 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-based Audio Retrieval by Learning from Similarities between Audio Captions
Dec 02, 2024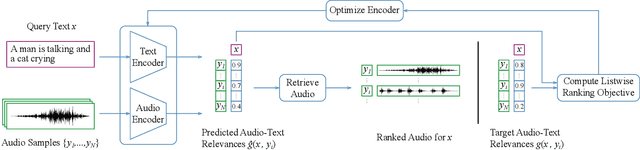

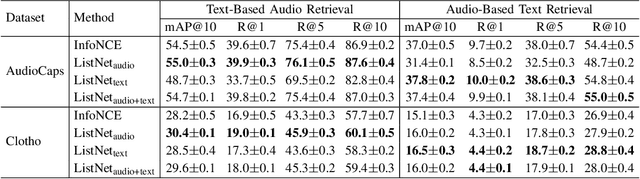
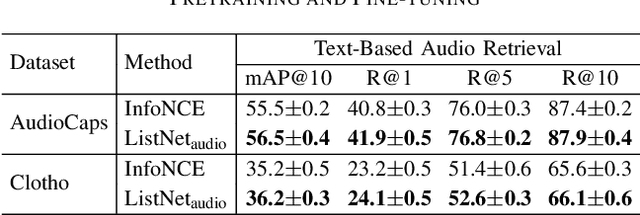
This paper proposes to use similarities of audio captions for estimating audio-caption relevances to be used for training text-based audio retrieval systems. Current audio-caption datasets (e.g., Clotho) contain audio samples paired with annotated captions, but lack relevance information about audio samples and captions beyond the annotated ones. Besides, mainstream approaches (e.g., CLAP) usually treat the annotated pairs as positives and consider all other audio-caption combinations as negatives, assuming a binary relevance between audio samples and captions. To infer the relevance between audio samples and arbitrary captions, we propose a method that computes non-binary audio-caption relevance scores based on the textual similarities of audio captions. We measure textual similarities of audio captions by calculating the cosine similarity of their Sentence-BERT embeddings and then transform these similarities into audio-caption relevance scores using a logistic function, thereby linking audio samples through their annotated captions to all other captions in the dataset. To integrate the computed relevances into training, we employ a listwise ranking objective, where relevance scores are converted into probabilities of ranking audio samples for a given textual query. We show the effectiveness of the proposed method by demonstrating improvements in text-based audio retrieval compared to methods that use binary audio-caption relevances for training.
Multi-label Zero-Shot Audio Classification with Temporal Attention
Aug 31, 2024Zero-shot learning models are capable of classifying new classes by transferring knowledge from the seen classes using auxiliary information. While most of the existing zero-shot learning methods focused on single-label classification tasks, the present study introduces a method to perform multi-label zero-shot audio classification. To address the challenge of classifying multi-label sounds while generalizing to unseen classes, we adapt temporal attention. The temporal attention mechanism assigns importance weights to different audio segments based on their acoustic and semantic compatibility, thus enabling the model to capture the varying dominance of different sound classes within an audio sample by focusing on the segments most relevant for each class. This leads to more accurate multi-label zero-shot classification than methods employing temporally aggregated acoustic features without weighting, which treat all audio segments equally. We evaluate our approach on a subset of AudioSet against a zero-shot model using uniformly aggregated acoustic features, a zero-rule baseline, and the proposed method in the supervised scenario. Our results show that temporal attention enhances the zero-shot audio classification performance in multi-label scenario.
