 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparsity-Aware Evolution for Model Merging
Feb 09, 2026We propose a sparsity-aware evolutionary (SAE) framework for model merging that involves iterative pruning-merging cycles to act as a novel mutation operator. We incorporate the sparsity constraints into the score function, which steers the evolutionary process to favor more sparse models, in addition to other conventional performance scores. Interestingly, the by-product of \textit{competition} for sparsity introduces an extra local \textit{attraction} and interplay into the evolutionary process: if one competitor has more zero elements, the other competitor's non-zero elements will occupy those positions, even though the less sparse competitor loses to the more sparse competitor in other positions. The proposed pipeline is evaluated on a variety of large-scale LLM benchmarks. Experiments demonstrate that our approach can improve model merging reliability across multiple benchmarks, and is easy to incorporate due to its simplicity and being orthogonal to most existing approaches.
The Unheard Alternative: Contrastive Explanations for Speech-to-Text Models
Sep 30, 2025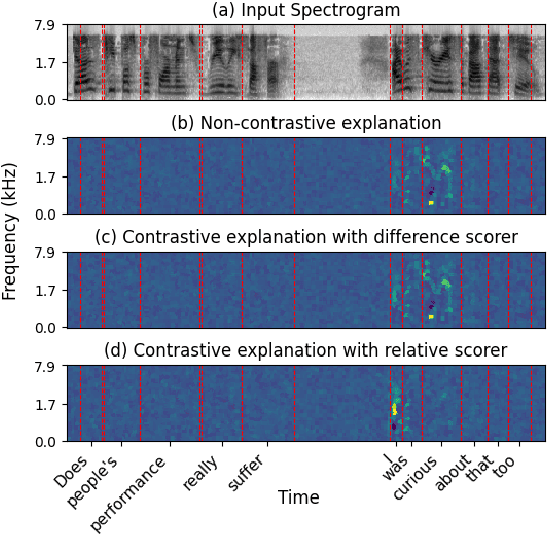
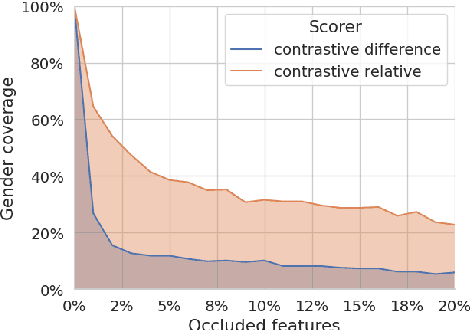

Contrastive explanations, which indicate why an AI system produced one output (the target) instead of another (the foil), are widely regarded in explainable AI as more informative and interpretable than standard explanations. However, obtaining such explanations for speech-to-text (S2T) generative models remains an open challenge. Drawing from feature attribution techniques, we propose the first method to obtain contrastive explanations in S2T by analyzing how parts of the input spectrogram influence the choice between alternative outputs. Through a case study on gender assignment in speech translation, we show that our method accurately identifies the audio features that drive the selection of one gender over another. By extending the scope of contrastive explanations to S2T, our work provides a foundation for better understanding S2T models.
Reasoning Strategies in Large Language Models: Can They Follow, Prefer, and Optimize?
Jul 16, 2025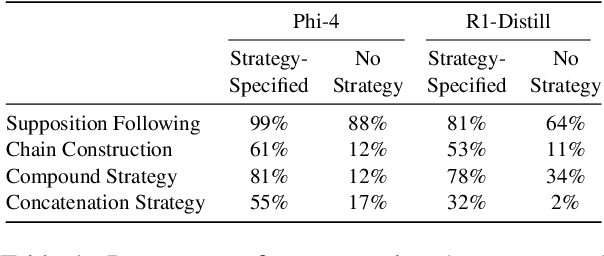

