 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEMERAG: A Multilingual End-to-End Meta-Evaluation Benchmark for Retrieval Augmented Generation
Feb 25, 2025Automatic evaluation of retrieval augmented generation (RAG) systems relies on fine-grained dimensions like faithfulness and relevance, as judged by expert human annotators. Meta-evaluation benchmarks support the development of automatic evaluators that correlate well with human judgement. However, existing benchmarks predominantly focus on English or use translated data, which fails to capture cultural nuances. A native approach provides a better representation of the end user experience. In this work, we develop a Multilingual End-to-end Meta-Evaluation RAG benchmark (MEMERAG). Our benchmark builds on the popular MIRACL dataset, using native-language questions and generating responses with diverse large language models (LLMs), which are then assessed by expert annotators for faithfulness and relevance. We describe our annotation process and show that it achieves high inter-annotator agreement. We then analyse the performance of the answer-generating LLMs across languages as per the human evaluators. Finally we apply the dataset to our main use-case which is to benchmark multilingual automatic evaluators (LLM-as-a-judge). We show that our benchmark can reliably identify improvements offered by advanced prompting techniques and LLMs. We will release our benchmark to support the community developing accurate evaluation methods for multilingual RAG systems.
BabySLM: language-acquisition-friendly benchmark of self-supervised spoken language models
Jun 08, 2023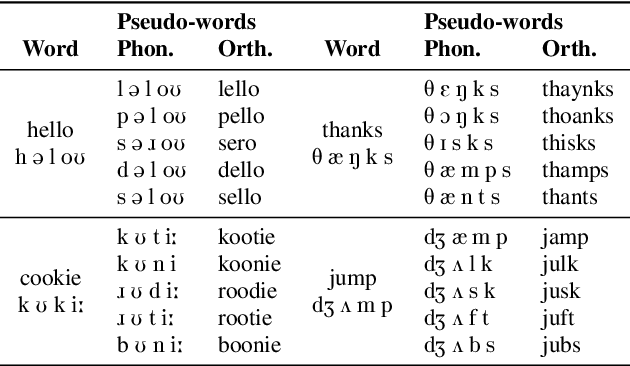
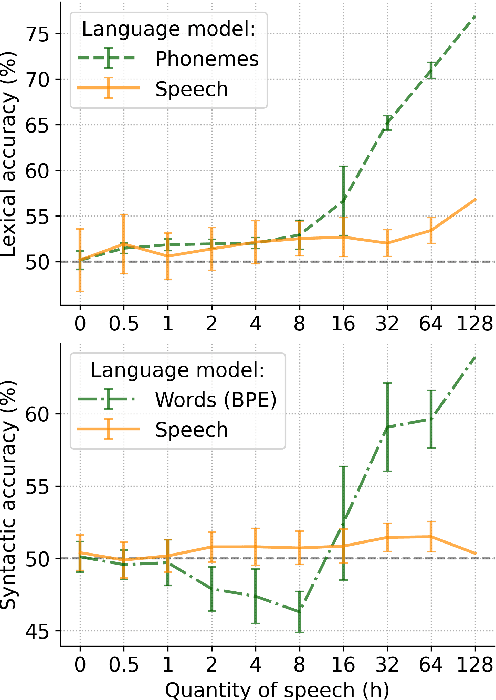
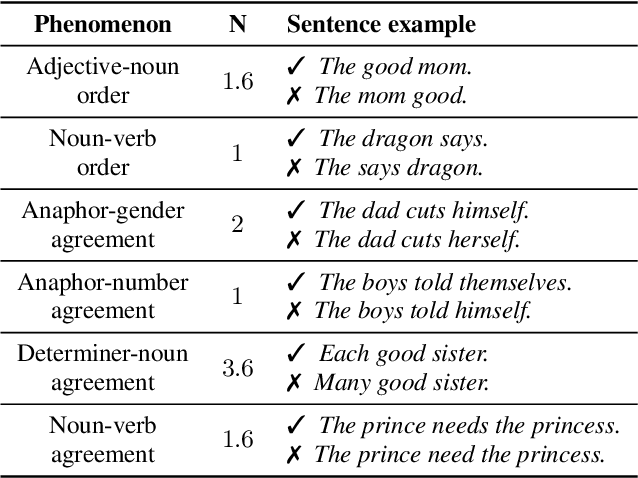
Self-supervised techniques for learning speech representations have been shown to develop linguistic competence from exposure to speech without the need for human labels. In order to fully realize the potential of these approaches and further our understanding of how infants learn language, simulations must closely emulate real-life situations by training on developmentally plausible corpora and benchmarking against appropriate test sets. To this end, we propose a language-acquisition-friendly benchmark to probe spoken language models at the lexical and syntactic levels, both of which are compatible with the vocabulary typical of children's language experiences. This paper introduces the benchmark and summarizes a range of experiments showing its usefulness. In addition, we highlight two exciting challenges that need to be addressed for further progress: bridging the gap between text and speech and between clean speech and in-the-wild speech.
