 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Function in Form: Compositional Character Models for Open Vocabulary Word Representation
May 23, 2016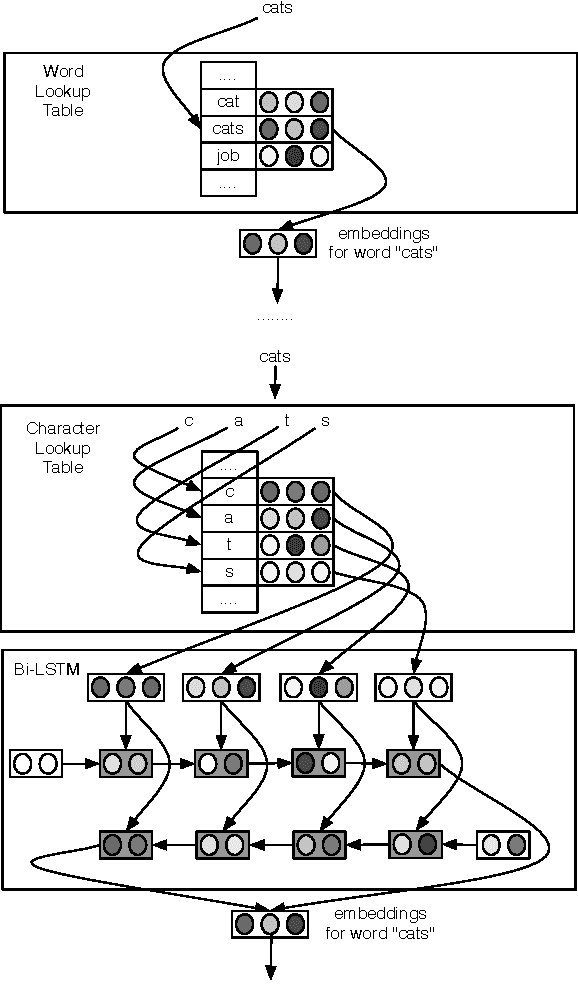
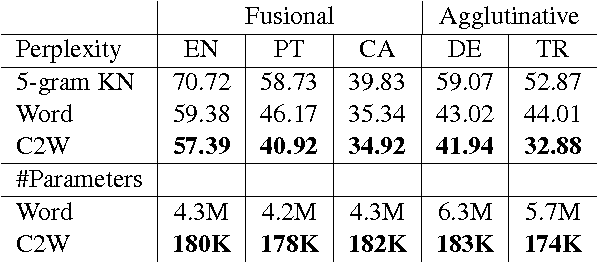
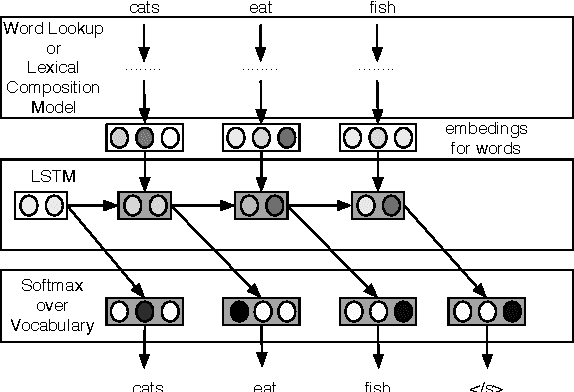

We introduce a model for constructing vector representations of words by composing characters using bidirectional LSTMs. Relative to traditional word representation models that have independent vectors for each word type, our model requires only a single vector per character type and a fixed set of parameters for the compositional model. Despite the compactness of this model and, more importantly, the arbitrary nature of the form-function relationship in language, our "composed" word representations yield state-of-the-art results in language modeling and part-of-speech tagging. Benefits over traditional baselines are particularly pronounced in morphologically rich languages (e.g., Turkish).
Summarization of Films and Documentaries Based on Subtitles and Scripts
Mar 09, 2016
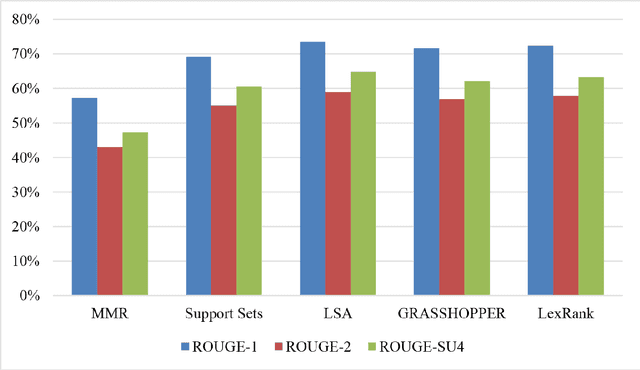
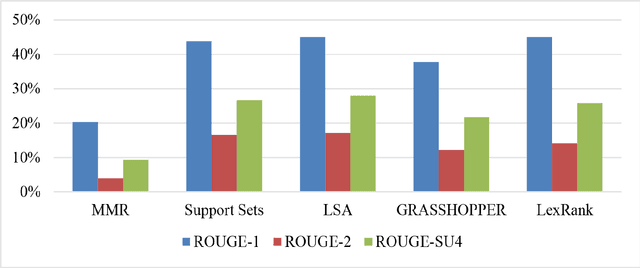
We assess the performance of generic text summarization algorithms applied to films and documentaries, using the well-known behavior of summarization of news articles as reference. We use three datasets: (i) news articles, (ii) film scripts and subtitles, and (iii) documentary subtitles. Standard ROUGE metrics are used for comparing generated summaries against news abstracts, plot summaries, and synopses. We show that the best performing algorithms are LSA, for news articles and documentaries, and LexRank and Support Sets, for films. Despite the different nature of films and documentaries, their relative behavior is in accordance with that obtained for news articles.
