 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextual Supervision for Visually Grounded Spoken Language Understanding
Paper and Code


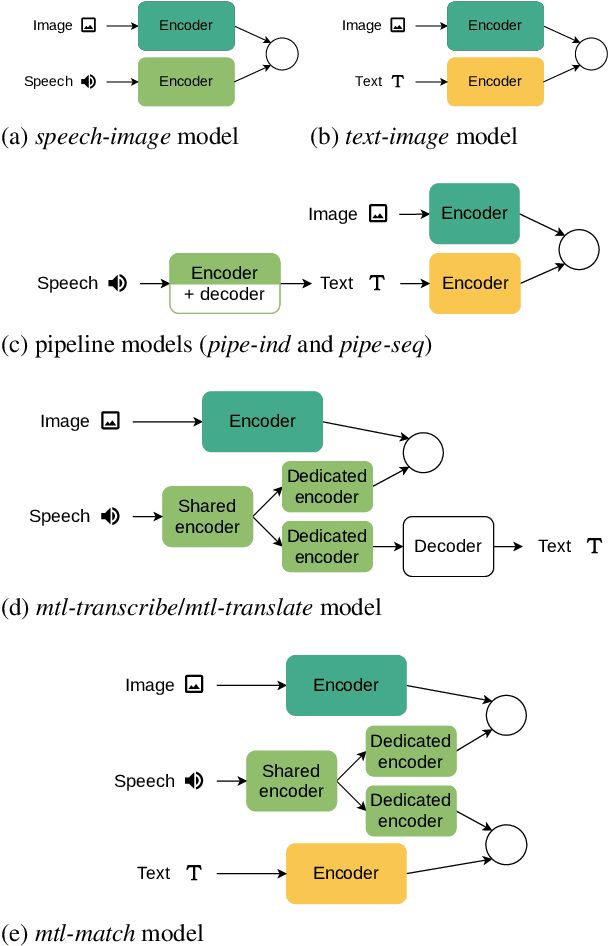

Visually-grounded models of spoken language understanding extract semantic information directly from speech, without relying on transcriptions. This is useful for low-resource languages, where transcriptions can be expensive or impossible to obtain. Recent work showed that these models can be improved if transcriptions are available at training time. However, it is not clear how an end-to-end approach compares to a traditional pipeline-based approach when one has access to transcriptions. Comparing different strategies, we find that the pipeline approach works better when enough text is available. With low-resource languages in mind, we also show that translations can be effectively used in place of transcriptions but more data is needed to obtain similar results.