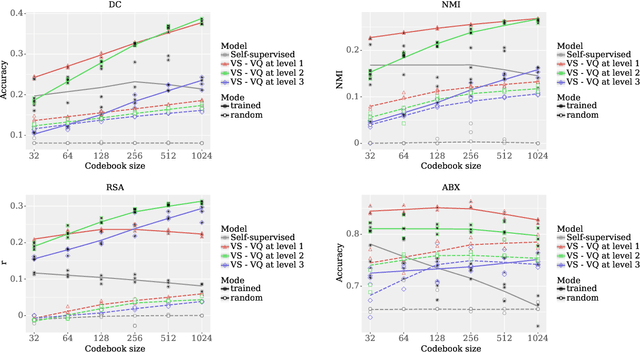
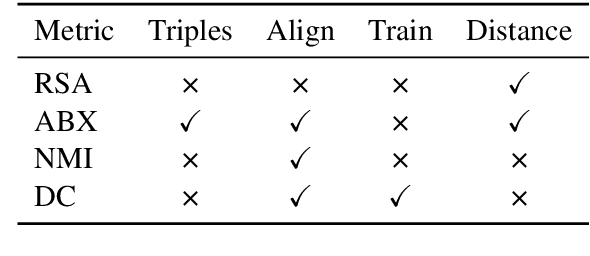
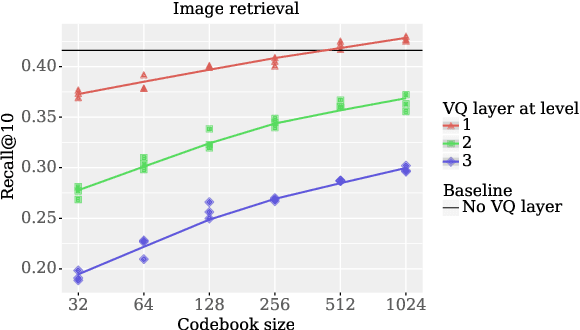
The distributed and continuous representations used by neural networks are at odds with representations employed in linguistics, which are typically symbolic. Vector quantization has been proposed as a way to induce discrete neural representations that are closer in nature to their linguistic counterparts. However, it is not clear which metrics are the best-suited to analyze such discrete representations. We compare the merits of four commonly used metrics in the context of weakly supervised models of spoken language. We perform a systematic analysis of the impact of (i) architectural choices, (ii) the learning objective and training dataset, and (iii) the evaluation metric. We find that the different evaluation metrics can give inconsistent results. In particular, we find that the use of minimal pairs of phoneme triples as stimuli during evaluation disadvantages larger embeddings, unlike metrics applied to complete utterances.
Learning to Understand Child-directed and Adult-directed Speech
May 22, 2020
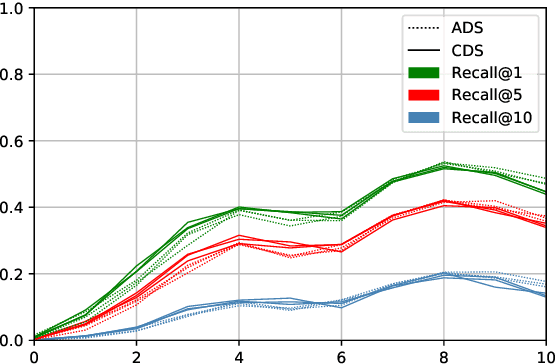
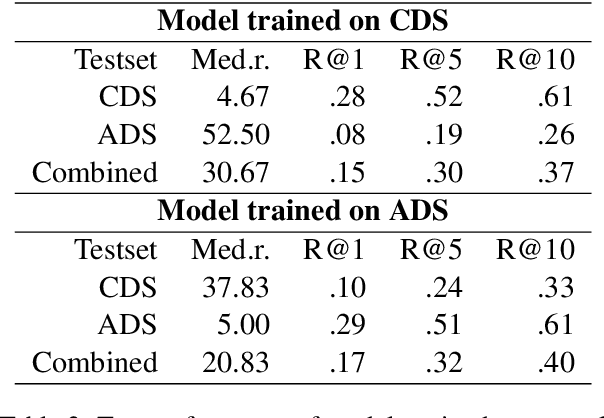
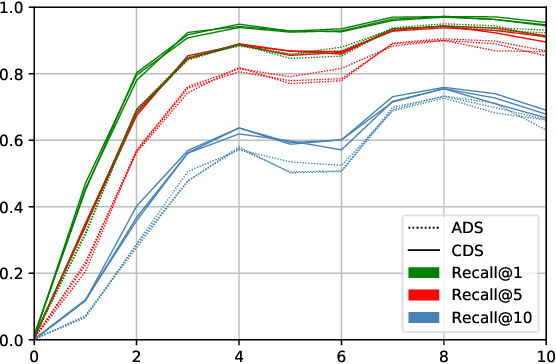
Speech directed to children differs from adult-directed speech in linguistic aspects such as repetition, word choice, and sentence length, as well as in aspects of the speech signal itself, such as prosodic and phonemic variation. Human language acquisition research indicates that child-directed speech helps language learners. This study explores the effect of child-directed speech when learning to extract semantic information from speech directly. We compare the task performance of models trained on adult-directed speech (ADS) and child-directed speech (CDS). We find indications that CDS helps in the initial stages of learning, but eventually, models trained on ADS reach comparable task performance, and generalize better. The results suggest that this is at least partially due to linguistic rather than acoustic properties of the two registers, as we see the same pattern when looking at models trained on acoustically comparable synthetic speech.
The PhotoBook Dataset: Building Common Ground through Visually-Grounded Dialogue
Jun 04, 2019
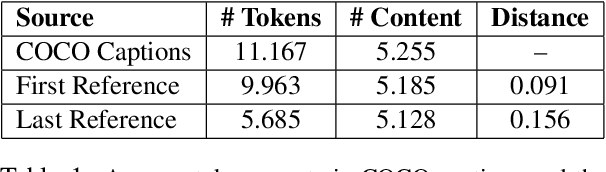
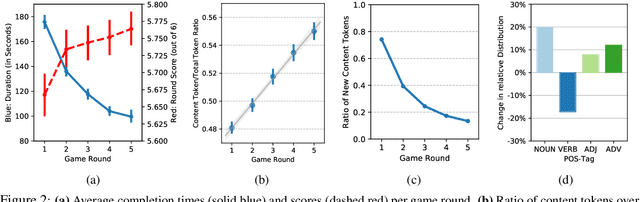
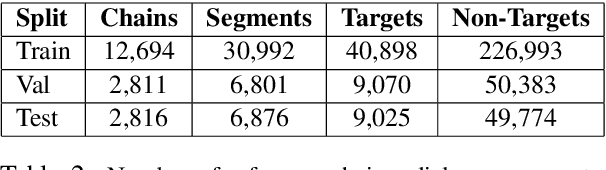
This paper introduces the PhotoBook dataset, a large-scale collection of visually-grounded, task-oriented dialogues in English designed to investigate shared dialogue history accumulating during conversation. Taking inspiration from seminal work on dialogue analysis, we propose a data-collection task formulated as a collaborative game prompting two online participants to refer to images utilising both their visual context as well as previously established referring expressions. We provide a detailed description of the task setup and a thorough analysis of the 2,500 dialogues collected. To further illustrate the novel features of the dataset, we propose a baseline model for reference resolution which uses a simple method to take into account shared information accumulated in a reference chain. Our results show that this information is particularly important to resolve later descriptions and underline the need to develop more sophisticated models of common ground in dialogue interaction.
On the difficulty of a distributional semantics of spoken language
Oct 26, 2018

