 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised POS Taggers Perform Poorly on Truly Low-Resource Languages
Paper and Code
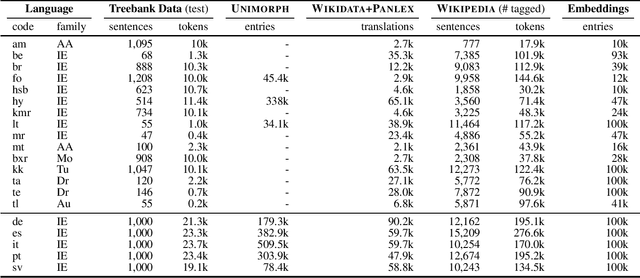
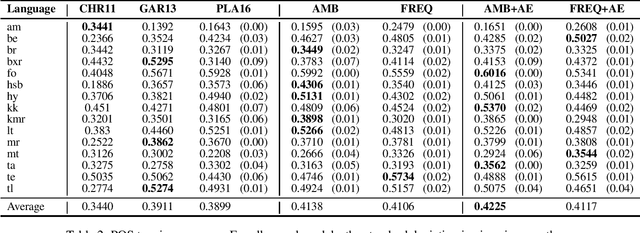

Part-of-speech (POS) taggers for low-resource languages which are exclusively based on various forms of weak supervision - e.g., cross-lingual transfer, type-level supervision, or a combination thereof - have been reported to perform almost as well as supervised ones. However, weakly supervised POS taggers are commonly only evaluated on languages that are very different from truly low-resource languages, and the taggers use sources of information, like high-coverage and almost error-free dictionaries, which are likely not available for resource-poor languages. We train and evaluate state-of-the-art weakly supervised POS taggers for a typologically diverse set of 15 truly low-resource languages. On these languages, given a realistic amount of resources, even our best model gets only less than half of the words right. Our results highlight the need for new and different approaches to POS tagging for truly low-resource languages.