 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlloVera: A Multilingual Allophone Database
Apr 17, 2020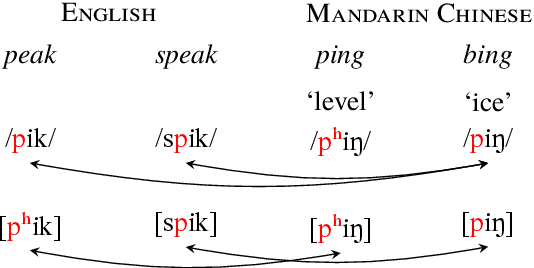



We introduce a new resource, AlloVera, which provides mappings from 218 allophones to phonemes for 14 languages. Phonemes are contrastive phonological units, and allophones are their various concrete realizations, which are predictable from phonological context. While phonemic representations are language specific, phonetic representations (stated in terms of (allo)phones) are much closer to a universal (language-independent) transcription. AlloVera allows the training of speech recognition models that output phonetic transcriptions in the International Phonetic Alphabet (IPA), regardless of the input language. We show that a "universal" allophone model, Allosaurus, built with AlloVera, outperforms "universal" phonemic models and language-specific models on a speech-transcription task. We explore the implications of this technology (and related technologies) for the documentation of endangered and minority languages. We further explore other applications for which AlloVera will be suitable as it grows, including phonological typology.
SANTLR: Speech Annotation Toolkit for Low Resource Languages
Aug 02, 2019
While low resource speech recognition has attracted a lot of attention from the speech community, there are a few tools available to facilitate low resource speech collection. In this work, we present SANTLR: Speech Annotation Toolkit for Low Resource Languages. It is a web-based toolkit which allows researchers to easily collect and annotate a corpus of speech in a low resource language. Annotators may use this toolkit for two purposes: transcription or recording. In transcription, annotators would transcribe audio files provided by the researchers; in recording, annotators would record their voice by reading provided texts. We highlight two properties of this toolkit. First, SANTLR has a very user-friendly User Interface (UI). Both researchers and annotators may use this simple web interface to interact. There is no requirement for the annotators to have any expertise in audio or text processing. The toolkit would handle all preprocessing and postprocessing steps. Second, we employ a multi-step ranking mechanism facilitate the annotation process. In particular, the toolkit would give higher priority to utterances which are easier to annotate and are more beneficial to achieving the goal of the annotation, e.g. quickly training an acoustic model.
Multilingual Speech Recognition with Corpus Relatedness Sampling
Aug 02, 2019
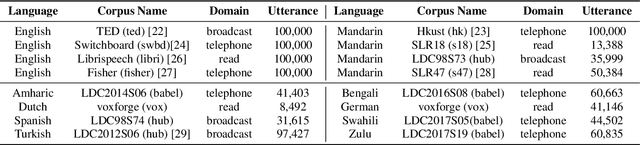


Multilingual acoustic models have been successfully applied to low-resource speech recognition. Most existing works have combined many small corpora together and pretrained a multilingual model by sampling from each corpus uniformly. The model is eventually fine-tuned on each target corpus. This approach, however, fails to exploit the relatedness and similarity among corpora in the training set. For example, the target corpus might benefit more from a corpus in the same domain or a corpus from a close language. In this work, we propose a simple but useful sampling strategy to take advantage of this relatedness. We first compute the corpus-level embeddings and estimate the similarity between each corpus. Next, we start training the multilingual model with uniform-sampling from each corpus at first, then we gradually increase the probability to sample from related corpora based on its similarity with the target corpus. Finally, the model would be fine-tuned automatically on the target corpus. Our sampling strategy outperforms the baseline multilingual model on 16 low-resource tasks. Additionally, we demonstrate that our corpus embeddings capture the language and domain information of each corpus.
