 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling automatic transcription of child-centered audio recordings from real-world environments
Jun 13, 2025Longform audio recordings obtained with microphones worn by children-also known as child-centered daylong recordings-have become a standard method for studying children's language experiences and their impact on subsequent language development. Transcripts of longform speech audio would enable rich analyses at various linguistic levels, yet the massive scale of typical longform corpora prohibits comprehensive manual annotation. At the same time, automatic speech recognition (ASR)-based transcription faces significant challenges due to the noisy, unconstrained nature of real-world audio, and no existing study has successfully applied ASR to transcribe such data. However, previous attempts have assumed that ASR must process each longform recording in its entirety. In this work, we present an approach to automatically detect those utterances in longform audio that can be reliably transcribed with modern ASR systems, allowing automatic and relatively accurate transcription of a notable proportion of all speech in typical longform data. We validate the approach on four English longform audio corpora, showing that it achieves a median word error rate (WER) of 0% and a mean WER of 18% when transcribing 13% of the total speech in the dataset. In contrast, transcribing all speech without any filtering yields a median WER of 52% and a mean WER of 51%. We also compare word log-frequencies derived from the automatic transcripts with those from manual annotations and show that the frequencies correlate at r = 0.92 (Pearson) for all transcribed words and r = 0.98 for words that appear at least five times in the automatic transcripts. Overall, the work provides a concrete step toward increasingly detailed automated linguistic analyses of child-centered longform audio.
Investigating Affect Mining Techniques for Annotation Sample Selection in the Creation of Finnish Affective Speech Corpus
May 23, 2025Study of affect in speech requires suitable data, as emotional expression and perception vary across languages. Until now, no corpus has existed for natural expression of affect in spontaneous Finnish, existing data being acted or from a very specific communicative setting. This paper presents the first such corpus, created by annotating 12,000 utterances for emotional arousal and valence, sampled from three large-scale Finnish speech corpora. To ensure diverse affective expression, sample selection was conducted with an affect mining approach combining acoustic, cross-linguistic speech emotion, and text sentiment features. We compare this method to random sampling in terms of annotation diversity, and conduct post-hoc analyses to identify sampling choices that would have maximized the diversity. As an outcome, the work introduces a spontaneous Finnish affective speech corpus and informs sampling strategies for affective speech corpus creation in other languages or domains.
Text-based Audio Retrieval by Learning from Similarities between Audio Captions
Dec 02, 2024This paper proposes to use similarities of audio captions for estimating audio-caption relevances to be used for training text-based audio retrieval systems. Current audio-caption datasets (e.g., Clotho) contain audio samples paired with annotated captions, but lack relevance information about audio samples and captions beyond the annotated ones. Besides, mainstream approaches (e.g., CLAP) usually treat the annotated pairs as positives and consider all other audio-caption combinations as negatives, assuming a binary relevance between audio samples and captions. To infer the relevance between audio samples and arbitrary captions, we propose a method that computes non-binary audio-caption relevance scores based on the textual similarities of audio captions. We measure textual similarities of audio captions by calculating the cosine similarity of their Sentence-BERT embeddings and then transform these similarities into audio-caption relevance scores using a logistic function, thereby linking audio samples through their annotated captions to all other captions in the dataset. To integrate the computed relevances into training, we employ a listwise ranking objective, where relevance scores are converted into probabilities of ranking audio samples for a given textual query. We show the effectiveness of the proposed method by demonstrating improvements in text-based audio retrieval compared to methods that use binary audio-caption relevances for training.