Integrating Continuous and Binary Relevances in Audio-Text Relevance Learning
Aug 27, 2024
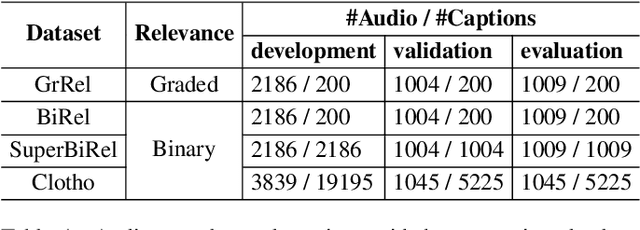
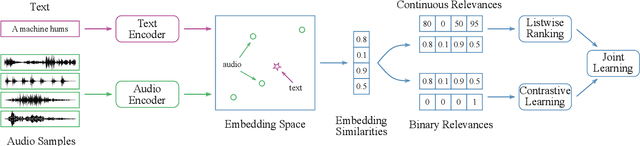
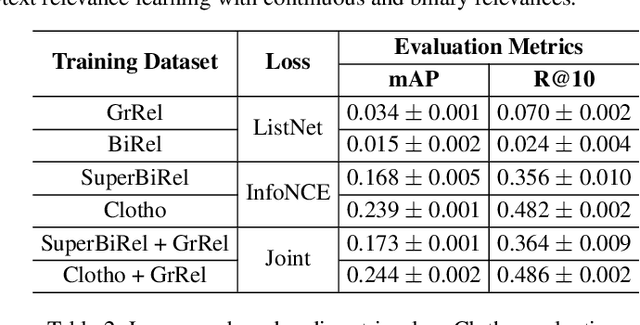
Audio-text relevance learning refers to learning the shared semantic properties of audio samples and textual descriptions. The standard approach uses binary relevances derived from pairs of audio samples and their human-provided captions, categorizing each pair as either positive or negative. This may result in suboptimal systems due to varying levels of relevance between audio samples and captions. In contrast, a recent study used human-assigned relevance ratings, i.e., continuous relevances, for these pairs but did not obtain performance gains in audio-text relevance learning. This work introduces a relevance learning method that utilizes both human-assigned continuous relevance ratings and binary relevances using a combination of a listwise ranking objective and a contrastive learning objective. Experimental results demonstrate the effectiveness of the proposed method, showing improvements in language-based audio retrieval, a downstream task in audio-text relevance learning. In addition, we analyze how properties of the captions or audio clips contribute to the continuous audio-text relevances provided by humans or learned by the machine.
Crowdsourcing and Evaluating Text-Based Audio Retrieval Relevances
Jun 16, 2023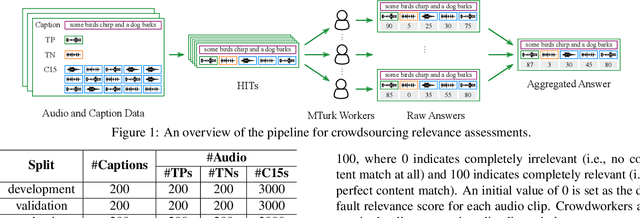
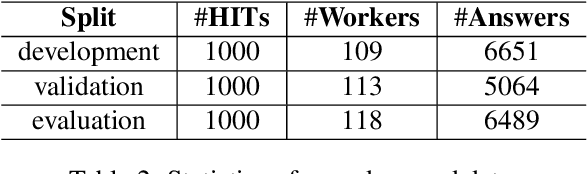
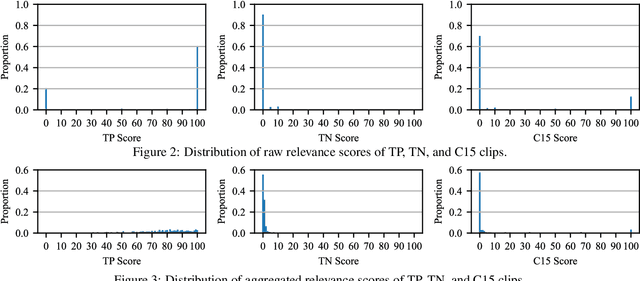
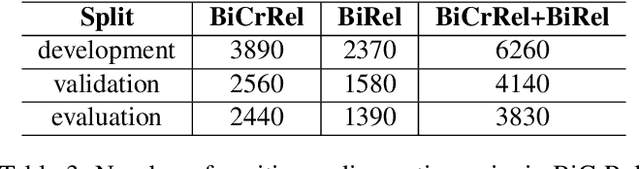
This paper explores grading text-based audio retrieval relevances with crowdsourcing assessments. Given a free-form text (e.g., a caption) as a query, crowdworkers are asked to grade audio clips using numeric scores (between 0 and 100) to indicate their judgements of how much the sound content of an audio clip matches the text, where 0 indicates no content match at all and 100 indicates perfect content match. We integrate the crowdsourced relevances into training and evaluating text-based audio retrieval systems, and evaluate the effect of using them together with binary relevances from audio captioning. Conventionally, these binary relevances are defined by captioning-based audio-caption pairs, where being positive indicates that the caption describes the paired audio, and being negative applies to all other pairs. Experimental results indicate that there is no clear benefit from incorporating crowdsourced relevances alongside binary relevances when the crowdsourced relevances are binarized for contrastive learning. Conversely, the results suggest that using only binary relevances defined by captioning-based audio-caption pairs is sufficient for contrastive learning.