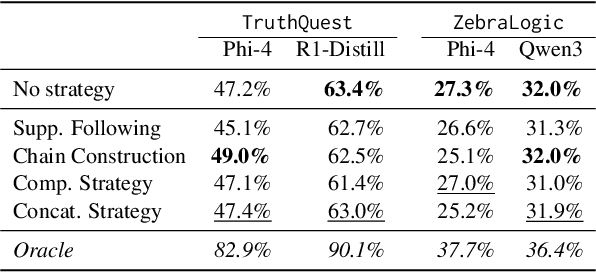
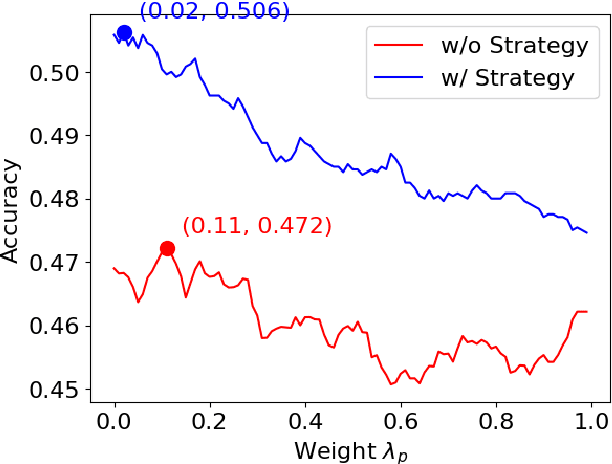
Human reasoning involves different strategies, each suited to specific problems. Prior work shows that large language model (LLMs) tend to favor a single reasoning strategy, potentially limiting their effectiveness in diverse reasoning challenges. In this work, we investigate whether prompting can control LLMs reasoning strategies and assess its impact on logical problem-solving. While our experiments show that no single strategy consistently improves accuracy, performance could be enhanced if models could adaptively choose the optimal strategy. We propose methods to guide LLMs in strategy selection, highlighting new ways to refine their reasoning abilities.
Testing LLMs' Capabilities in Annotating Translations Based on an Error Typology Designed for LSP Translation: First Experiments with ChatGPT
Apr 21, 2025This study investigates the capabilities of large language models (LLMs), specifically ChatGPT, in annotating MT outputs based on an error typology. In contrast to previous work focusing mainly on general language, we explore ChatGPT's ability to identify and categorise errors in specialised translations. By testing two different prompts and based on a customised error typology, we compare ChatGPT annotations with human expert evaluations of translations produced by DeepL and ChatGPT itself. The results show that, for translations generated by DeepL, recall and precision are quite high. However, the degree of accuracy in error categorisation depends on the prompt's specific features and its level of detail, ChatGPT performing very well with a detailed prompt. When evaluating its own translations, ChatGPT achieves significantly poorer results, revealing limitations with self-assessment. These results highlight both the potential and the limitations of LLMs for translation evaluation, particularly in specialised domains. Our experiments pave the way for future research on open-source LLMs, which could produce annotations of comparable or even higher quality. In the future, we also aim to test the practical effectiveness of this automated evaluation in the context of translation training, particularly by optimising the process of human evaluation by teachers and by exploring the impact of annotations by LLMs on students' post-editing and translation learning.
A Systematic Comparison of Syntactic Representations of Dependency Parsing
Mar 10, 2025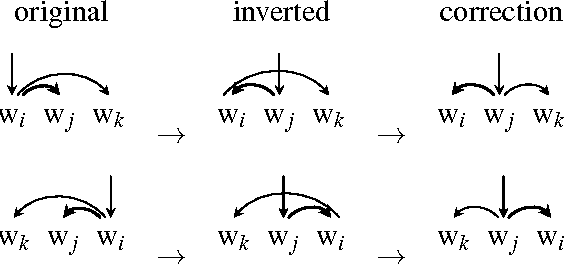
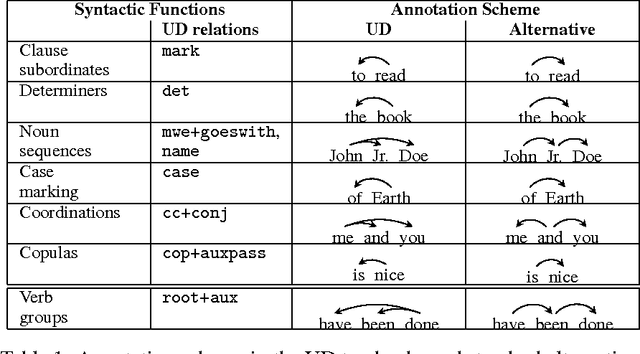
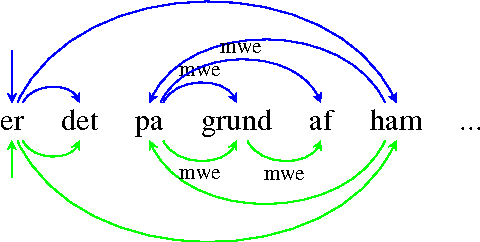
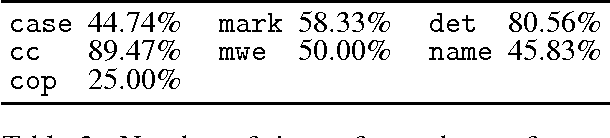
We compare the performance of a transition-based parser in regards to different annotation schemes. We pro-pose to convert some specific syntactic constructions observed in the universal dependency treebanks into a so-called more standard representation and to evaluate parsing performances over all the languages of the project. We show that the ``standard'' constructions do not lead systematically to better parsing performance and that the scores vary considerably according to the languages.
Establishing degrees of closeness between audio recordings along different dimensions using large-scale cross-lingual models
Feb 08, 2024
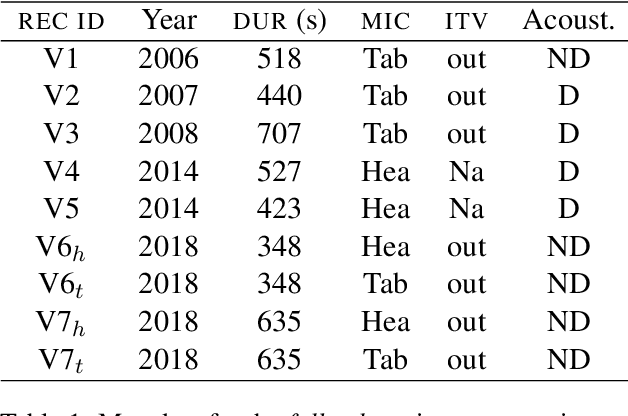

