 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Comparison of Syntactic Representations of Dependency Parsing
Mar 10, 2025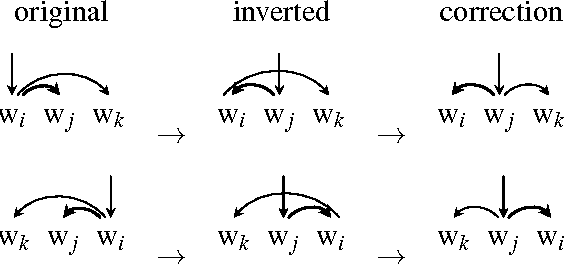
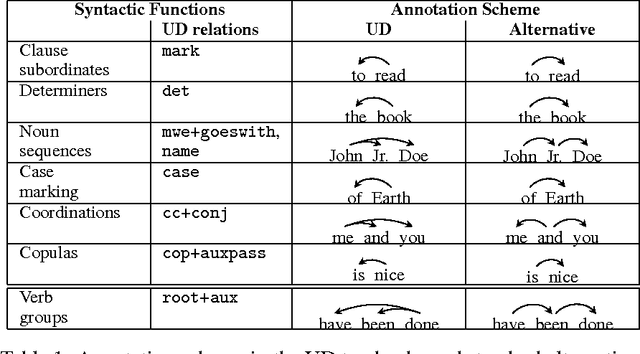
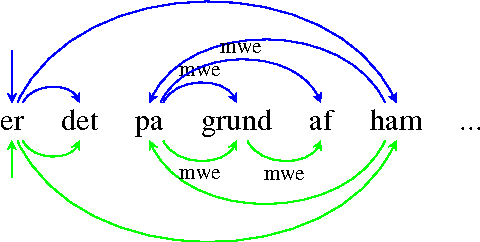
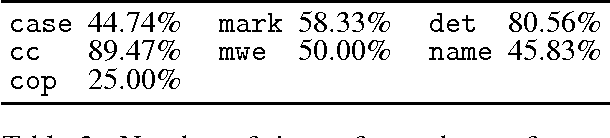
We compare the performance of a transition-based parser in regards to different annotation schemes. We pro-pose to convert some specific syntactic constructions observed in the universal dependency treebanks into a so-called more standard representation and to evaluate parsing performances over all the languages of the project. We show that the ``standard'' constructions do not lead systematically to better parsing performance and that the scores vary considerably according to the languages.
Grammatical Error Correction in Low Error Density Domains: A New Benchmark and Analyses
Oct 15, 2020

