 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-based Audio Retrieval by Learning from Similarities between Audio Captions
Dec 02, 2024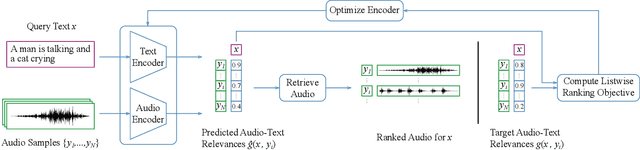

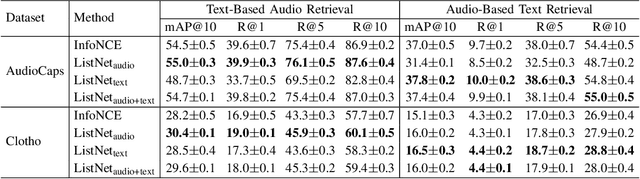
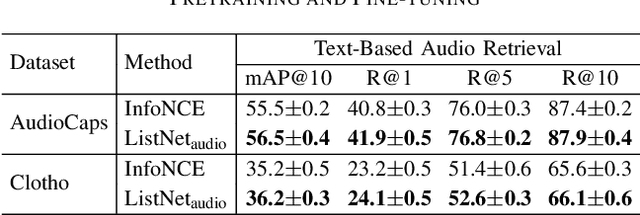
This paper proposes to use similarities of audio captions for estimating audio-caption relevances to be used for training text-based audio retrieval systems. Current audio-caption datasets (e.g., Clotho) contain audio samples paired with annotated captions, but lack relevance information about audio samples and captions beyond the annotated ones. Besides, mainstream approaches (e.g., CLAP) usually treat the annotated pairs as positives and consider all other audio-caption combinations as negatives, assuming a binary relevance between audio samples and captions. To infer the relevance between audio samples and arbitrary captions, we propose a method that computes non-binary audio-caption relevance scores based on the textual similarities of audio captions. We measure textual similarities of audio captions by calculating the cosine similarity of their Sentence-BERT embeddings and then transform these similarities into audio-caption relevance scores using a logistic function, thereby linking audio samples through their annotated captions to all other captions in the dataset. To integrate the computed relevances into training, we employ a listwise ranking objective, where relevance scores are converted into probabilities of ranking audio samples for a given textual query. We show the effectiveness of the proposed method by demonstrating improvements in text-based audio retrieval compared to methods that use binary audio-caption relevances for training.
Integrating Continuous and Binary Relevances in Audio-Text Relevance Learning
Aug 27, 2024
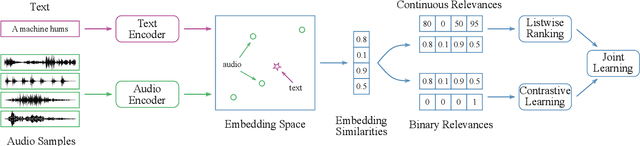
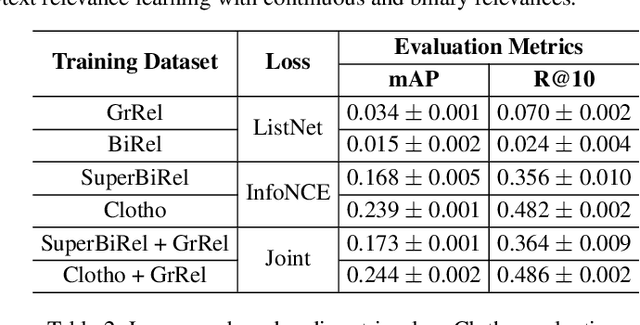
Audio-text relevance learning refers to learning the shared semantic properties of audio samples and textual descriptions. The standard approach uses binary relevances derived from pairs of audio samples and their human-provided captions, categorizing each pair as either positive or negative. This may result in suboptimal systems due to varying levels of relevance between audio samples and captions. In contrast, a recent study used human-assigned relevance ratings, i.e., continuous relevances, for these pairs but did not obtain performance gains in audio-text relevance learning. This work introduces a relevance learning method that utilizes both human-assigned continuous relevance ratings and binary relevances using a combination of a listwise ranking objective and a contrastive learning objective. Experimental results demonstrate the effectiveness of the proposed method, showing improvements in language-based audio retrieval, a downstream task in audio-text relevance learning. In addition, we analyze how properties of the captions or audio clips contribute to the continuous audio-text relevances provided by humans or learned by the machine.
