 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Neural Network Postfilters for Statistical Parametric Speech Synthesis
Jan 26, 2016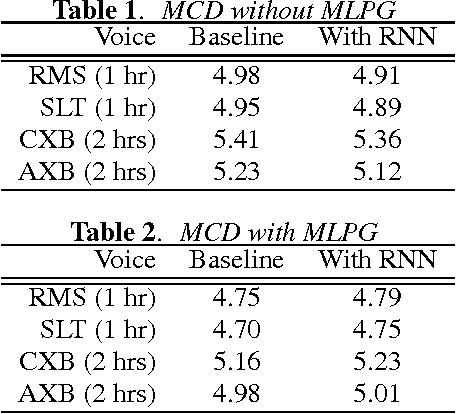
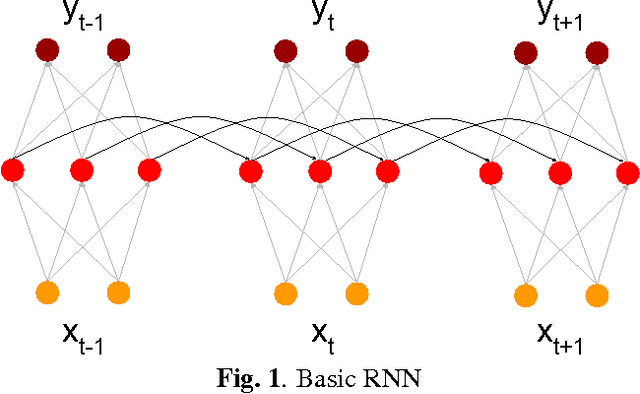
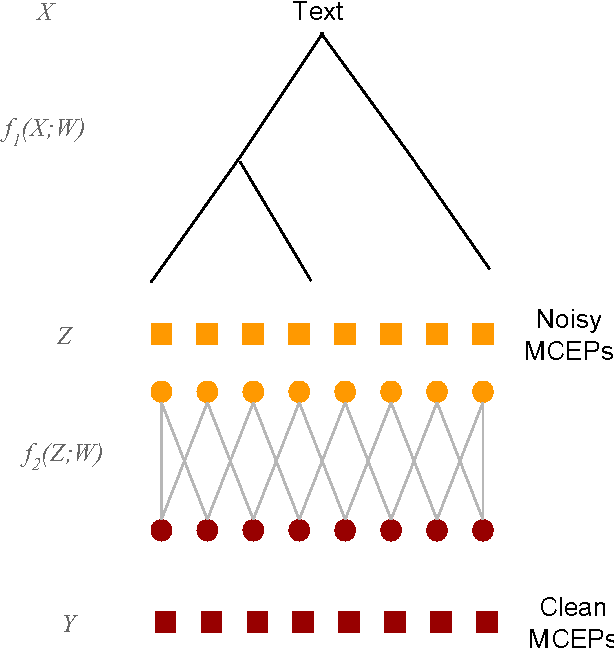
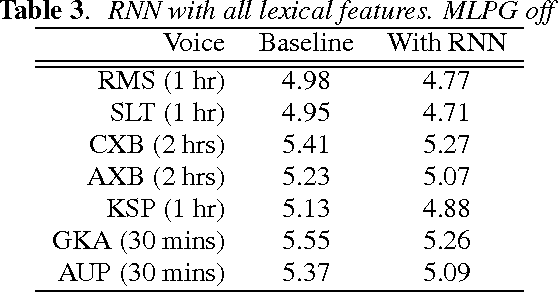
In the last two years, there have been numerous papers that have looked into using Deep Neural Networks to replace the acoustic model in traditional statistical parametric speech synthesis. However, far less attention has been paid to approaches like DNN-based postfiltering where DNNs work in conjunction with traditional acoustic models. In this paper, we investigate the use of Recurrent Neural Networks as a potential postfilter for synthesis. We explore the possibility of replacing existing postfilters, as well as highlight the ease with which arbitrary new features can be added as input to the postfilter. We also tried a novel approach of jointly training the Classification And Regression Tree and the postfilter, rather than the traditional approach of training them independently.