Simultaneous or Sequential Training? How Speech Representations Cooperate in a Multi-Task Self-Supervised Learning System
Jun 05, 2023Speech representation learning with self-supervised algorithms has resulted in notable performance boosts in many downstream tasks. Recent work combined self-supervised learning (SSL) and visually grounded speech (VGS) processing mechanisms for representation learning. The joint training with SSL and VGS mechanisms provides the opportunity to utilize both unlabeled speech and speech-related visual information based on data availability. This has shown to enhance the quality of learned representations, especially at encoding semantic- and lexical-level knowledge. In this work, we further study the joint optimization of wav2vec 2.0-based SSL and transformer-based VGS as a multi-task learning system. We explore a set of training scenarios to understand how speech representations are shared or transferred between the two tasks, and what is the optimal training strategy for cross-modal semantic retrieval and phoneme discrimination performance. As a result, we find that sequential training with wav2vec 2.0 first and VGS next provides higher performance on audio-visual retrieval compared to simultaneous optimization of both learning mechanisms. However, the parallel SSL-VGS training reduces the effects of catastrophic forgetting when switching between optimization criteria. Moreover, the results suggest that phonemic representations learned through the VGS mechanism may generalize better across datasets compared to those learned with SSL.
Analysing the Impact of Audio Quality on the Use of Naturalistic Long-Form Recordings for Infant-Directed Speech Research
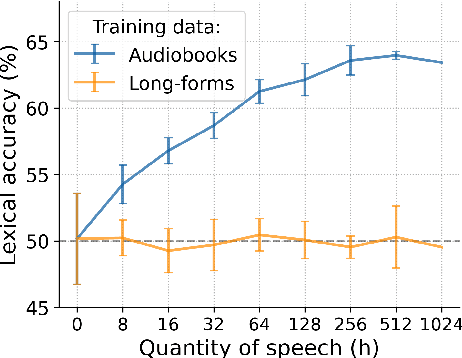
May 03, 2023Modelling of early language acquisition aims to understand how infants bootstrap their language skills. The modelling encompasses properties of the input data used for training the models, the cognitive hypotheses and their algorithmic implementations being tested, and the evaluation methodologies to compare models to human data. Recent developments have enabled the use of more naturalistic training data for computational models. This also motivates development of more naturalistic tests of model behaviour. A crucial step towards such an aim is to develop representative speech datasets consisting of speech heard by infants in their natural environments. However, a major drawback of such recordings is that they are typically noisy, and it is currently unclear how the sound quality could affect analyses and modelling experiments conducted on such data. In this paper, we explore this aspect for the case of infant-directed speech (IDS) and adult-directed speech (ADS) analysis. First, we manually and automatically annotated audio quality of utterances extracted from two corpora of child-centred long-form recordings (in English and French). We then compared acoustic features of IDS and ADS in an in-lab dataset and across different audio quality subsets of naturalistic data. Finally, we assessed how the audio quality and recording environment may change the conclusions of a modelling analysis using a recent self-supervised learning model. Our results show that the use of modest and high audio quality naturalistic speech data result in largely similar conclusions on IDS and ADS in terms of acoustic analyses and modelling experiments. We also found that an automatic sound quality assessment tool can be used to screen out useful parts of long-form recordings for a closer analysis with comparable results to that of manual quality annotation.