On Negative Sampling for Contrastive Audio-Text Retrieval
Nov 08, 2022This paper investigates negative sampling for contrastive learning in the context of audio-text retrieval. The strategy for negative sampling refers to selecting negatives (either audio clips or textual descriptions) from a pool of candidates for a positive audio-text pair. We explore sampling strategies via model-estimated within-modality and cross-modality relevance scores for audio and text samples. With a constant training setting on the retrieval system from [1], we study eight sampling strategies, including hard and semi-hard negative sampling. Experimental results show that retrieval performance varies dramatically among different strategies. Particularly, by selecting semi-hard negatives with cross-modality scores, the retrieval system gains improved performance in both text-to-audio and audio-to-text retrieval. Besides, we show that feature collapse occurs while sampling hard negatives with cross-modality scores.
Language-based Audio Retrieval Task in DCASE 2022 Challenge
Oct 04, 2022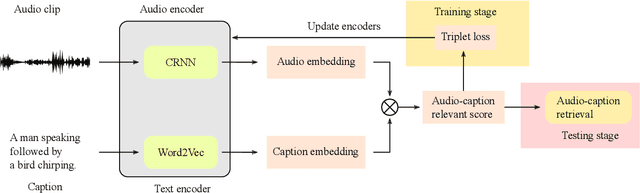
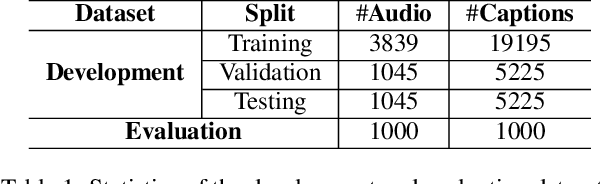
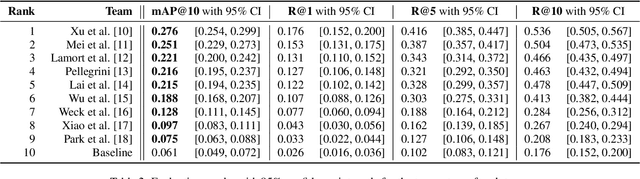
Language-based audio retrieval is a task, where natural language textual captions are used as queries to retrieve audio signals from a dataset. It has been first introduced into DCASE 2022 Challenge as Subtask 6B of task 6, which aims at developing computational systems to model relationships between audio signals and free-form textual descriptions. Compared with audio captioning (Subtask 6A), which is about generating audio captions for audio signals, language-based audio retrieval (Subtask 6B) focuses on ranking audio signals according to their relevance to natural language textual captions. In DCASE 2022 Challenge, the provided baseline system for Subtask 6B was significantly outperformed, with top performance being 0.276 in mAP@10. This paper presents the outcome of Subtask 6B in terms of submitted systems' performance and analysis.