A model of early word acquisition based on realistic-scale audiovisual naming events
Jun 07, 2024



Infants gradually learn to parse continuous speech into words and connect names with objects, yet the mechanisms behind development of early word perception skills remain unknown. We studied the extent to which early words can be acquired through statistical learning from regularities in audiovisual sensory input. We simulated word learning in infants up to 12 months of age in a realistic setting, using a model that solely learns from statistical regularities in unannotated raw speech and pixel-level visual input. Crucially, the quantity of object naming events was carefully designed to match that accessible to infants of comparable ages. Results show that the model effectively learns to recognize words and associate them with corresponding visual objects, with a vocabulary growth rate comparable to that observed in infants. The findings support the viability of general statistical learning for early word perception, demonstrating how learning can operate without assuming any prior linguistic capabilities.
Crowdsourcing and Evaluating Text-Based Audio Retrieval Relevances
Jun 16, 2023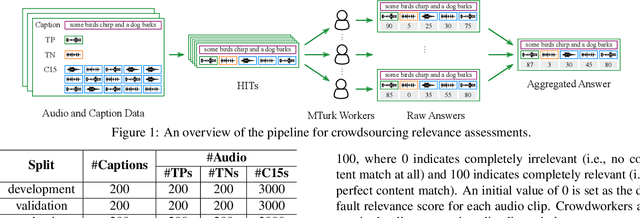
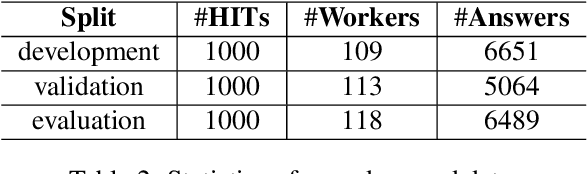
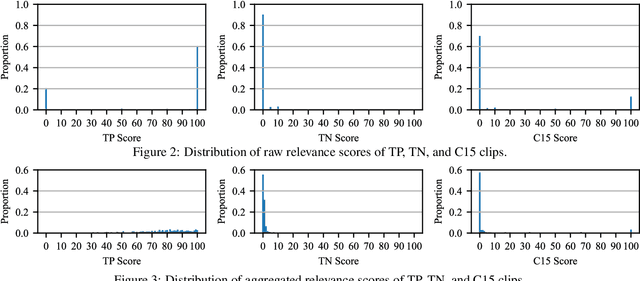
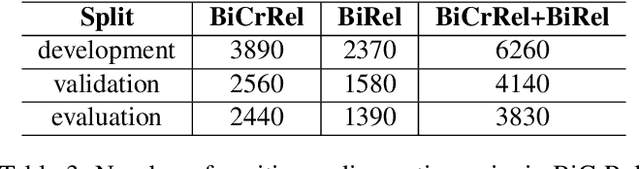
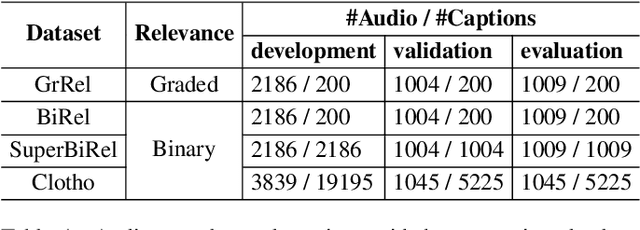
This paper explores grading text-based audio retrieval relevances with crowdsourcing assessments. Given a free-form text (e.g., a caption) as a query, crowdworkers are asked to grade audio clips using numeric scores (between 0 and 100) to indicate their judgements of how much the sound content of an audio clip matches the text, where 0 indicates no content match at all and 100 indicates perfect content match. We integrate the crowdsourced relevances into training and evaluating text-based audio retrieval systems, and evaluate the effect of using them together with binary relevances from audio captioning. Conventionally, these binary relevances are defined by captioning-based audio-caption pairs, where being positive indicates that the caption describes the paired audio, and being negative applies to all other pairs. Experimental results indicate that there is no clear benefit from incorporating crowdsourced relevances alongside binary relevances when the crowdsourced relevances are binarized for contrastive learning. Conversely, the results suggest that using only binary relevances defined by captioning-based audio-caption pairs is sufficient for contrastive learning.