Unsupervised Discovery of Recurring Speech Patterns Using Probabilistic Adaptive Metrics
Aug 03, 2020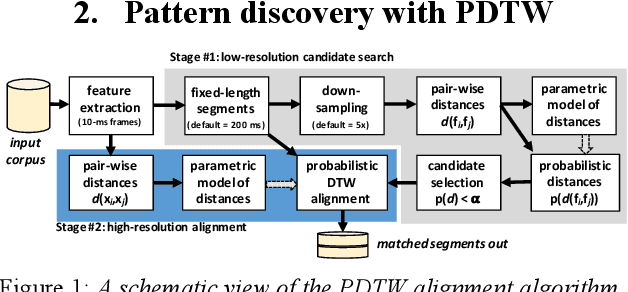
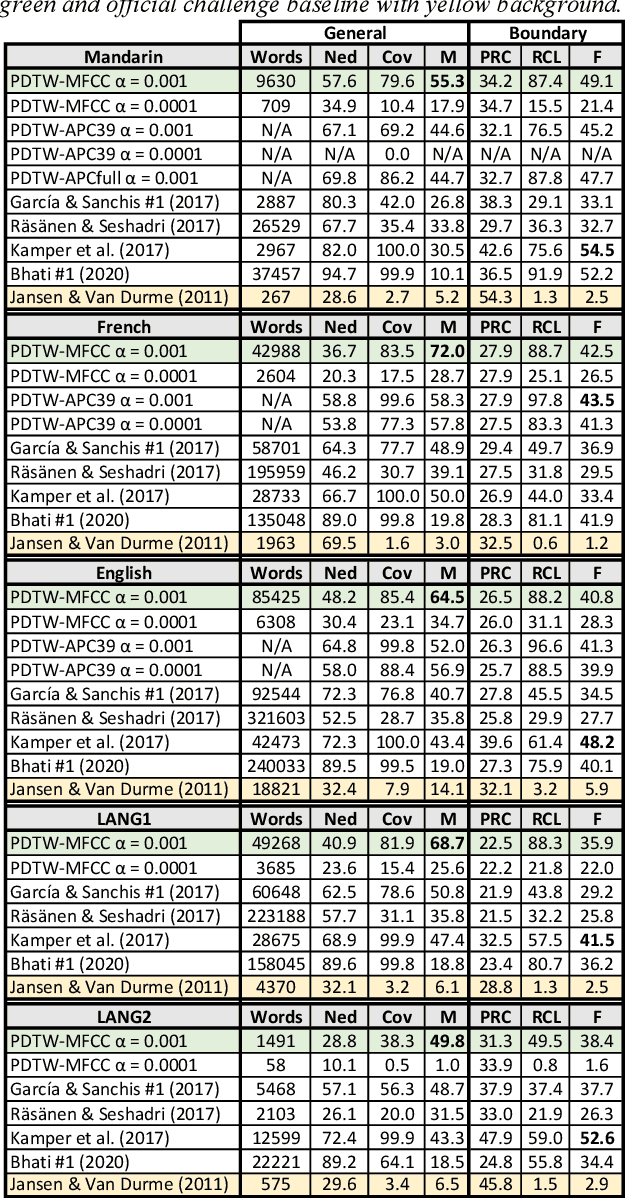
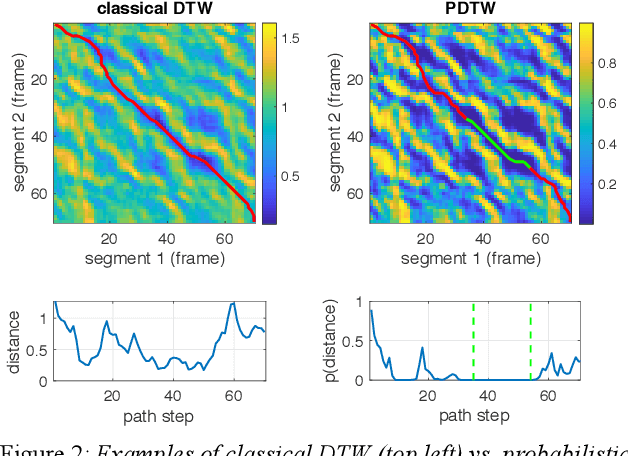
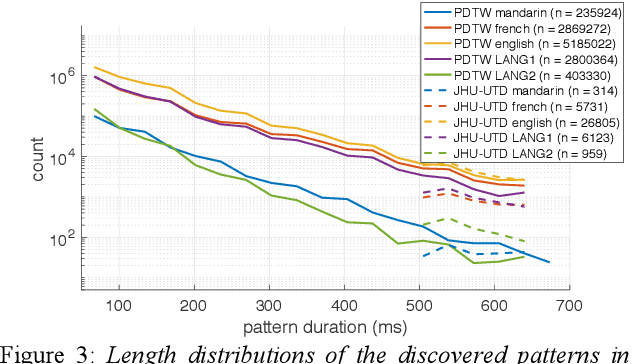
Unsupervised spoken term discovery (UTD) aims at finding recurring segments of speech from a corpus of acoustic speech data. One potential approach to this problem is to use dynamic time warping (DTW) to find well-aligning patterns from the speech data. However, automatic selection of initial candidate segments for the DTW-alignment and detection of "sufficiently good" alignments among those require some type of pre-defined criteria, often operationalized as threshold parameters for pair-wise distance metrics between signal representations. In the existing UTD systems, the optimal hyperparameters may differ across datasets, limiting their applicability to new corpora and truly low-resource scenarios. In this paper, we propose a novel probabilistic approach to DTW-based UTD named as PDTW. In PDTW, distributional characteristics of the processed corpus are utilized for adaptive evaluation of alignment quality, thereby enabling systematic discovery of pattern pairs that have similarity what would be expected by coincidence. We test PDTW on Zero Resource Speech Challenge 2017 datasets as a part of 2020 implementation of the challenge. The results show that the system performs consistently on all five tested languages using fixed hyperparameters, clearly outperforming the earlier DTW-based system in terms of coverage of the detected patterns.