DCASE 2022 Challenge Task 6B: Language-Based Audio Retrieval
Jun 15, 2022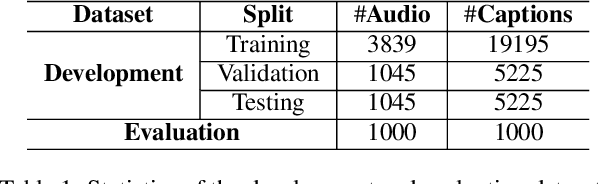
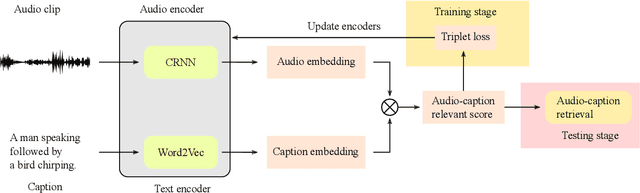

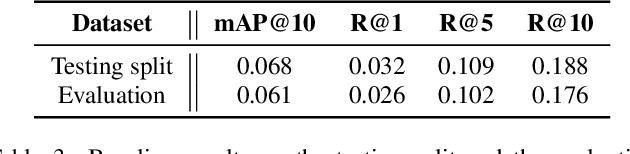
In this report, we introduce the task setup and the baseline system for the sub-task B of the DCASE 2022 Challenge Task 6: language-based audio retrieval subtask. For this subtask, the Clotho v2 dataset is utilized as the development dataset, and an additional dataset consisting of 1,000 audio-caption pairs as the evaluation dataset. We train the baseline system with the development dataset, and evaluate it on the evaluation dataset to provide some initial results for this subtask.
Zero-Shot Audio Classification using Image Embeddings
Jun 10, 2022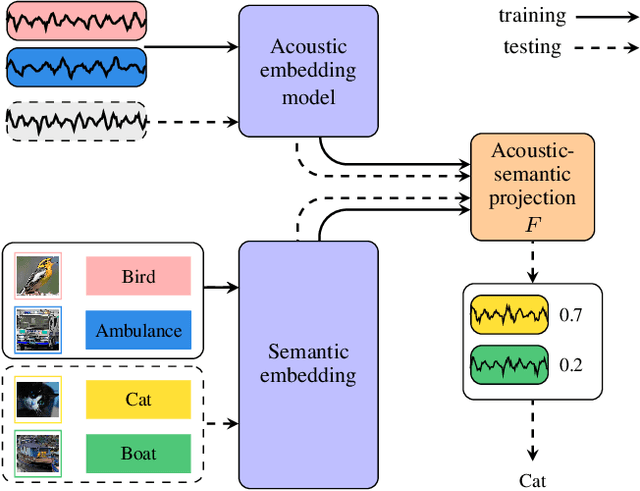
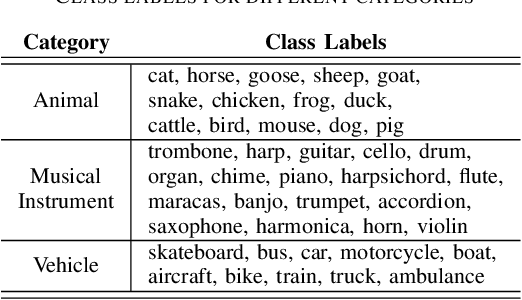
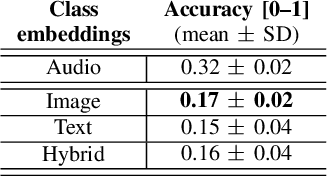
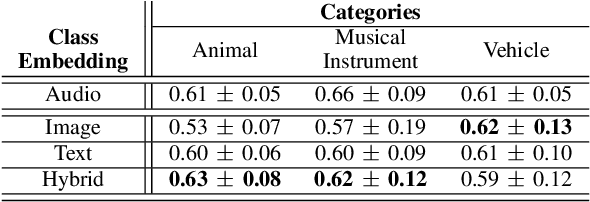
Supervised learning methods can solve the given problem in the presence of a large set of labeled data. However, the acquisition of a dataset covering all the target classes typically requires manual labeling which is expensive and time-consuming. Zero-shot learning models are capable of classifying the unseen concepts by utilizing their semantic information. The present study introduces image embeddings as side information on zero-shot audio classification by using a nonlinear acoustic-semantic projection. We extract the semantic image representations from the Open Images dataset and evaluate the performance of the models on an audio subset of AudioSet using semantic information in different domains; image, audio, and textual. We demonstrate that the image embeddings can be used as semantic information to perform zero-shot audio classification. The experimental results show that the image and textual embeddings display similar performance both individually and together. We additionally calculate the semantic acoustic embeddings from the test samples to provide an upper limit to the performance. The results show that the classification performance is highly sensitive to the semantic relation between test and training classes and textual and image embeddings can reach up to the semantic acoustic embeddings when the seen and unseen classes are semantically similar.
