 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-aware child-directed speech detection from long-form recordings
May 31, 2026Automatically distinguishing child-directed speech from adult-directed speech in long-form recordings is key to scalable analyses of children's language environments. Existing approaches process utterances in isolation and have been evaluated primarily on English. We address these gaps along three dimensions. First, we fine-tune and evaluate six-self supervised models on a multilingual dataset of 182 children, showing that in-domain pre-training on child-centered recordings substantially outperforms models trained on adult speech. Second, we demonstrate that incorporating surrounding context substantially improves classification, with an absolute gain of 13.8% in average F1-score. Third, we evaluate our model in a realistic end-to-end pipeline, from adult speech detection to addressee classification, showing that performance drops under automatic segmentation but still consistently outperforms a rule-based baseline.
BabAR: from phoneme recognition to developmental measures of young children's speech production
Mar 05, 2026Studying early speech development at scale requires automatic tools, yet automatic phoneme recognition, especially for young children, remains largely unsolved. Building on decades of data collection, we curate TinyVox, a corpus of more than half a million phonetically transcribed child vocalizations in English, French, Portuguese, German, and Spanish. We use TinyVox to train BabAR, a cross-linguistic phoneme recognition system for child speech. We find that pretraining the system on multilingual child-centered daylong recordings substantially outperforms alternatives, and that providing 20 seconds of surrounding audio context during fine-tuning further improves performance. Error analyses show that substitutions predominantly fall within the same broad phonetic categories, suggesting suitability for coarse-grained developmental analyses. We validate BabAR by showing that its automatic measures of speech maturity align with developmental estimates from the literature.
BabyHuBERT: Multilingual Self-Supervised Learning for Segmenting Speakers in Child-Centered Long-Form Recordings
Sep 18, 2025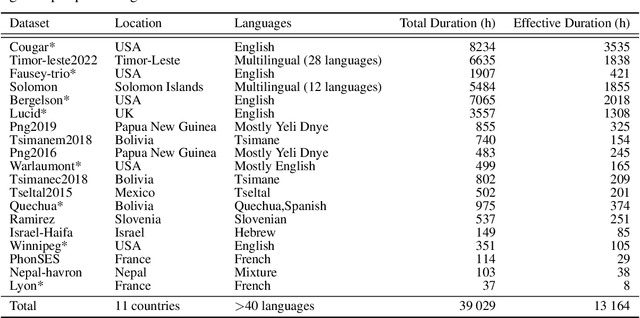
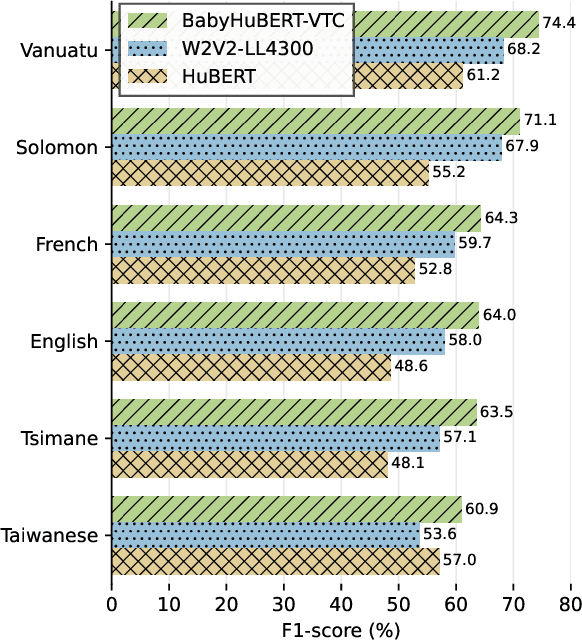
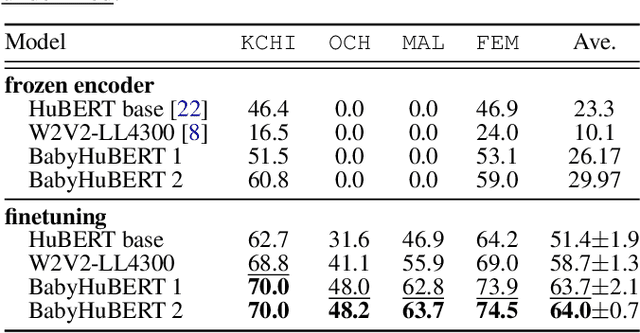
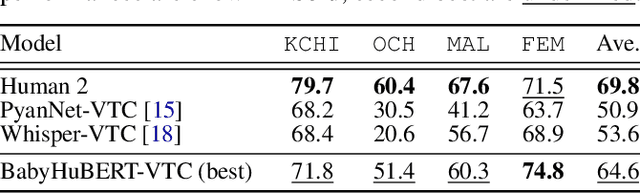
Child-centered long-form recordings are essential for studying early language development, but existing speech models trained on clean adult data perform poorly due to acoustic and linguistic differences. We introduce BabyHuBERT, the first self-supervised speech representation model trained on 13,000 hours of multilingual child-centered long-form recordings spanning over 40 languages. We evaluate BabyHuBERT on speaker segmentation, identifying when target children speak versus female adults, male adults, or other children -- a fundamental preprocessing step for analyzing naturalistic language experiences. BabyHuBERT achieves F1-scores from 52.1% to 74.4% across six diverse datasets, consistently outperforming W2V2-LL4300 (trained on English long-forms) and standard HuBERT (trained on clean adult speech). Notable improvements include 13.2 absolute F1 points over HuBERT on Vanuatu and 15.9 points on Solomon Islands corpora, demonstrating effectiveness on underrepresented languages. By sharing code and models, BabyHuBERT serves as a foundation model for child speech research, enabling fine-tuning on diverse downstream tasks.