* 7 pages, 9 tables, 4 figures, submitted to Pattern Recognition Letters (Elsevier)
Privacy-Preserving Multi-Document Summarization
Aug 06, 2015
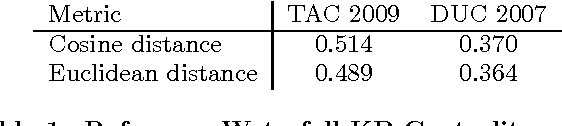

State-of-the-art extractive multi-document summarization systems are usually designed without any concern about privacy issues, meaning that all documents are open to third parties. In this paper we propose a privacy-preserving approach to multi-document summarization. Our approach enables other parties to obtain summaries without learning anything else about the original documents' content. We use a hashing scheme known as Secure Binary Embeddings to convert documents representation containing key phrases and bag-of-words into bit strings, allowing the computation of approximate distances, instead of exact ones. Our experiments indicate that our system yields similar results to its non-private counterpart on standard multi-document evaluation datasets.
Extending a Single-Document Summarizer to Multi-Document: a Hierarchical Approach
Jul 10, 2015
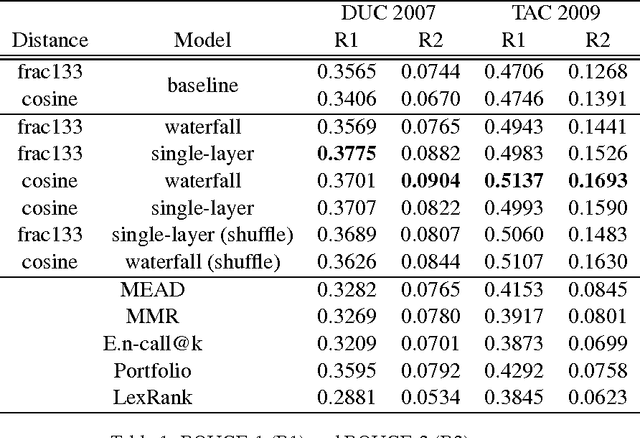
The increasing amount of online content motivated the development of multi-document summarization methods. In this work, we explore straightforward approaches to extend single-document summarization methods to multi-document summarization. The proposed methods are based on the hierarchical combination of single-document summaries, and achieves state of the art results.
Ensemble Detection of Single & Multiple Events at Sentence-Level
Mar 24, 2014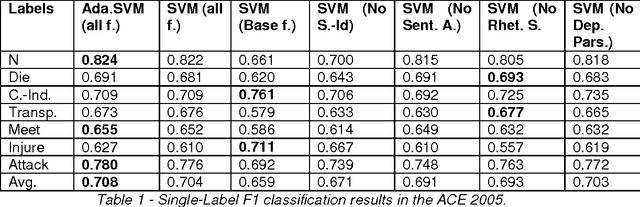
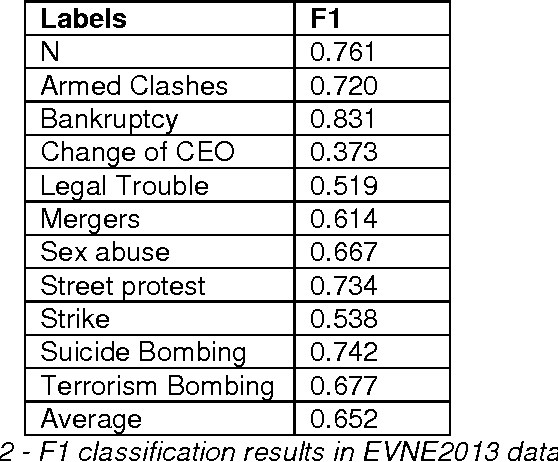
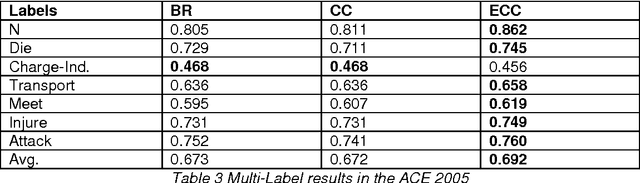
Event classification at sentence level is an important Information Extraction task with applications in several NLP, IR, and personalization systems. Multi-label binary relevance (BR) are the state-of-art methods. In this work, we explored new multi-label methods known for capturing relations between event types. These new methods, such as the ensemble Chain of Classifiers, improve the F1 on average across the 6 labels by 2.8% over the Binary Relevance. The low occurrence of multi-label sentences motivated the reduction of the hard imbalanced multi-label classification problem with low number of occurrences of multiple labels per instance to an more tractable imbalanced multiclass problem with better results (+ 4.6%). We report the results of adding new features, such as sentiment strength, rhetorical signals, domain-id (source-id and date), and key-phrases in both single-label and multi-label event classification scenarios.