 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZR-2021VG: Zero-Resource Speech Challenge, Visually-Grounded Language Modelling track, 2021 edition
Jul 14, 2021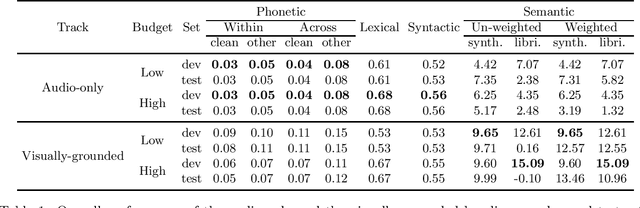
We present the visually-grounded language modelling track that was introduced in the Zero-Resource Speech challenge, 2021 edition, 2nd round. We motivate the new track and discuss participation rules in detail. We also present the two baseline systems that were developed for this track.
Discrete representations in neural models of spoken language
May 12, 2021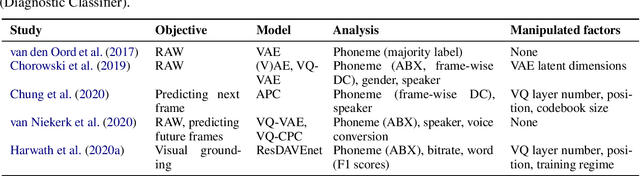
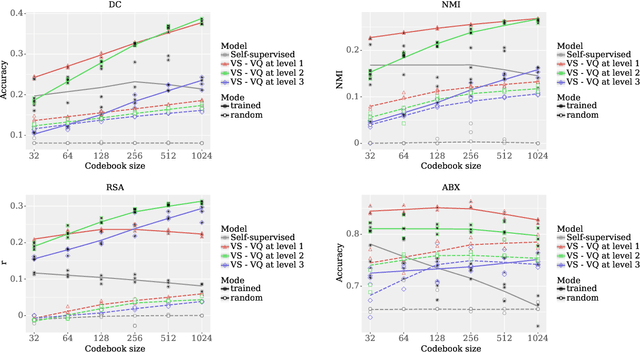
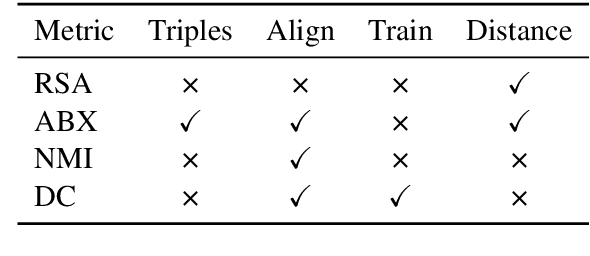
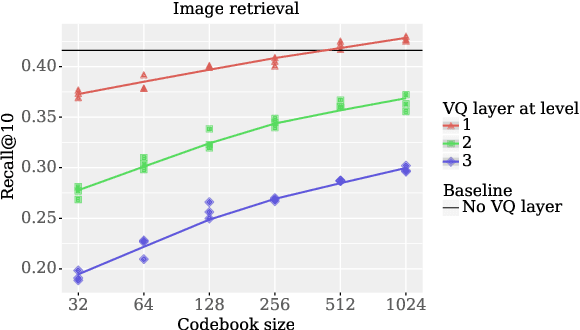
The distributed and continuous representations used by neural networks are at odds with representations employed in linguistics, which are typically symbolic. Vector quantization has been proposed as a way to induce discrete neural representations that are closer in nature to their linguistic counterparts. However, it is not clear which metrics are the best-suited to analyze such discrete representations. We compare the merits of four commonly used metrics in the context of weakly supervised models of spoken language. We perform a systematic analysis of the impact of (i) architectural choices, (ii) the learning objective and training dataset, and (iii) the evaluation metric. We find that the different evaluation metrics can give inconsistent results. In particular, we find that the use of minimal pairs of phoneme triples as stimuli during evaluation disadvantages larger embeddings, unlike metrics applied to complete utterances.