PFML: Self-Supervised Learning of Time-Series Data Without Representation Collapse
Nov 15, 2024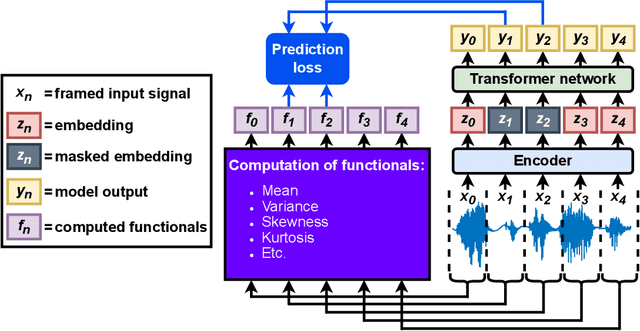
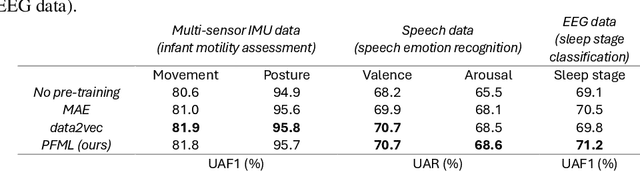
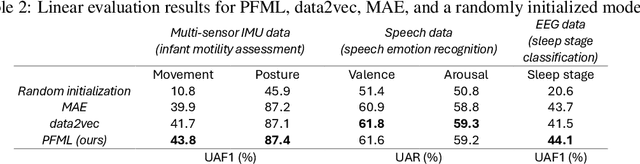
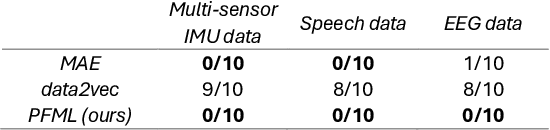
Self-supervised learning (SSL) is a data-driven learning approach that utilizes the innate structure of the data to guide the learning process. In contrast to supervised learning, which depends on external labels, SSL utilizes the inherent characteristics of the data to produce its own supervisory signal. However, one frequent issue with SSL methods is representation collapse, where the model outputs a constant input-invariant feature representation. This issue hinders the potential application of SSL methods to new data modalities, as trying to avoid representation collapse wastes researchers' time and effort. This paper introduces a novel SSL algorithm for time-series data called Prediction of Functionals from Masked Latents (PFML). Instead of predicting masked input signals or their latent representations directly, PFML operates by predicting statistical functionals of the input signal corresponding to masked embeddings, given a sequence of unmasked embeddings. The algorithm is designed to avoid representation collapse, rendering it straightforwardly applicable to different time-series data domains, such as novel sensor modalities in clinical data. We demonstrate the effectiveness of PFML through complex, real-life classification tasks across three different data modalities: infant posture and movement classification from multi-sensor inertial measurement unit data, emotion recognition from speech data, and sleep stage classification from EEG data. The results show that PFML is superior to a conceptually similar pre-existing SSL method and competitive against the current state-of-the-art SSL method, while also being conceptually simpler and without suffering from representation collapse.
Integrating Continuous and Binary Relevances in Audio-Text Relevance Learning
Aug 27, 2024
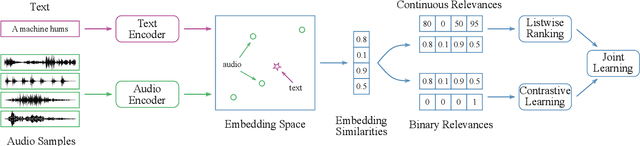
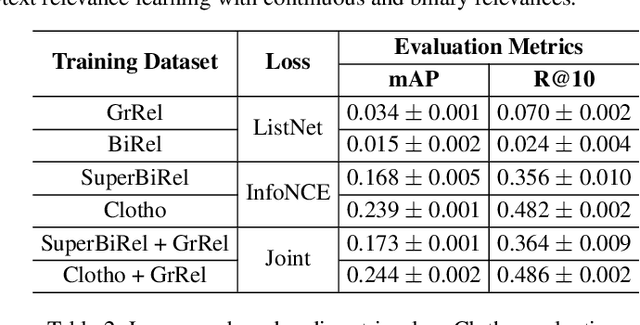
Audio-text relevance learning refers to learning the shared semantic properties of audio samples and textual descriptions. The standard approach uses binary relevances derived from pairs of audio samples and their human-provided captions, categorizing each pair as either positive or negative. This may result in suboptimal systems due to varying levels of relevance between audio samples and captions. In contrast, a recent study used human-assigned relevance ratings, i.e., continuous relevances, for these pairs but did not obtain performance gains in audio-text relevance learning. This work introduces a relevance learning method that utilizes both human-assigned continuous relevance ratings and binary relevances using a combination of a listwise ranking objective and a contrastive learning objective. Experimental results demonstrate the effectiveness of the proposed method, showing improvements in language-based audio retrieval, a downstream task in audio-text relevance learning. In addition, we analyze how properties of the captions or audio clips contribute to the continuous audio-text relevances provided by humans or learned by the machine.
