 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscourse Structure Extraction from Pre-Trained and Fine-Tuned Language Models in Dialogues
Feb 12, 2023
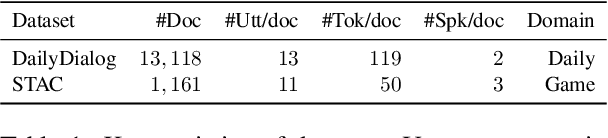
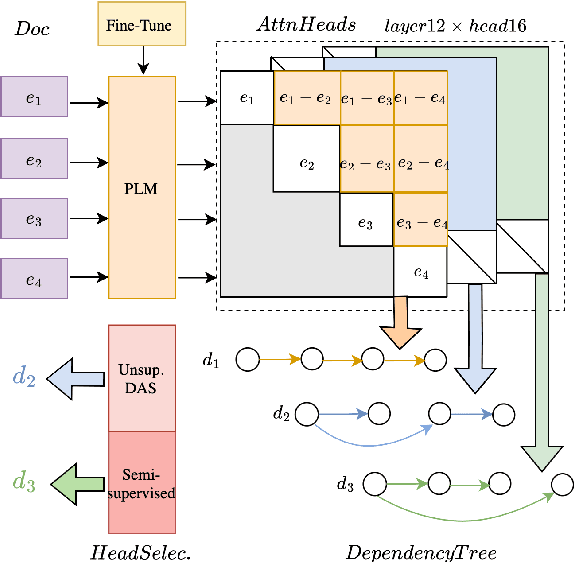
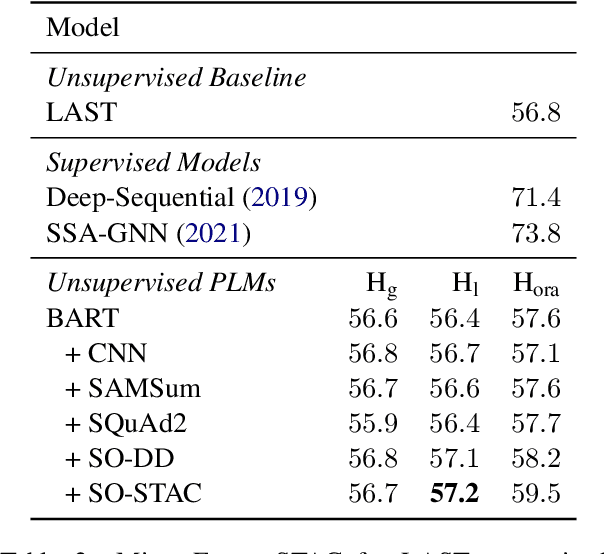
Discourse processing suffers from data sparsity, especially for dialogues. As a result, we explore approaches to build discourse structures for dialogues, based on attention matrices from Pre-trained Language Models (PLMs). We investigate multiple tasks for fine-tuning and show that the dialogue-tailored Sentence Ordering task performs best. To locate and exploit discourse information in PLMs, we propose an unsupervised and a semi-supervised method. Our proposals achieve encouraging results on the STAC corpus, with F1 scores of 57.2 and 59.3 for unsupervised and semi-supervised methods, respectively. When restricted to projective trees, our scores improved to 63.3 and 68.1.
Is writing style predictive of scientific fraud?