Textual Supervision for Visually Grounded Spoken Language Understanding
Oct 07, 2020

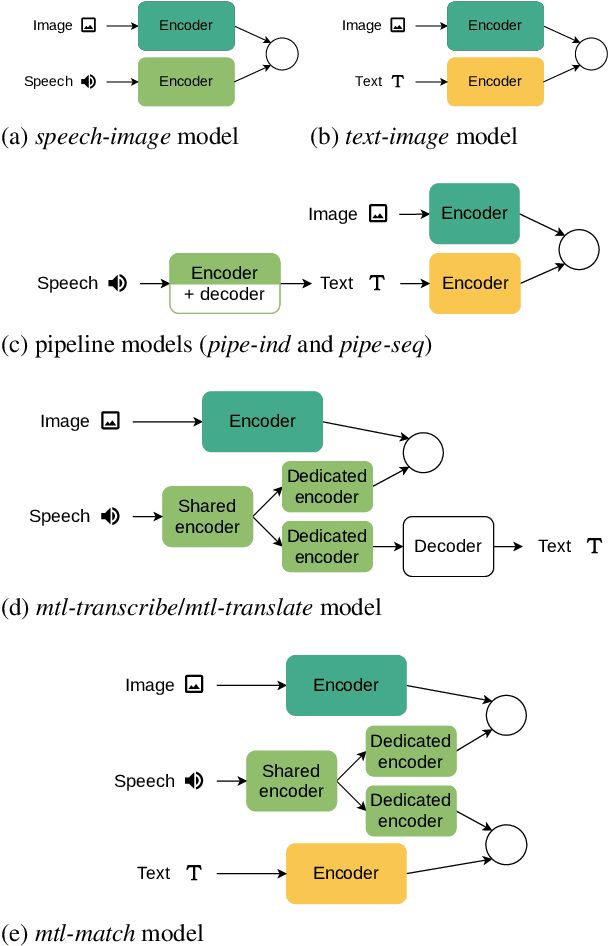

Visually-grounded models of spoken language understanding extract semantic information directly from speech, without relying on transcriptions. This is useful for low-resource languages, where transcriptions can be expensive or impossible to obtain. Recent work showed that these models can be improved if transcriptions are available at training time. However, it is not clear how an end-to-end approach compares to a traditional pipeline-based approach when one has access to transcriptions. Comparing different strategies, we find that the pipeline approach works better when enough text is available. With low-resource languages in mind, we also show that translations can be effectively used in place of transcriptions but more data is needed to obtain similar results.
Analyzing analytical methods: The case of phonology in neural models of spoken language
May 02, 2020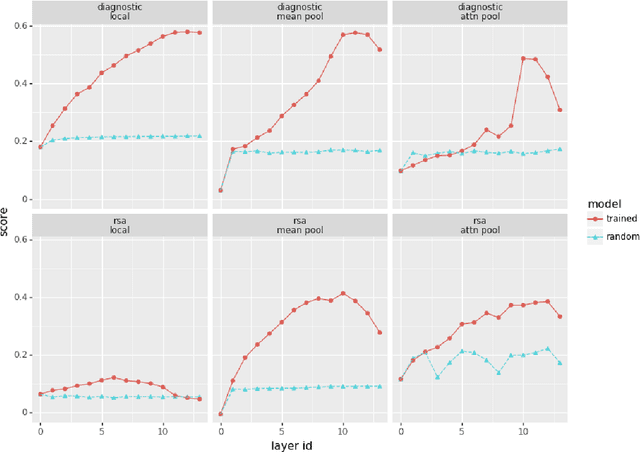
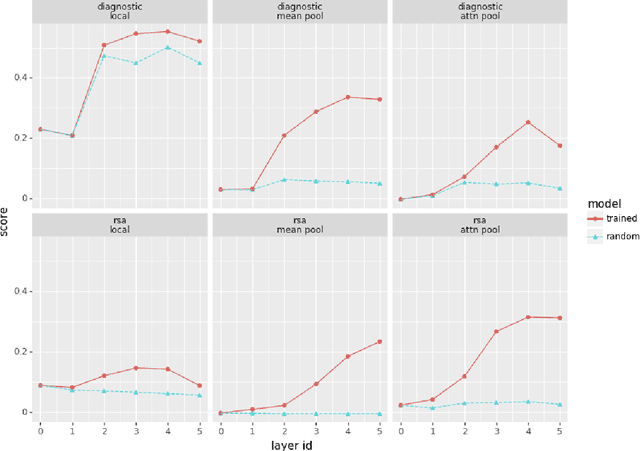
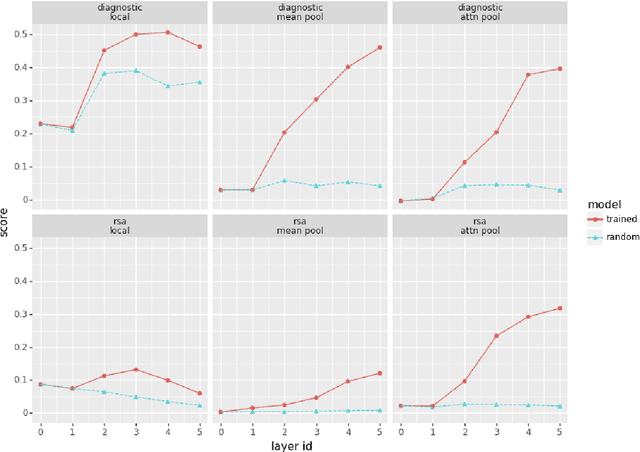
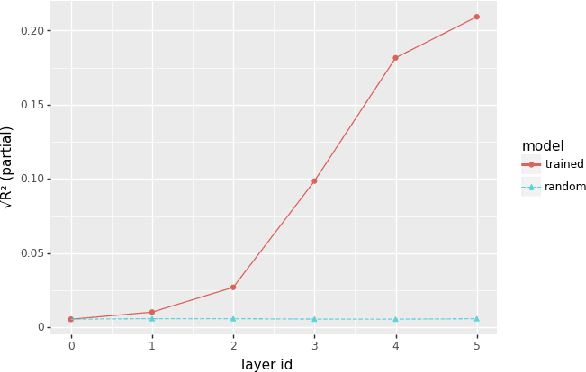
Given the fast development of analysis techniques for NLP and speech processing systems, few systematic studies have been conducted to compare the strengths and weaknesses of each method. As a step in this direction we study the case of representations of phonology in neural network models of spoken language. We use two commonly applied analytical techniques, diagnostic classifiers and representational similarity analysis, to quantify to what extent neural activation patterns encode phonemes and phoneme sequences. We manipulate two factors that can affect the outcome of analysis. First, we investigate the role of learning by comparing neural activations extracted from trained versus