BabySLM: language-acquisition-friendly benchmark of self-supervised spoken language models
Jun 08, 2023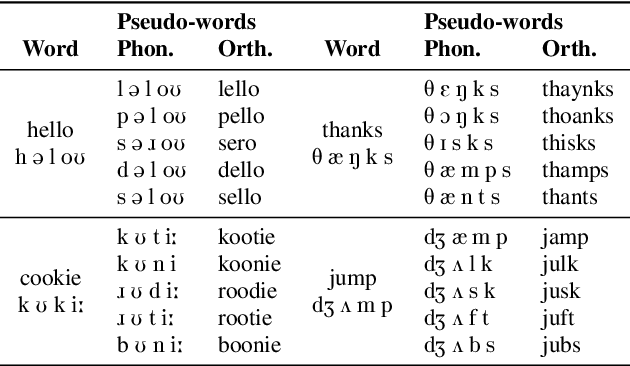
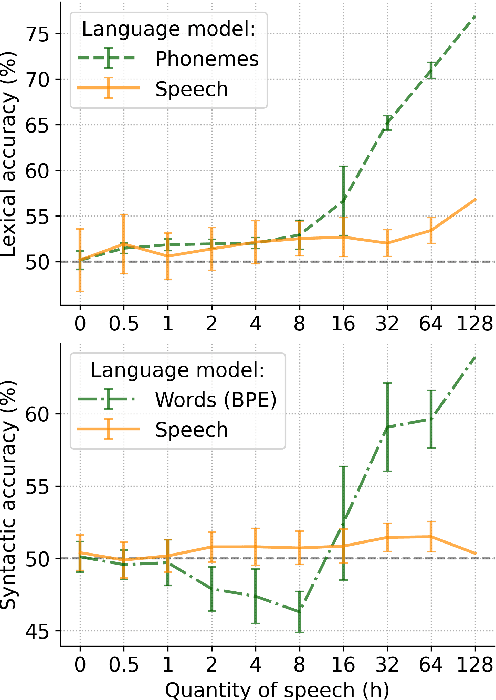
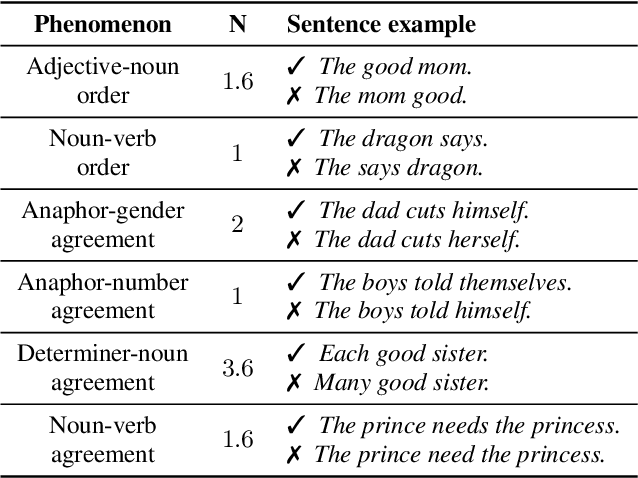
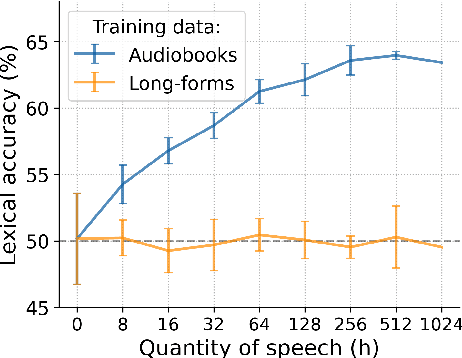
Self-supervised techniques for learning speech representations have been shown to develop linguistic competence from exposure to speech without the need for human labels. In order to fully realize the potential of these approaches and further our understanding of how infants learn language, simulations must closely emulate real-life situations by training on developmentally plausible corpora and benchmarking against appropriate test sets. To this end, we propose a language-acquisition-friendly benchmark to probe spoken language models at the lexical and syntactic levels, both of which are compatible with the vocabulary typical of children's language experiences. This paper introduces the benchmark and summarizes a range of experiments showing its usefulness. In addition, we highlight two exciting challenges that need to be addressed for further progress: bridging the gap between text and speech and between clean speech and in-the-wild speech.