Simultaneous or Sequential Training? How Speech Representations Cooperate in a Multi-Task Self-Supervised Learning System
Jun 05, 2023Speech representation learning with self-supervised algorithms has resulted in notable performance boosts in many downstream tasks. Recent work combined self-supervised learning (SSL) and visually grounded speech (VGS) processing mechanisms for representation learning. The joint training with SSL and VGS mechanisms provides the opportunity to utilize both unlabeled speech and speech-related visual information based on data availability. This has shown to enhance the quality of learned representations, especially at encoding semantic- and lexical-level knowledge. In this work, we further study the joint optimization of wav2vec 2.0-based SSL and transformer-based VGS as a multi-task learning system. We explore a set of training scenarios to understand how speech representations are shared or transferred between the two tasks, and what is the optimal training strategy for cross-modal semantic retrieval and phoneme discrimination performance. As a result, we find that sequential training with wav2vec 2.0 first and VGS next provides higher performance on audio-visual retrieval compared to simultaneous optimization of both learning mechanisms. However, the parallel SSL-VGS training reduces the effects of catastrophic forgetting when switching between optimization criteria. Moreover, the results suggest that phonemic representations learned through the VGS mechanism may generalize better across datasets compared to those learned with SSL.
Can phones, syllables, and words emerge as side-products of cross-situational audiovisual learning? -- A computational investigation
Sep 29, 2021



Decades of research has studied how language learning infants learn to discriminate speech sounds, segment words, and associate words with their meanings. While gradual development of such capabilities is unquestionable, the exact nature of these skills and the underlying mental representations yet remains unclear. In parallel, computational studies have shown that basic comprehension of speech can be achieved by statistical learning between speech and concurrent referentially ambiguous visual input. These models can operate without prior linguistic knowledge such as representations of linguistic units, and without learning mechanisms specifically targeted at such units. This has raised the question of to what extent knowledge of linguistic units, such as phone(me)s, syllables, and words, could actually emerge as latent representations supporting the translation between speech and representations in other modalities, and without the units being proximal learning targets for the learner. In this study, we formulate this idea as the so-called latent language hypothesis (LLH), connecting linguistic representation learning to general predictive processing within and across sensory modalities. We review the extent that the audiovisual aspect of LLH is supported by the existing computational studies. We then explore LLH further in extensive learning simulations with different neural network models for audiovisual cross-situational learning, and comparing learning from both synthetic and real speech data. We investigate whether the latent representations learned by the networks reflect phonetic, syllabic, or lexical structure of input speech by utilizing an array of complementary evaluation metrics related to linguistic selectivity and temporal characteristics of the representations. As a result, we find that representations associated...
* Final manuscript published in Language Development Research under CC BY-NC-SA 4.0. Pre-print redistributed through arXiv with permission. Replaces corrupted PsyArXiv pre-print repository at https://psyarxiv.com/37zna
A computational model of early language acquisition from audiovisual experiences of young infants
Jun 24, 2019

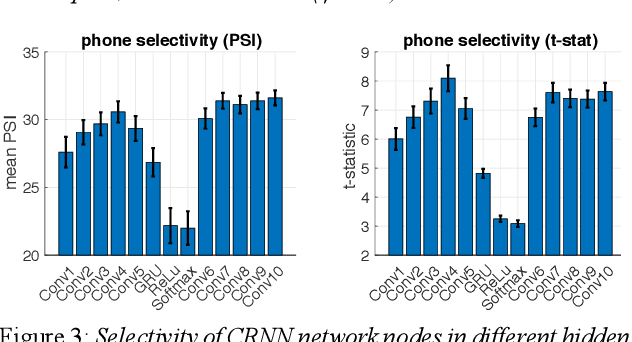
Earlier research has suggested that human infants might use statistical dependencies between speech and non-linguistic multimodal input to bootstrap their language learning before they know how to segment words from running speech. However, feasibility of this hypothesis in terms of real-world infant experiences has remained unclear. This paper presents a step towards a more realistic test of the multimodal bootstrapping hypothesis by describing a neural network model that can learn word segments and their meanings from referentially ambiguous acoustic input. The model is tested on recordings of real infant-caregiver interactions using utterance-level labels for concrete visual objects that were attended by the infant when caregiver spoke an utterance containing the name of the object, and using random visual labels for utterances during absence of attention. The results show that beginnings of lexical knowledge may indeed emerge from individually ambiguous learning scenarios. In addition, the hidden layers of the network show gradually increasing selectivity to phonetic categories as a function of layer depth, resembling models trained for phone recognition in a supervised manner.