Unsupervised Audio-Caption Aligning Learns Correspondences between Individual Sound Events and Textual Phrases
Oct 06, 2021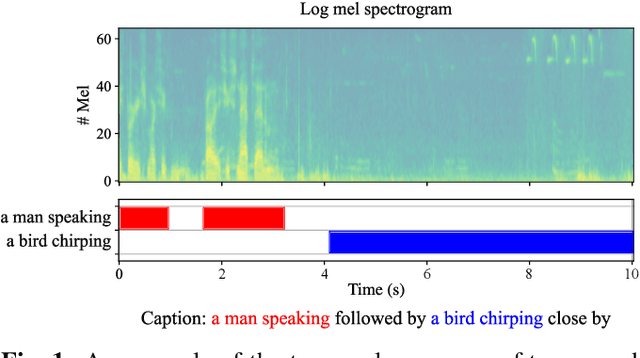
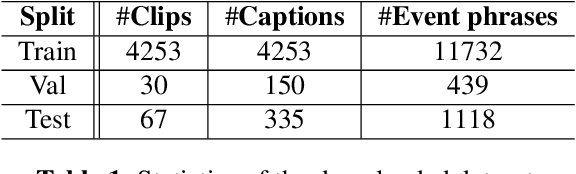
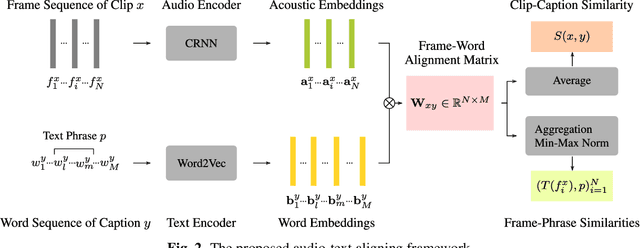
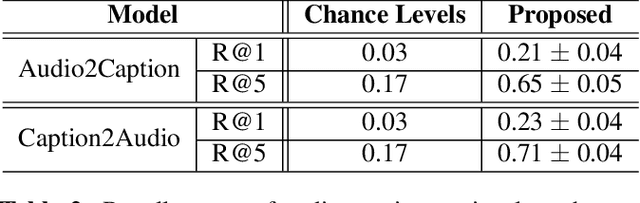
We investigate unsupervised learning of correspondences between sound events and textual phrases through aligning audio clips with textual captions describing the content of a whole audio clip. We align originally unaligned and unannotated audio clips and their captions by scoring the similarities between audio frames and words, as encoded by modality-specific encoders and using a ranking-loss criterion to optimize the model. After training, we obtain clip-caption similarity by averaging frame-word similarities and estimate event-phrase correspondences by calculating frame-phrase similarities. We evaluate the method with two cross-modal tasks: audio-caption retrieval, and phrase-based sound event detection (SED). Experimental results show that the proposed method can globally associate audio clips with captions as well as locally learn correspondences between individual sound events and textual phrases in an unsupervised manner.