The Zero Resource Speech Challenge 2019: TTS without T
Apr 25, 2019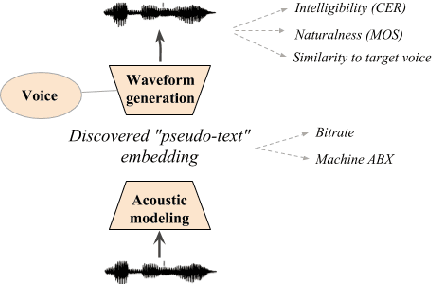
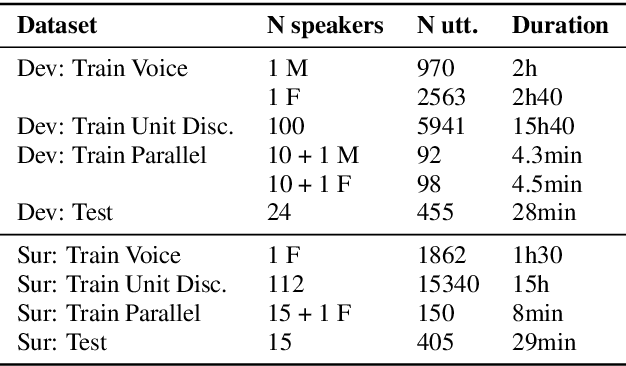
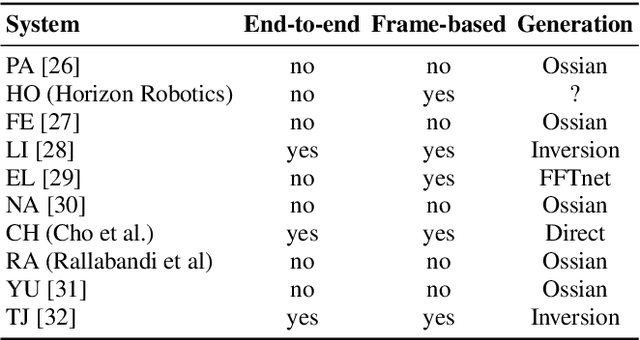
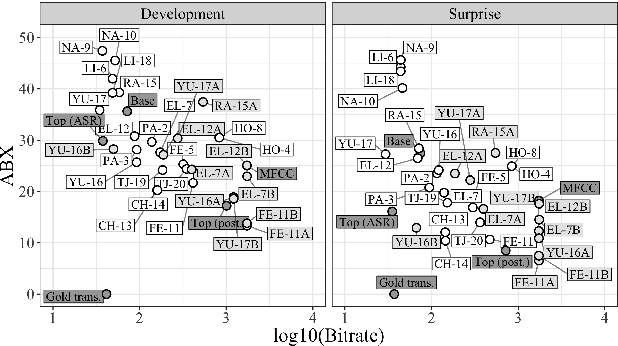
We present the Zero Resource Speech Challenge 2019, which proposes to build a speech synthesizer without any text or phonetic labels: hence, TTS without T (text-to-speech without text). We provide raw audio for a target voice in an unknown language (the Voice dataset), but no alignment, text or labels. Participants must discover subword units in an unsupervised way (using the Unit Discovery dataset) and align them to the voice recordings in a way that works best for the purpose of synthesizing novel utterances from novel speakers, similar to the target speaker's voice. We describe the metrics used for evaluation, a baseline system consisting of unsupervised subword unit discovery plus a standard TTS system, and a topline TTS using gold phoneme transcriptions. We present an overview of the 19 submitted systems from 11 teams and discuss the main results.
Domain Robust Feature Extraction for Rapid Low Resource ASR Development
Sep 30, 2018
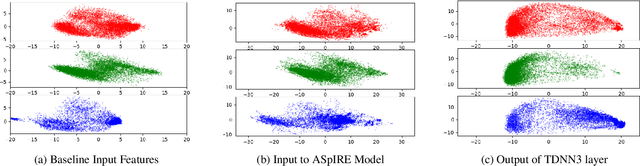

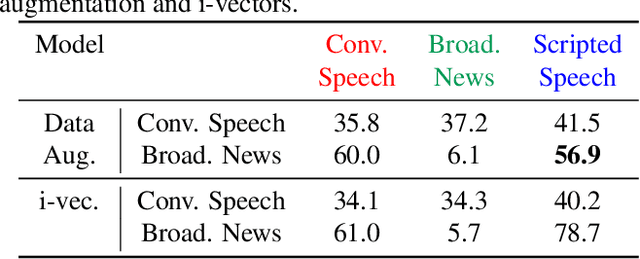
Developing a practical speech recognizer for a low resource language is challenging, not only because of the (potentially unknown) properties of the language, but also because test data may not be from the same domain as the available training data. In this paper, we focus on the latter challenge, i.e. domain mismatch, for systems trained using a sequence-based criterion. We demonstrate the effectiveness of using a pre-trained English recognizer, which is robust to such mismatched conditions, as a domain normalizing feature extractor on a low resource language. In our example, we use Turkish Conversational Speech and Broadcast News data. This enables rapid development of speech recognizers for new languages which can easily adapt to any domain. Testing in various cross-domain scenarios, we achieve relative improvements of around 25% in phoneme error rate, with improvements being around 50% for some domains.