Jul 13, 2017

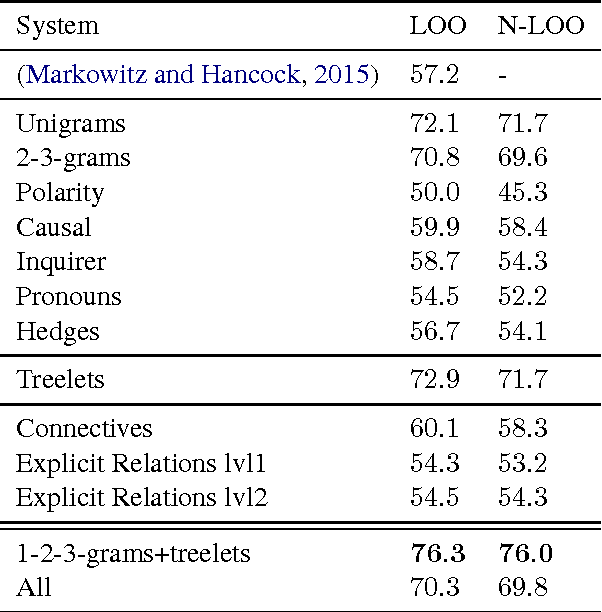
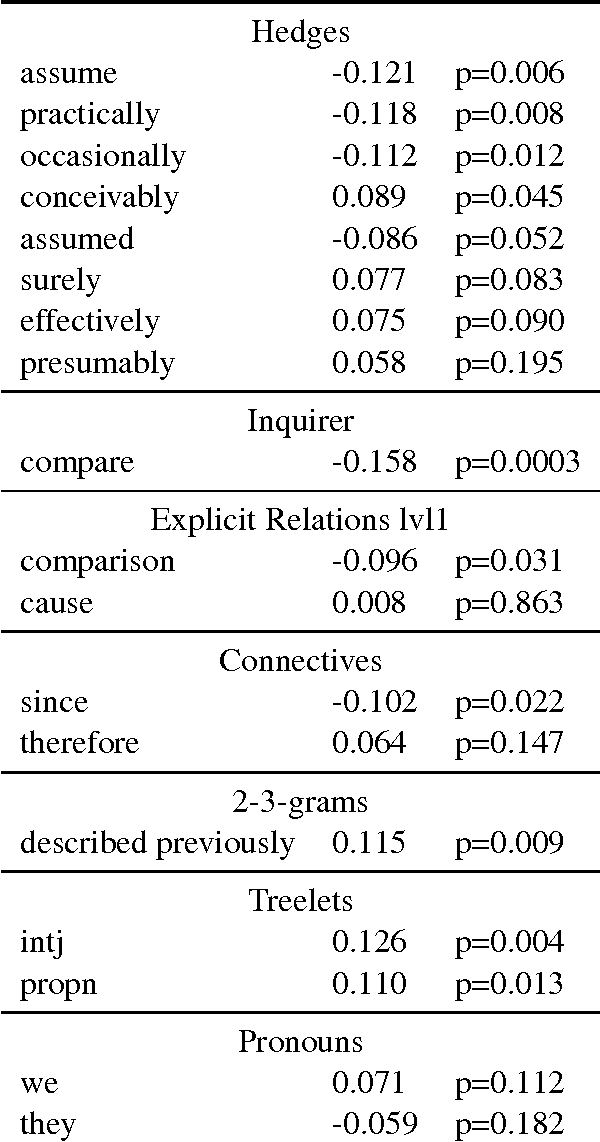
The problem of detecting scientific fraud using machine learning was recently introduced, with initial, positive results from a model taking into account various general indicators. The results seem to suggest that writing style is predictive of scientific fraud. We revisit these initial experiments, and show that the leave-one-out testing procedure they used likely leads to a slight over-estimate of the predictability, but also that simple models can outperform their proposed model by some margin. We go on to explore more abstract linguistic features, such as linguistic complexity and discourse structure, only to obtain negative results. Upon analyzing our models, we do see some interesting patterns, though: Scientific fraud, for examples, contains less comparison, as well as different types of hedging and ways of presenting logical reasoning.