Analysis of Predictive Coding Models for Phonemic Representation Learning in Small Datasets
Jul 08, 2020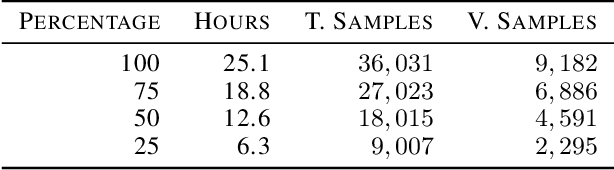
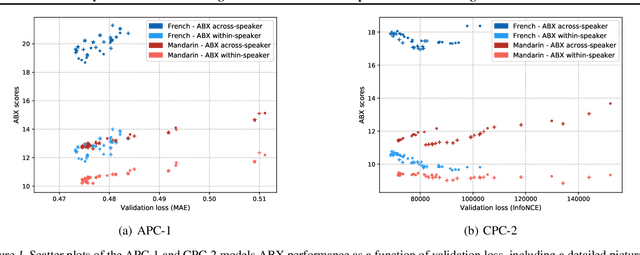
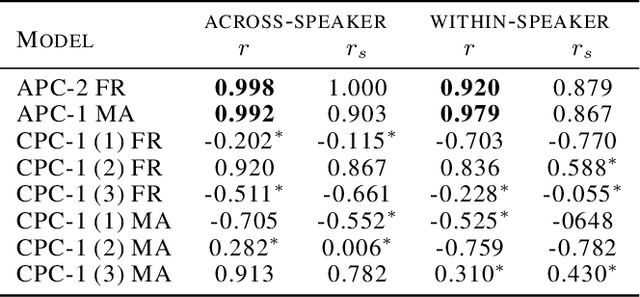
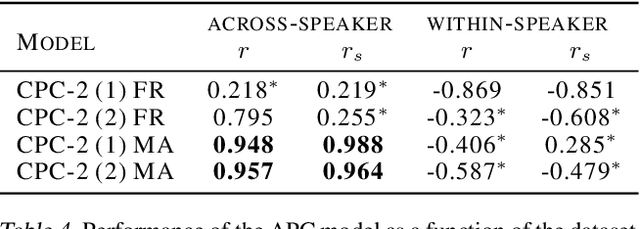
Neural network models using predictive coding are interesting from the viewpoint of computational modelling of human language acquisition, where the objective is to understand how linguistic units could be learned from speech without any labels. Even though several promising predictive coding -based learning algorithms have been proposed in the literature, it is currently unclear how well they generalise to different languages and training dataset sizes. In addition, despite that such models have shown to be effective phonemic feature learners, it is unclear whether minimisation of the predictive loss functions of these models also leads to optimal phoneme-like representations. The present study investigates the behaviour of two predictive coding models, Autoregressive Predictive Coding and Contrastive Predictive Coding, in a phoneme discrimination task (ABX task) for two languages with different dataset sizes. Our experiments show a strong correlation between the autoregressive loss and the phoneme discrimination scores with the two datasets. However, to our surprise, the CPC model shows rapid convergence already after one pass over the training data, and, on average, its representations outperform those of APC on both languages.