Zero-Shot Audio Classification Based on Class Label Embeddings
May 06, 2019
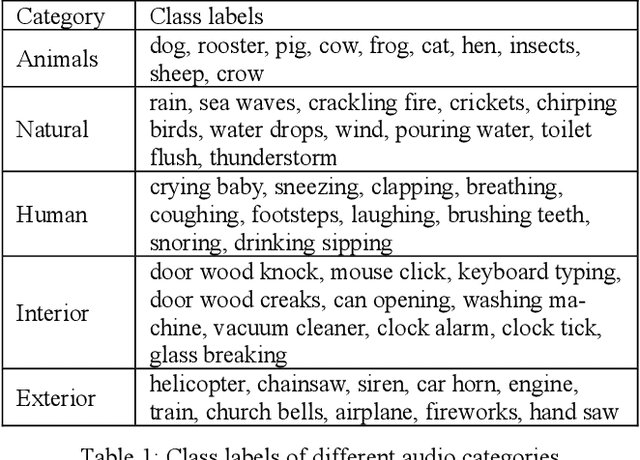
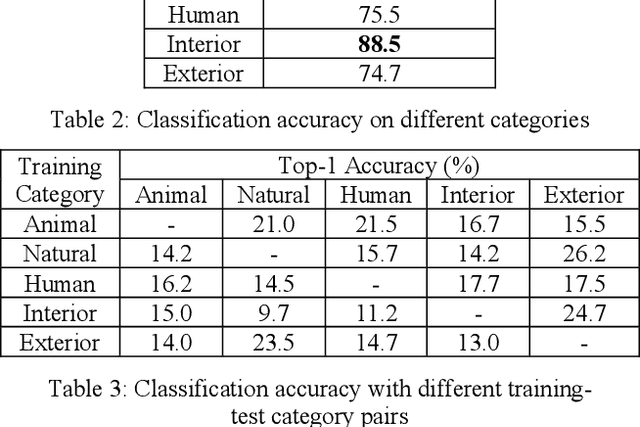
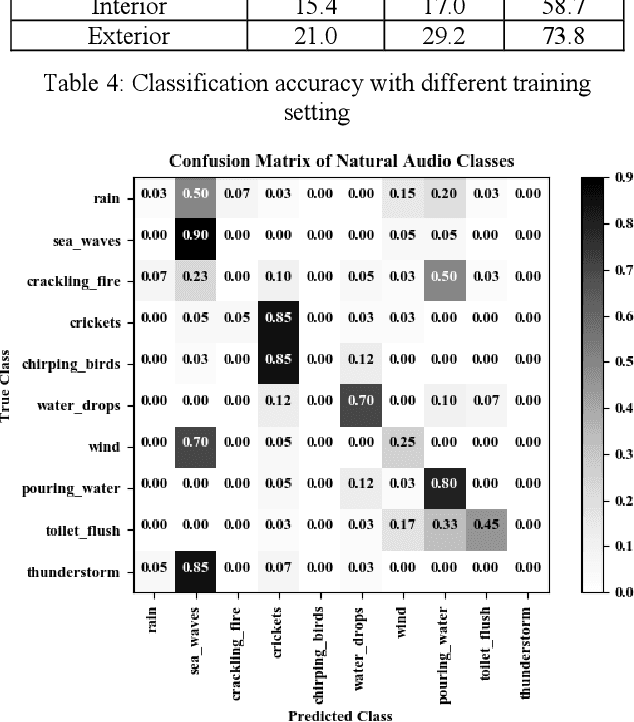
This paper proposes a zero-shot learning approach for audio classification based on the textual information about class labels without any audio samples from target classes. We propose an audio classification system built on the bilinear model, which takes audio feature embeddings and semantic class label embeddings as input, and measures the compatibility between an audio feature embedding and a class label embedding. We use VGGish to extract audio feature embeddings from audio recordings. We treat textual labels as semantic side information of audio classes, and use Word2Vec to generate class label embeddings. Results on the ESC-50 dataset show that the proposed system can perform zero-shot audio classification with small training dataset. It can achieve accuracy (26 % on average) better than random guess (10 %) on each audio category. Particularly, it reaches up to 39.7 % for the category of natural audio classes.