ProsAudit, a prosodic benchmark for self-supervised speech models
Feb 24, 2023



We present ProsAudit, a benchmark in English to assess structural prosodic knowledge in self-supervised learning (SSL) speech models. It consists of two subtasks, their corresponding metrics, an evaluation dataset. In the protosyntax task, the model must correctly identify strong versus weak prosodic boundaries. In the lexical task, the model needs to correctly distinguish between pauses inserted between words and within words. We also provide human evaluation scores on this benchmark. We evaluated a series of SSL models and found that they were all able to perform above chance on both tasks, even when trained on an unseen language. However, non-native models performed significantly worse than native ones on the lexical task, highlighting the importance of lexical knowledge in this task. We also found a clear effect of size with models trained on more data performing better in the two subtasks.
Brouhaha: multi-task training for voice activity detection, speech-to-noise ratio, and C50 room acoustics estimation
Oct 27, 2022



Most automatic speech processing systems are sensitive to the acoustic environment, with degraded performance when applied to noisy or reverberant speech. But how can one tell whether speech is noisy or reverberant? We propose Brouhaha, a pipeline to simulate audio segments recorded in noisy and reverberant conditions. We then use the simulated audio to jointly train the Brouhaha model for voice activity detection, signal-to-noise ratio estimation, and C50 room acoustics prediction. We show how the predicted SNR and C50 values can be used to investigate and help diagnose errors made by automatic speech processing tools (such as pyannote.audio for speaker diarization or OpenAI's Whisper for automatic speech recognition). Both our pipeline and a pretrained model are open source and shared with the speech community.
Probing phoneme, language and speaker information in unsupervised speech representations
Mar 30, 2022
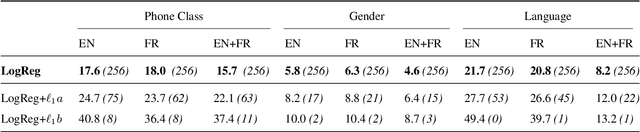
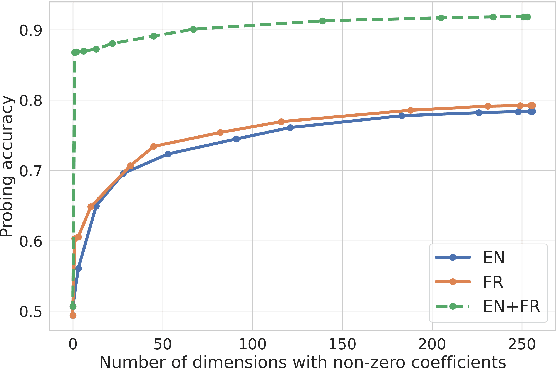
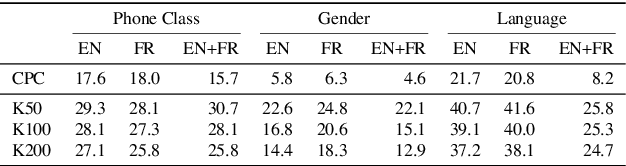
Unsupervised models of representations based on Contrastive Predictive Coding (CPC)[1] are primarily used in spoken language modelling in that they encode phonetic information. In this study, we ask what other types of information are present in CPC speech representations. We focus on three categories: phone class, gender and language, and compare monolingual and bilingual models. Using qualitative and quantitative tools, we find that both gender and phone class information are present in both types of models. Language information, however, is very salient in the bilingual model only, suggesting CPC models learn to discriminate languages when trained on multiple languages. Some language information can also be retrieved from monolingual models, but it is more diffused across all features. These patterns hold when analyses are carried on the discrete units from a downstream clustering model. However, although there is no effect of the number of target clusters on phone class and language information, more gender information is encoded with more clusters. Finally, we find that there is some cost to being exposed to two languages on a downstream phoneme discrimination task.
ZR-2021VG: Zero-Resource Speech Challenge, Visually-Grounded Language Modelling track, 2021 edition
Jul 14, 2021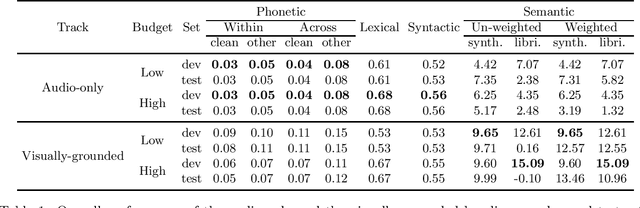
We present the visually-grounded language modelling track that was introduced in the Zero-Resource Speech challenge, 2021 edition, 2nd round. We motivate the new track and discuss participation rules in detail. We also present the two baseline systems that were developed for this track.