A model of early word acquisition based on realistic-scale audiovisual naming events
Jun 07, 2024Infants gradually learn to parse continuous speech into words and connect names with objects, yet the mechanisms behind development of early word perception skills remain unknown. We studied the extent to which early words can be acquired through statistical learning from regularities in audiovisual sensory input. We simulated word learning in infants up to 12 months of age in a realistic setting, using a model that solely learns from statistical regularities in unannotated raw speech and pixel-level visual input. Crucially, the quantity of object naming events was carefully designed to match that accessible to infants of comparable ages. Results show that the model effectively learns to recognize words and associate them with corresponding visual objects, with a vocabulary growth rate comparable to that observed in infants. The findings support the viability of general statistical learning for early word perception, demonstrating how learning can operate without assuming any prior linguistic capabilities.
Age-Dependent Analysis and Stochastic Generation of Child-Directed Speech
May 13, 2024



Child-directed speech (CDS) is a particular type of speech that adults use when addressing young children. Its properties also change as a function of extralinguistic factors, such as age of the child being addressed. Access to large amounts of representative and varied CDS would be useful for child language research, as this would enable controlled computational modeling experiments of infant language acquisition with realistic input in terms of quality and quantity. In this study, we describe an approach to model age-dependent linguistic properties of CDS using a language model (LM) trained on CDS transcripts and ages of the recipient children, as obtained from North American English corpora of the CHILDES database. The created LM can then be used to stochastically generate synthetic CDS transcripts in an age-appropriate manner, thereby scaling beyond the original datasets in size. We compare characteristics of the generated CDS against the real speech addressed at children of different ages, showing that the LM manages to capture age-dependent changes in CDS, except for a slight difference in the effective vocabulary size. As a side product, we also provide a systematic characterization of age-dependent linguistic properties of CDS in CHILDES, illustrating how all measured aspects of the CDS change with children's age.
Crowdsourcing and Evaluating Text-Based Audio Retrieval Relevances
Jun 16, 2023This paper explores grading text-based audio retrieval relevances with crowdsourcing assessments. Given a free-form text (e.g., a caption) as a query, crowdworkers are asked to grade audio clips using numeric scores (between 0 and 100) to indicate their judgements of how much the sound content of an audio clip matches the text, where 0 indicates no content match at all and 100 indicates perfect content match. We integrate the crowdsourced relevances into training and evaluating text-based audio retrieval systems, and evaluate the effect of using them together with binary relevances from audio captioning. Conventionally, these binary relevances are defined by captioning-based audio-caption pairs, where being positive indicates that the caption describes the paired audio, and being negative applies to all other pairs. Experimental results indicate that there is no clear benefit from incorporating crowdsourced relevances alongside binary relevances when the crowdsourced relevances are binarized for contrastive learning. Conversely, the results suggest that using only binary relevances defined by captioning-based audio-caption pairs is sufficient for contrastive learning.