Cross-lingual and cross-domain discourse segmentation of entire documents
Apr 24, 2017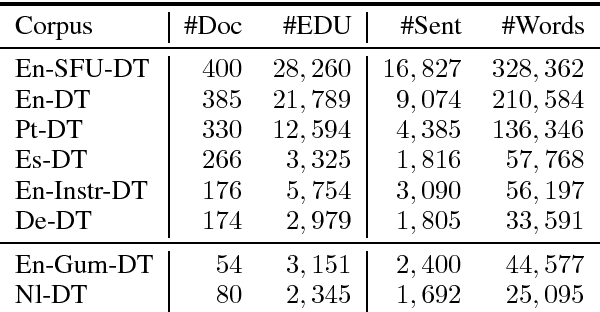
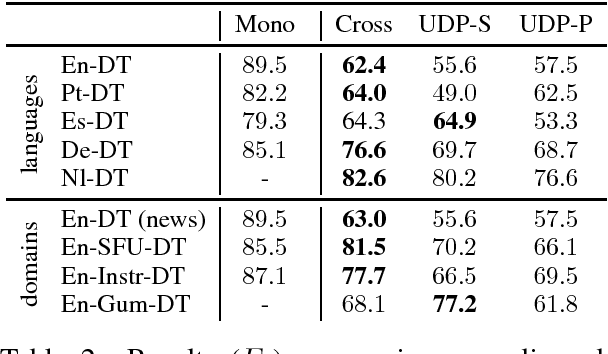
Discourse segmentation is a crucial step in building end-to-end discourse parsers. However, discourse segmenters only exist for a few languages and domains. Typically they only detect intra-sentential segment boundaries, assuming gold standard sentence and token segmentation, and relying on high-quality syntactic parses and rich heuristics that are not generally available across languages and domains. In this paper, we propose statistical discourse segmenters for five languages and three domains that do not rely on gold pre-annotations. We also consider the problem of learning discourse segmenters when no labeled data is available for a language. Our fully supervised system obtains 89.5% F1 for English newswire, with slight drops in performance on other domains, and we report supervised and unsupervised (cross-lingual) results for five languages in total.
Cross-lingual RST Discourse Parsing
Jan 11, 2017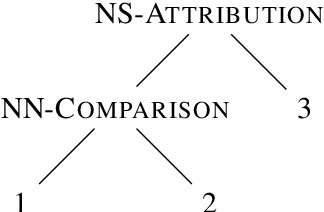
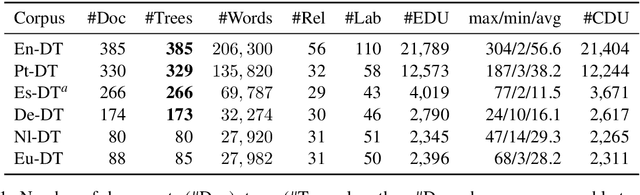
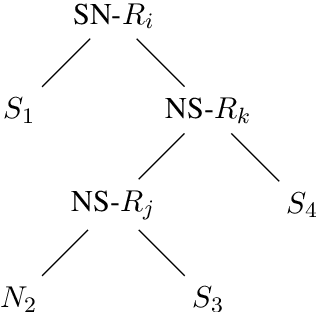
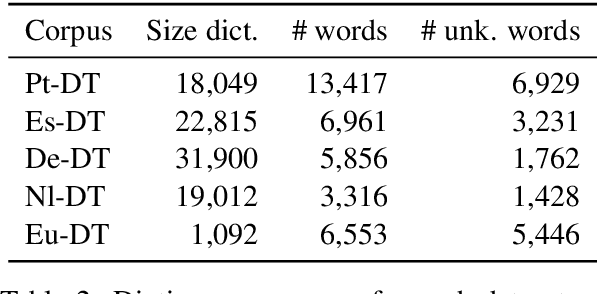
Discourse parsing is an integral part of understanding information flow and argumentative structure in documents. Most previous research has focused on inducing and evaluating models from the English RST Discourse Treebank. However, discourse treebanks for other languages exist, including Spanish, German, Basque, Dutch and Brazilian Portuguese. The treebanks share the same underlying linguistic theory, but differ slightly in the way documents are annotated. In this paper, we present (a) a new discourse parser which is simpler, yet competitive (significantly better on 2/3 metrics) to state of the art for English, (b) a harmonization of discourse treebanks across languages, enabling us to present (c) what to the best of our knowledge are the first experiments on cross-lingual discourse parsing.