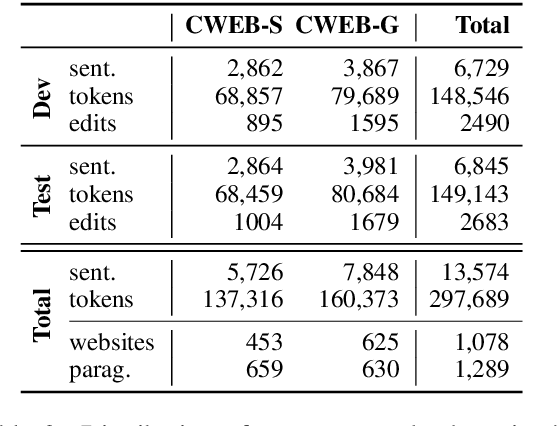

Evaluation of grammatical error correction (GEC) systems has primarily focused on essays written by non-native learners of English, which however is only part of the full spectrum of GEC applications. We aim to broaden the target domain of GEC and release CWEB, a new benchmark for GEC consisting of website text generated by English speakers of varying levels of proficiency. Website data is a common and important domain that contains far fewer grammatical errors than learner essays, which we show presents a challenge to state-of-the-art GEC systems. We demonstrate that a factor behind this is the inability of systems to rely on a strong internal language model in low error density domains. We hope this work shall facilitate the development of open-domain GEC models that generalize to different topics and genres.
Weakly Supervised POS Taggers Perform Poorly on Truly Low-Resource Languages
Apr 28, 2020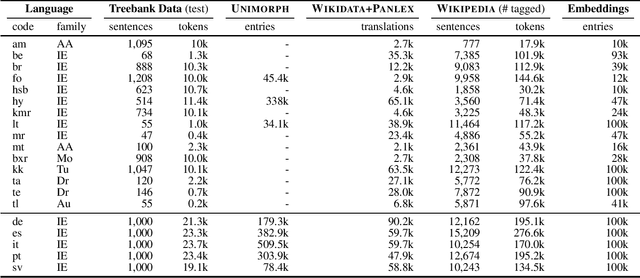
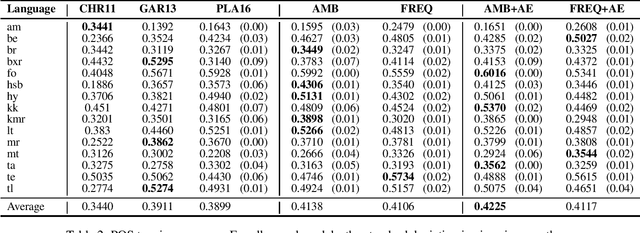

Part-of-speech (POS) taggers for low-resource languages which are exclusively based on various forms of weak supervision - e.g., cross-lingual transfer, type-level supervision, or a combination thereof - have been reported to perform almost as well as supervised ones. However, weakly supervised POS taggers are commonly only evaluated on languages that are very different from truly low-resource languages, and the taggers use sources of information, like high-coverage and almost error-free dictionaries, which are likely not available for resource-poor languages. We train and evaluate state-of-the-art weakly supervised POS taggers for a typologically diverse set of 15 truly low-resource languages. On these languages, given a realistic amount of resources, even our best model gets only less than half of the words right. Our results highlight the need for new and different approaches to POS tagging for truly low-resource languages.
Cross-lingual and cross-domain discourse segmentation of entire documents
Apr 24, 2017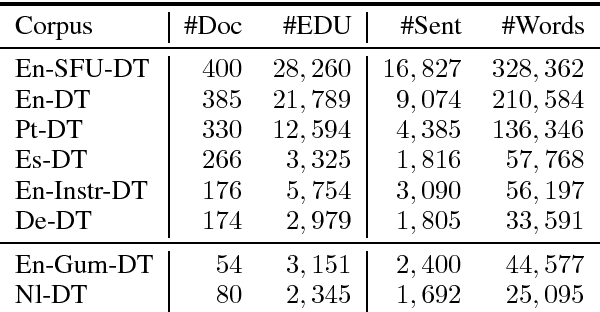
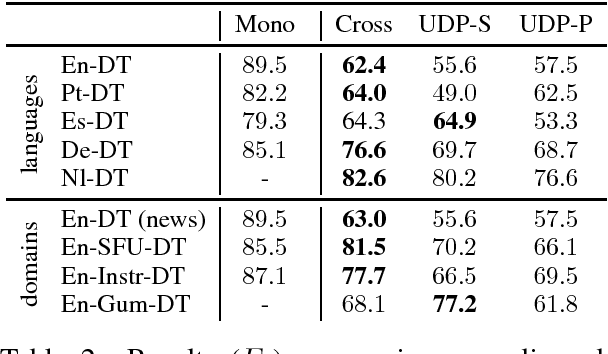
Discourse segmentation is a crucial step in building end-to-end discourse parsers. However, discourse segmenters only exist for a few languages and domains. Typically they only detect intra-sentential segment boundaries, assuming gold standard sentence and token segmentation, and relying on high-quality syntactic parses and rich heuristics that are not generally available across languages and domains. In this paper, we propose statistical discourse segmenters for five languages and three domains that do not rely on gold pre-annotations. We also consider the problem of learning discourse segmenters when no labeled data is available for a language. Our fully supervised system obtains 89.5% F1 for English newswire, with slight drops in performance on other domains, and we report supervised and unsupervised (cross-lingual) results for five languages in total.