Sequence-based Multi-lingual Low Resource Speech Recognition
Mar 06, 2018
Techniques for multi-lingual and cross-lingual speech recognition can help in low resource scenarios, to bootstrap systems and enable analysis of new languages and domains. End-to-end approaches, in particular sequence-based techniques, are attractive because of their simplicity and elegance. While it is possible to integrate traditional multi-lingual bottleneck feature extractors as front-ends, we show that end-to-end multi-lingual training of sequence models is effective on context independent models trained using Connectionist Temporal Classification (CTC) loss. We show that our model improves performance on Babel languages by over 6% absolute in terms of word/phoneme error rate when compared to mono-lingual systems built in the same setting for these languages. We also show that the trained model can be adapted cross-lingually to an unseen language using just 25% of the target data. We show that training on multiple languages is important for very low resource cross-lingual target scenarios, but not for multi-lingual testing scenarios. Here, it appears beneficial to include large well prepared datasets.
Finding Function in Form: Compositional Character Models for Open Vocabulary Word Representation
May 23, 2016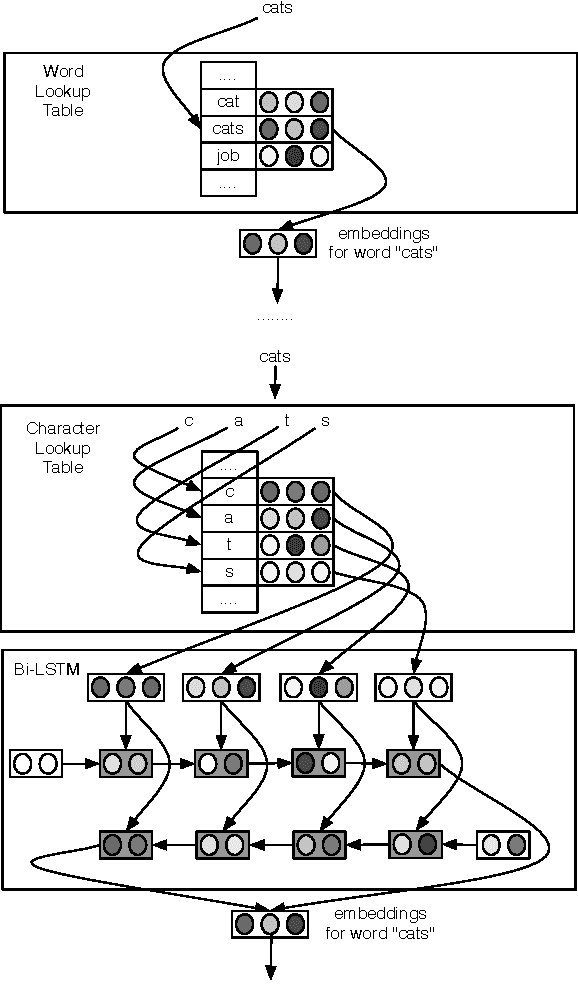
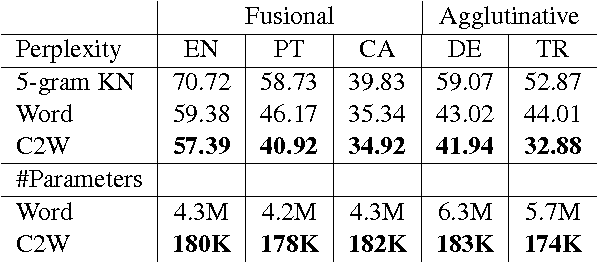
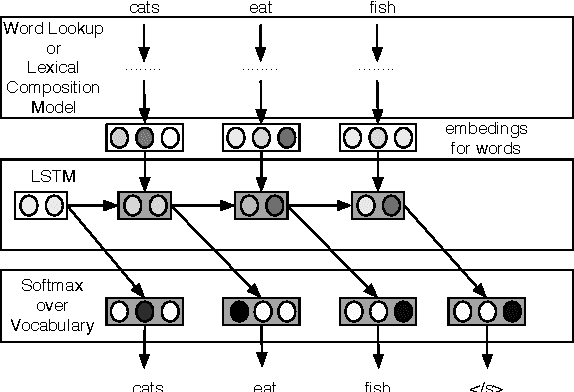

We introduce a model for constructing vector representations of words by composing characters using bidirectional LSTMs. Relative to traditional word representation models that have independent vectors for each word type, our model requires only a single vector per character type and a fixed set of parameters for the compositional model. Despite the compactness of this model and, more importantly, the arbitrary nature of the form-function relationship in language, our "composed" word representations yield state-of-the-art results in language modeling and part-of-speech tagging. Benefits over traditional baselines are particularly pronounced in morphologically rich languages (e.g., Turkish).