In the domain of unsupervised learning most work on speech has focused on discovering low-level constructs such as phoneme inventories or word-like units. In contrast, for written language, where there is a large body of work on unsupervised induction of semantic representations of words, whole sentences and longer texts. In this study we examine the challenges of adapting these approaches from written to spoken language. We conjecture that unsupervised learning of the semantics of spoken language becomes feasible if we abstract from the surface variability. We simulate this setting with a dataset of utterances spoken by a realistic but uniform synthetic voice. We evaluate two simple unsupervised models which, to varying degrees of success, learn semantic representations of speech fragments. Finally we present inconclusive results on human speech, and discuss the challenges inherent in learning distributional semantic representations on unrestricted natural spoken language.
Representations of language in a model of visually grounded speech signal
Jun 30, 2017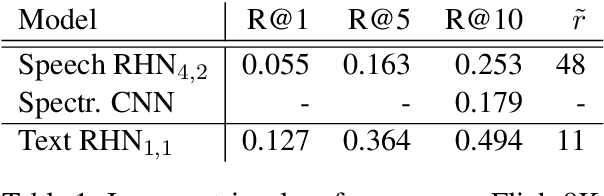



We present a visually grounded model of speech perception which projects spoken utterances and images to a joint semantic space. We use a multi-layer recurrent highway network to model the temporal nature of spoken speech, and show that it learns to extract both form and meaning-based linguistic knowledge from the input signal. We carry out an in-depth analysis of the representations used by different components of the trained model and show that encoding of semantic aspects tends to become richer as we go up the hierarchy of layers, whereas encoding of form-related aspects of the language input tends to initially increase and then plateau or decrease.
From phonemes to images: levels of representation in a recurrent neural model of visually-grounded language learning
Oct 11, 2016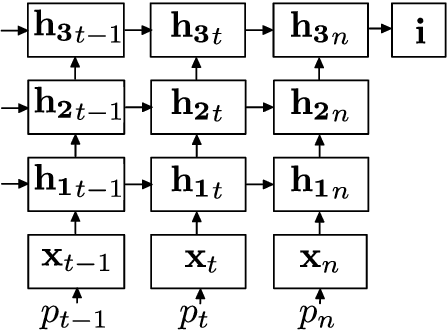



We present a model of visually-grounded language learning based on stacked gated recurrent neural networks which learns to predict visual features given an image description in the form of a sequence of phonemes. The learning task resembles that faced by human language learners who need to discover both structure and meaning from noisy and ambiguous data across modalities. We show that our model indeed learns to predict features of the visual context given phonetically transcribed image descriptions, and show that it represents linguistic information in a hierarchy of levels: lower layers in the stack are comparatively more sensitive to form, whereas higher layers are more sensitive to meaning.