A Deep Learning Approach to Data-driven Parameterizations for Statistical Parametric Speech Synthesis
Sep 30, 2014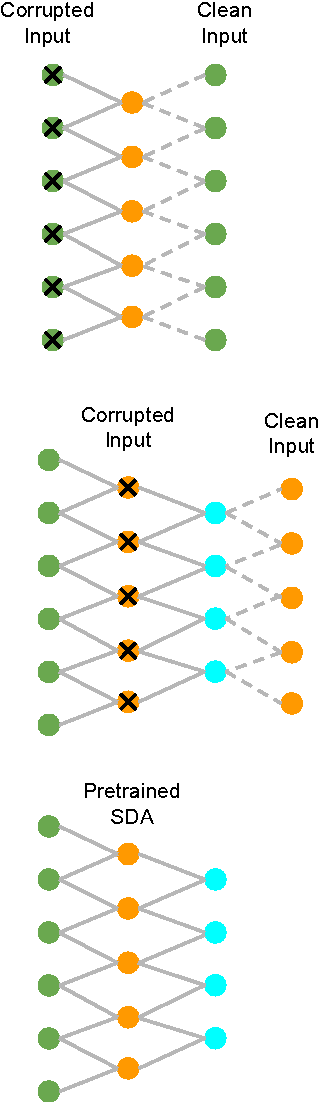

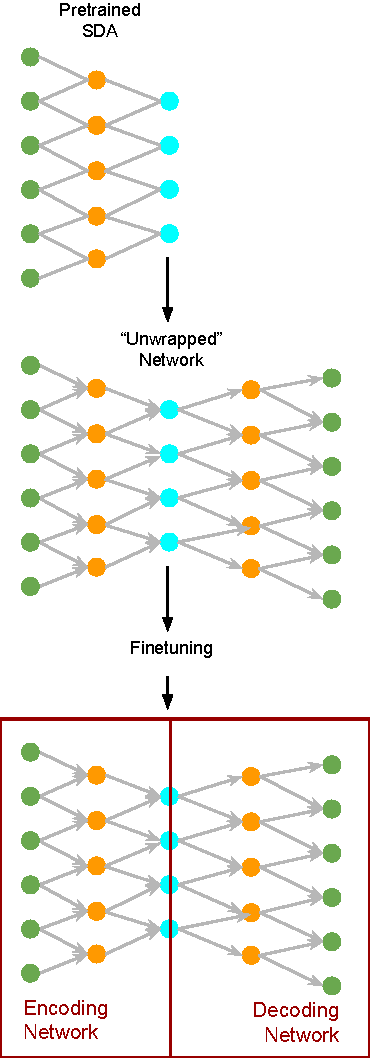

Nearly all Statistical Parametric Speech Synthesizers today use Mel Cepstral coefficients as the vocal tract parameterization of the speech signal. Mel Cepstral coefficients were never intended to work in a parametric speech synthesis framework, but as yet, there has been little success in creating a better parameterization that is more suited to synthesis. In this paper, we use deep learning algorithms to investigate a data-driven parameterization technique that is designed for the specific requirements of synthesis. We create an invertible, low-dimensional, noise-robust encoding of the Mel Log Spectrum by training a tapered Stacked Denoising Autoencoder (SDA). This SDA is then unwrapped and used as the initialization for a Multi-Layer Perceptron (MLP). The MLP is fine-tuned by training it to reconstruct the input at the output layer. This MLP is then split down the middle to form encoding and decoding networks. These networks produce a parameterization of the Mel Log Spectrum that is intended to better fulfill the requirements of synthesis. Results are reported for experiments conducted using this resulting parameterization with the ClusterGen speech synthesizer.