Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom phonemes to images: levels of representation in a recurrent neural model of visually-grounded language learning
Paper and Code
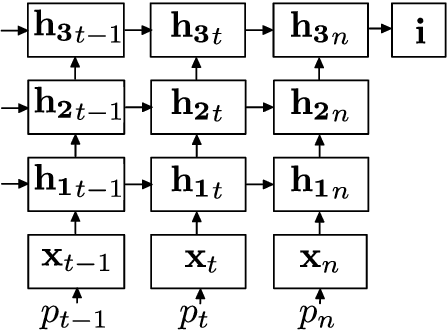



We present a model of visually-grounded language learning based on stacked gated recurrent neural networks which learns to predict visual features given an image description in the form of a sequence of phonemes. The learning task resembles that faced by human language learners who need to discover both structure and meaning from noisy and ambiguous data across modalities. We show that our model indeed learns to predict features of the visual context given phonetically transcribed image descriptions, and show that it represents linguistic information in a hierarchy of levels: lower layers in the stack are comparatively more sensitive to form, whereas higher layers are more sensitive to meaning.
* Accepted at COLING 2016
View paper on