A Deep Learning Approach to Data-driven Parameterizations for Statistical Parametric Speech Synthesis
Sep 30, 2014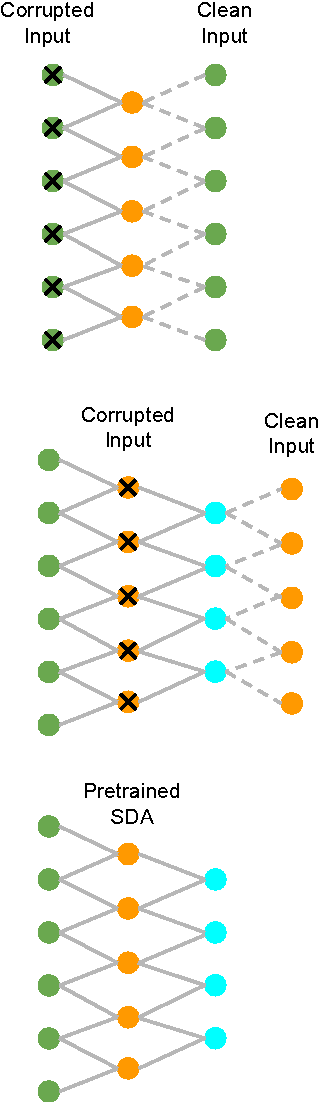

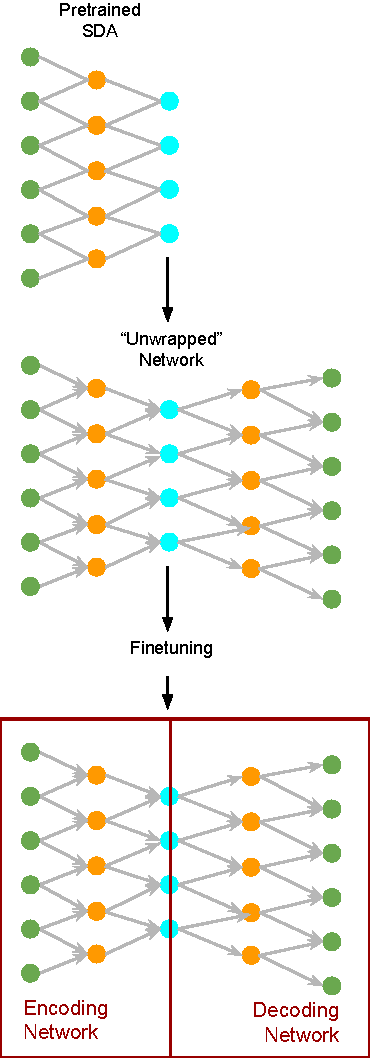

Nearly all Statistical Parametric Speech Synthesizers today use Mel Cepstral coefficients as the vocal tract parameterization of the speech signal. Mel Cepstral coefficients were never intended to work in a parametric speech synthesis framework, but as yet, there has been little success in creating a better parameterization that is more suited to synthesis. In this paper, we use deep learning algorithms to investigate a data-driven parameterization technique that is designed for the specific requirements of synthesis. We create an invertible, low-dimensional, noise-robust encoding of the Mel Log Spectrum by training a tapered Stacked Denoising Autoencoder (SDA). This SDA is then unwrapped and used as the initialization for a Multi-Layer Perceptron (MLP). The MLP is fine-tuned by training it to reconstruct the input at the output layer. This MLP is then split down the middle to form encoding and decoding networks. These networks produce a parameterization of the Mel Log Spectrum that is intended to better fulfill the requirements of synthesis. Results are reported for experiments conducted using this resulting parameterization with the ClusterGen speech synthesizer.