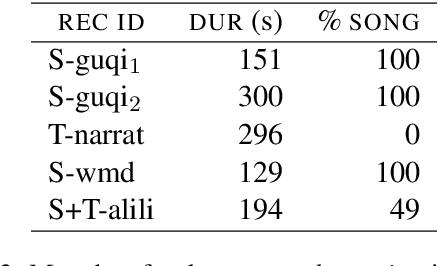
In the highly constrained context of low-resource language studies, we explore vector representations of speech from a pretrained model to determine their level of abstraction with regard to the audio signal. We propose a new unsupervised method using ABX tests on audio recordings with carefully curated metadata to shed light on the type of information present in the representations. ABX tests determine whether the representations computed by a multilingual speech model encode a given characteristic. Three experiments are devised: one on room acoustics aspects, one on linguistic genre, and one on phonetic aspects. The results confirm that the representations extracted from recordings with different linguistic/extra-linguistic characteristics differ along the same lines. Embedding more audio signal in one vector better discriminates extra-linguistic characteristics, whereas shorter snippets are better to distinguish segmental information. The method is fully unsupervised, potentially opening new research avenues for comparative work on under-documented languages.
Using Artificial French Data to Understand the Emergence of Gender Bias in Transformer Language Models
Oct 24, 2023


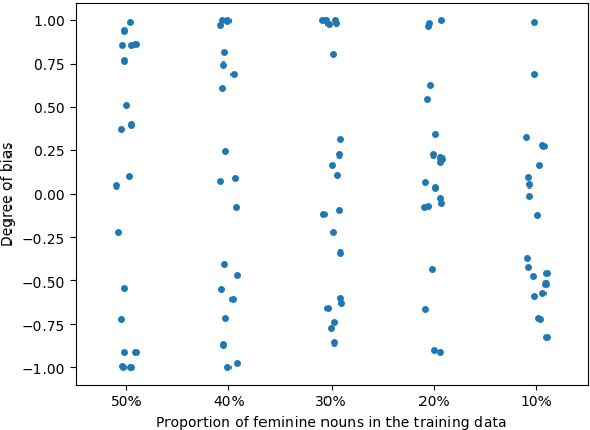
Numerous studies have demonstrated the ability of neural language models to learn various linguistic properties without direct supervision. This work takes an initial step towards exploring the less researched topic of how neural models discover linguistic properties of words, such as gender, as well as the rules governing their usage. We propose to use an artificial corpus generated by a PCFG based on French to precisely control the gender distribution in the training data and determine under which conditions a model correctly captures gender information or, on the contrary, appears gender-biased.
From `Snippet-lects' to Doculects and Dialects: Leveraging Neural Representations of Speech for Placing Audio Signals in a Language Landscape
May 29, 2023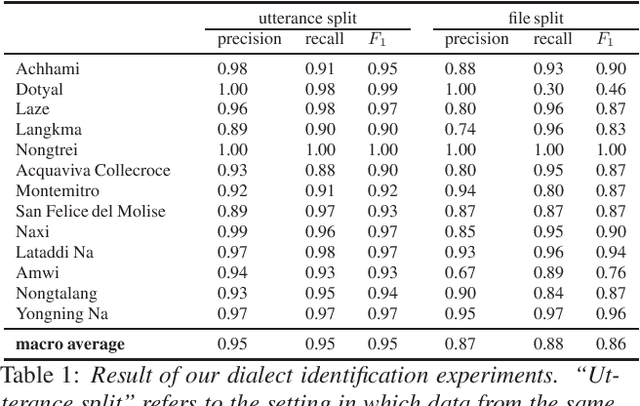

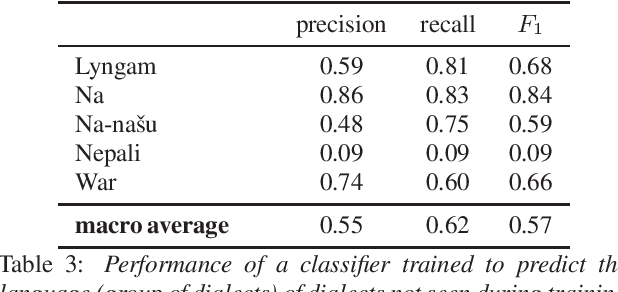

XLSR-53 a multilingual model of speech, builds a vector representation from audio, which allows for a range of computational treatments. The experiments reported here use this neural representation to estimate the degree of closeness between audio files, ultimately aiming to extract relevant linguistic properties. We use max-pooling to aggregate the neural representations from a "snippet-lect" (the speech in a 5-second audio snippet) to a "doculect" (the speech in a given resource), then to dialects and languages. We use