BabySLM: language-acquisition-friendly benchmark of self-supervised spoken language models
Jun 08, 2023
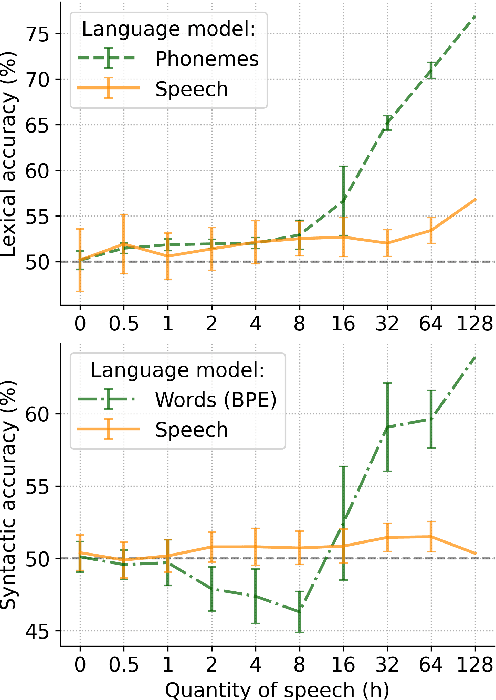
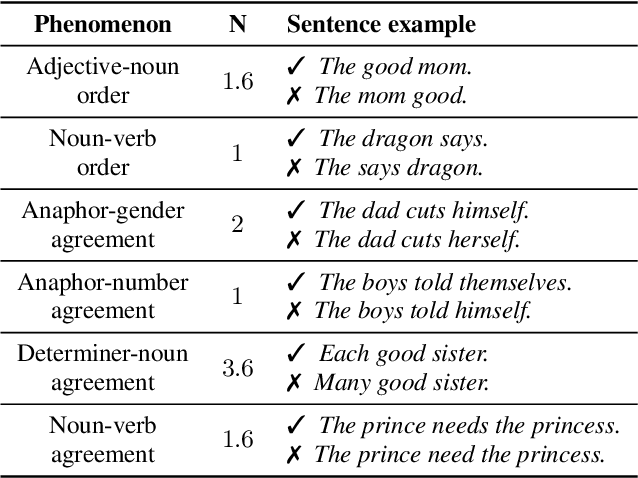
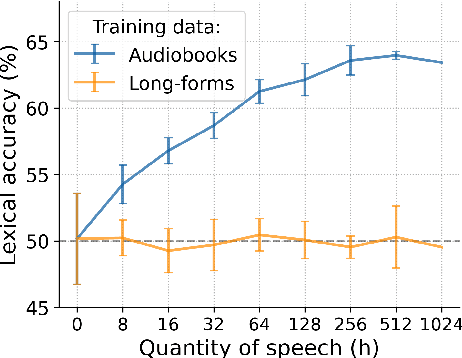
Self-supervised techniques for learning speech representations have been shown to develop linguistic competence from exposure to speech without the need for human labels. In order to fully realize the potential of these approaches and further our understanding of how infants learn language, simulations must closely emulate real-life situations by training on developmentally plausible corpora and benchmarking against appropriate test sets. To this end, we propose a language-acquisition-friendly benchmark to probe spoken language models at the lexical and syntactic levels, both of which are compatible with the vocabulary typical of children's language experiences. This paper introduces the benchmark and summarizes a range of experiments showing its usefulness. In addition, we highlight two exciting challenges that need to be addressed for further progress: bridging the gap between text and speech and between clean speech and in-the-wild speech.
Simultaneous or Sequential Training? How Speech Representations Cooperate in a Multi-Task Self-Supervised Learning System
Jun 05, 2023Speech representation learning with self-supervised algorithms has resulted in notable performance boosts in many downstream tasks. Recent work combined self-supervised learning (SSL) and visually grounded speech (VGS) processing mechanisms for representation learning. The joint training with SSL and VGS mechanisms provides the opportunity to utilize both unlabeled speech and speech-related visual information based on data availability. This has shown to enhance the quality of learned representations, especially at encoding semantic- and lexical-level knowledge. In this work, we further study the joint optimization of wav2vec 2.0-based SSL and transformer-based VGS as a multi-task learning system. We explore a set of training scenarios to understand how speech representations are shared or transferred between the two tasks, and what is the optimal training strategy for cross-modal semantic retrieval and phoneme discrimination performance. As a result, we find that sequential training with wav2vec 2.0 first and VGS next provides higher performance on audio-visual retrieval compared to simultaneous optimization of both learning mechanisms. However, the parallel SSL-VGS training reduces the effects of catastrophic forgetting when switching between optimization criteria. Moreover, the results suggest that phonemic representations learned through the VGS mechanism may generalize better across datasets compared to those learned with SSL.