randomly-initialized models. Second, we examine the temporal scope of the activations by probing both local activations corresponding to a few milliseconds of the speech signal, and global activations pooled over the whole utterance. We conclude that reporting analysis results with randomly initialized models is crucial, and that global-scope methods tend to yield more consistent results and we recommend their use as a complement to local-scope diagnostic methods.
Few-shot learning with attention-based sequence-to-sequence models
Nov 08, 2018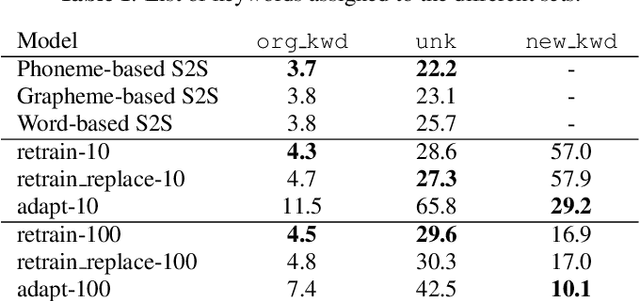
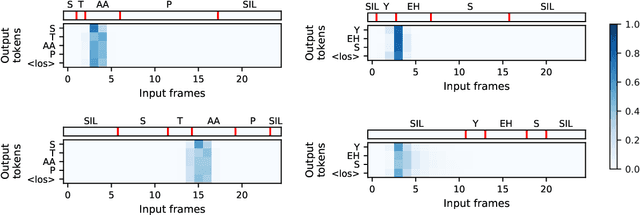
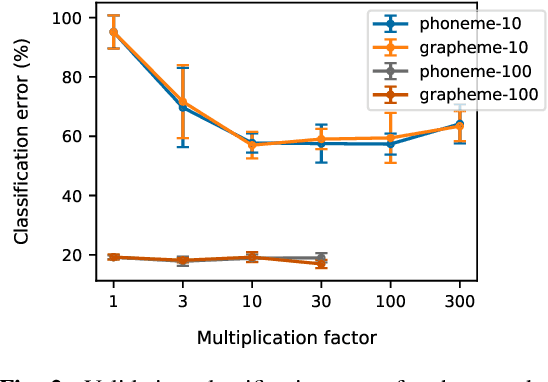
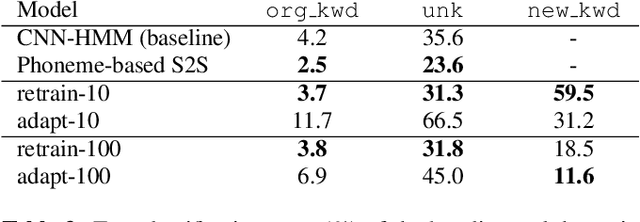
End-to-end approaches have recently become popular as a means of simplifying the training and deployment of speech recognition systems. However, they often require large amounts of data to perform well on large vocabulary tasks. With the aim of making end-to-end approaches usable by a broader range of researchers, we explore the potential to use end-to-end methods in small vocabulary contexts where smaller datasets may be used. A significant drawback of small-vocabulary systems is the difficulty of expanding the vocabulary beyond the original training samples -- therefore we also study strategies to extend the vocabulary with only few examples per new class (few-shot learning). Our results show that an attention-based encoder-decoder can be competitive against a strong baseline on a small vocabulary keyword classification task, reaching 97.5% of accuracy on Tensorflow's Speech Commands dataset. It also shows promising results on the few-shot learning problem where a simple strategy achieved 34.8% of accuracy on new keywords with only 10 examples for each new class. This score goes up to 80.3% with a larger set of 100 examples.