 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstablishing degrees of closeness between audio recordings along different dimensions using large-scale cross-lingual models
Feb 08, 2024In the highly constrained context of low-resource language studies, we explore vector representations of speech from a pretrained model to determine their level of abstraction with regard to the audio signal. We propose a new unsupervised method using ABX tests on audio recordings with carefully curated metadata to shed light on the type of information present in the representations. ABX tests determine whether the representations computed by a multilingual speech model encode a given characteristic. Three experiments are devised: one on room acoustics aspects, one on linguistic genre, and one on phonetic aspects. The results confirm that the representations extracted from recordings with different linguistic/extra-linguistic characteristics differ along the same lines. Embedding more audio signal in one vector better discriminates extra-linguistic characteristics, whereas shorter snippets are better to distinguish segmental information. The method is fully unsupervised, potentially opening new research avenues for comparative work on under-documented languages.
From `Snippet-lects' to Doculects and Dialects: Leveraging Neural Representations of Speech for Placing Audio Signals in a Language Landscape
May 29, 2023XLSR-53 a multilingual model of speech, builds a vector representation from audio, which allows for a range of computational treatments. The experiments reported here use this neural representation to estimate the degree of closeness between audio files, ultimately aiming to extract relevant linguistic properties. We use max-pooling to aggregate the neural representations from a "snippet-lect" (the speech in a 5-second audio snippet) to a "doculect" (the speech in a given resource), then to dialects and languages. We use data from corpora of 11 dialects belonging to 5 less-studied languages. Similarity measurements between the 11 corpora bring out greatest closeness between those that are known to be dialects of the same language. The findings suggest that (i) dialect/language can emerge among the various parameters characterizing audio files and (ii) estimates of overall phonetic/phonological closeness can be obtained for a little-resourced or fully unknown language. The findings help shed light on the type of information captured by neural representations of speech and how it can be extracted from these representations
User-friendly automatic transcription of low-resource languages: Plugging ESPnet into Elpis
Dec 15, 2020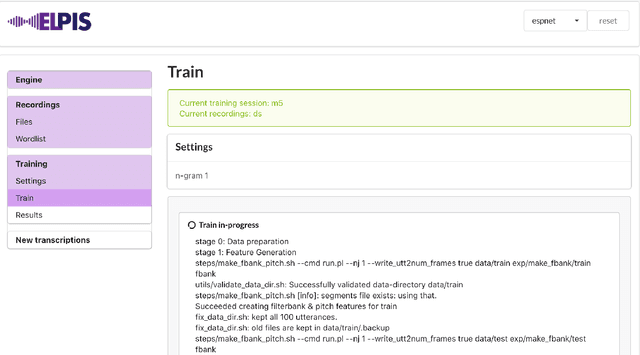

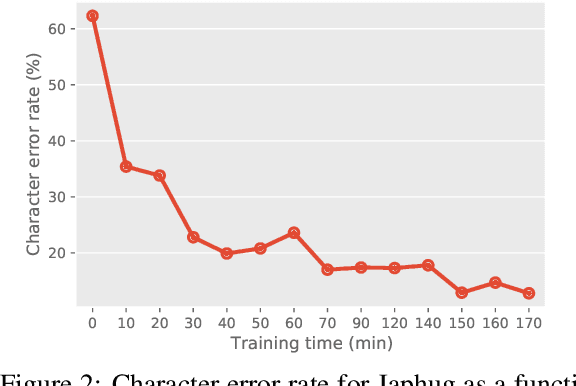
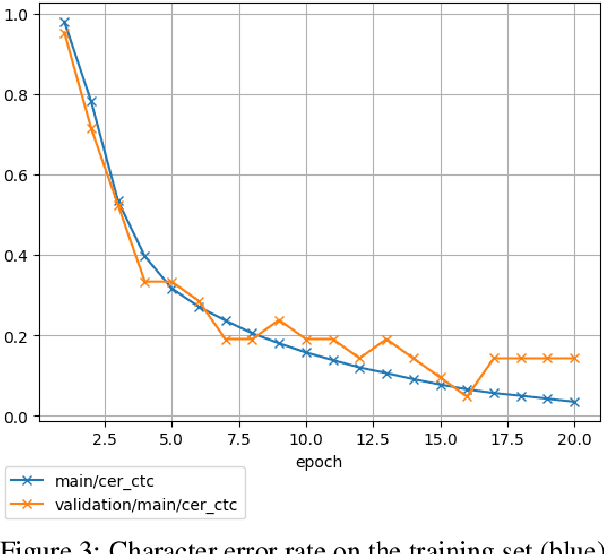
This paper reports on progress integrating the speech recognition toolkit ESPnet into Elpis, a web front-end originally designed to provide access to the Kaldi automatic speech recognition toolkit. The goal of this work is to make end-to-end speech recognition models available to language workers via a user-friendly graphical interface. Encouraging results are reported on (i) development of an ESPnet recipe for use in Elpis, with preliminary results on data sets previously used for training acoustic models with the Persephone toolkit along with a new data set that had not previously been used in speech recognition, and (ii) incorporating ESPnet into Elpis along with UI enhancements and a CUDA-supported Dockerfile.
AlloVera: A Multilingual Allophone Database
Apr 17, 2020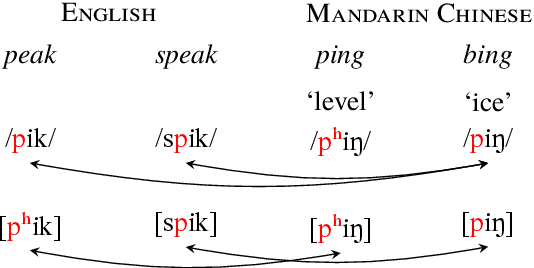



We introduce a new resource, AlloVera, which provides mappings from 218 allophones to phonemes for 14 languages. Phonemes are contrastive phonological units, and allophones are their various concrete realizations, which are predictable from phonological context. While phonemic representations are language specific, phonetic representations (stated in terms of (allo)phones) are much closer to a universal (language-independent) transcription. AlloVera allows the training of speech recognition models that output phonetic transcriptions in the International Phonetic Alphabet (IPA), regardless of the input language. We show that a "universal" allophone model, Allosaurus, built with AlloVera, outperforms "universal" phonemic models and language-specific models on a speech-transcription task. We explore the implications of this technology (and related technologies) for the documentation of endangered and minority languages. We further explore other applications for which AlloVera will be suitable as it grows, including phonological typology.