 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-based Audio Retrieval by Learning from Similarities between Audio Captions
Paper and Code
Dec 02, 2024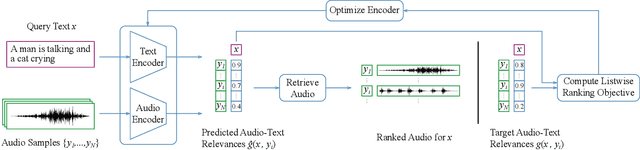

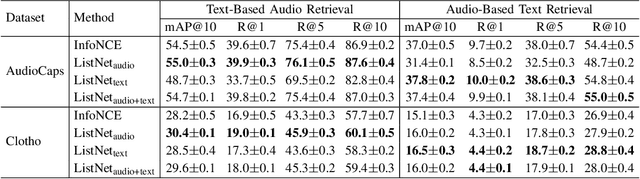
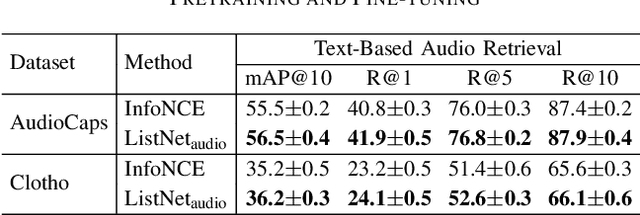
This paper proposes to use similarities of audio captions for estimating audio-caption relevances to be used for training text-based audio retrieval systems. Current audio-caption datasets (e.g., Clotho) contain audio samples paired with annotated captions, but lack relevance information about audio samples and captions beyond the annotated ones. Besides, mainstream approaches (e.g., CLAP) usually treat the annotated pairs as positives and consider all other audio-caption combinations as negatives, assuming a binary relevance between audio samples and captions. To infer the relevance between audio samples and arbitrary captions, we propose a method that computes non-binary audio-caption relevance scores based on the textual similarities of audio captions. We measure textual similarities of audio captions by calculating the cosine similarity of their Sentence-BERT embeddings and then transform these similarities into audio-caption relevance scores using a logistic function, thereby linking audio samples through their annotated captions to all other captions in the dataset. To integrate the computed relevances into training, we employ a listwise ranking objective, where relevance scores are converted into probabilities of ranking audio samples for a given textual query. We show the effectiveness of the proposed method by demonstrating improvements in text-based audio retrieval compared to methods that use binary audio-caption relevances for training.