data from corpora of 11 dialects belonging to 5 less-studied languages. Similarity measurements between the 11 corpora bring out greatest closeness between those that are known to be dialects of the same language. The findings suggest that (i) dialect/language can emerge among the various parameters characterizing audio files and (ii) estimates of overall phonetic/phonological closeness can be obtained for a little-resourced or fully unknown language. The findings help shed light on the type of information captured by neural representations of speech and how it can be extracted from these representations
ProsAudit, a prosodic benchmark for self-supervised speech models
Feb 24, 2023



We present ProsAudit, a benchmark in English to assess structural prosodic knowledge in self-supervised learning (SSL) speech models. It consists of two subtasks, their corresponding metrics, an evaluation dataset. In the protosyntax task, the model must correctly identify strong versus weak prosodic boundaries. In the lexical task, the model needs to correctly distinguish between pauses inserted between words and within words. We also provide human evaluation scores on this benchmark. We evaluated a series of SSL models and found that they were all able to perform above chance on both tasks, even when trained on an unseen language. However, non-native models performed significantly worse than native ones on the lexical task, highlighting the importance of lexical knowledge in this task. We also found a clear effect of size with models trained on more data performing better in the two subtasks.
Assessing the Capacity of Transformer to Abstract Syntactic Representations: A Contrastive Analysis Based on Long-distance Agreement
Dec 08, 2022The long-distance agreement, evidence for syntactic structure, is increasingly used to assess the syntactic generalization of Neural Language Models. Much work has shown that transformers are capable of high accuracy in varied agreement tasks, but the mechanisms by which the models accomplish this behavior are still not well understood. To better understand transformers' internal working, this work contrasts how they handle two superficially similar but theoretically distinct agreement phenomena: subject-verb and object-past participle agreement in French. Using probing and counterfactual analysis methods, our experiments show that i) the agreement task suffers from several confounders which partially question the conclusions drawn so far and ii) transformers handle subject-verb and object-past participle agreements in a way that is consistent with their modeling in theoretical linguistics.