 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom `Snippet-lects' to Doculects and Dialects: Leveraging Neural Representations of Speech for Placing Audio Signals in a Language Landscape
Paper and Code
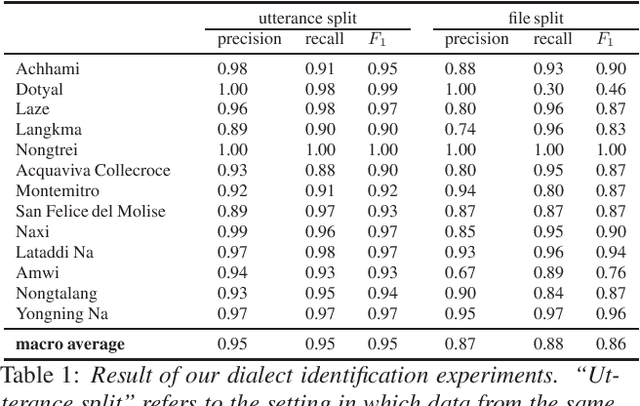

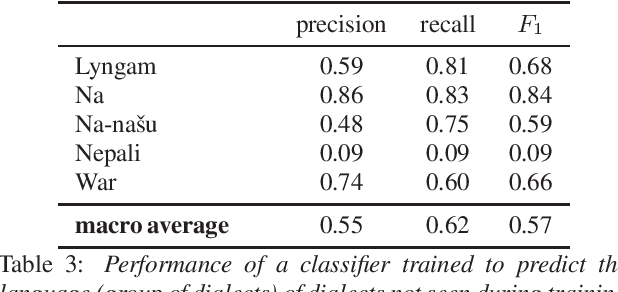

XLSR-53 a multilingual model of speech, builds a vector representation from audio, which allows for a range of computational treatments. The experiments reported here use this neural representation to estimate the degree of closeness between audio files, ultimately aiming to extract relevant linguistic properties. We use max-pooling to aggregate the neural representations from a "snippet-lect" (the speech in a 5-second audio snippet) to a "doculect" (the speech in a given resource), then to dialects and languages. We use data from corpora of 11 dialects belonging to 5 less-studied languages. Similarity measurements between the 11 corpora bring out greatest closeness between those that are known to be dialects of the same language. The findings suggest that (i) dialect/language can emerge among the various parameters characterizing audio files and (ii) estimates of overall phonetic/phonological closeness can be obtained for a little-resourced or fully unknown language. The findings help shed light on the type of information captured by neural representations of speech and how it can be extracted from these representations