 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Meta Lifelong-Learning with Limited Memory
Oct 06, 2020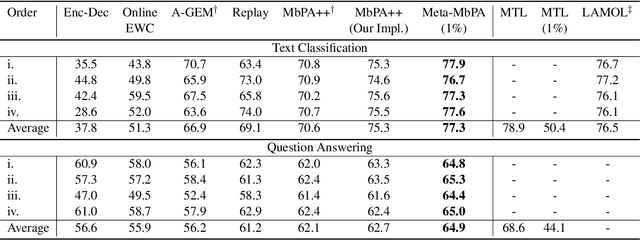
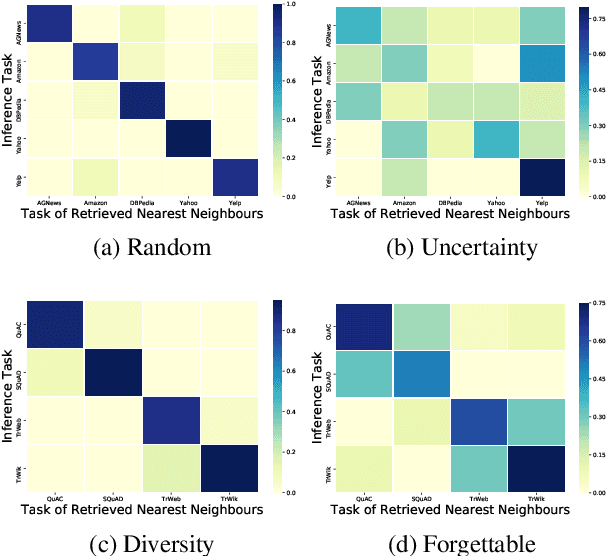
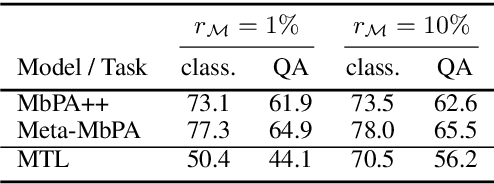
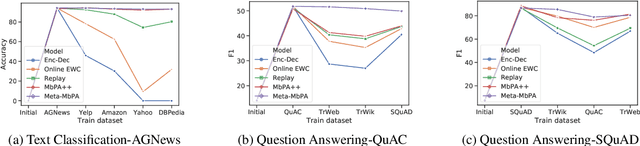
Current natural language processing models work well on a single task, yet they often fail to continuously learn new tasks without forgetting previous ones as they are re-trained throughout their lifetime, a challenge known as lifelong learning. State-of-the-art lifelong language learning methods store past examples in episodic memory and replay them at both training and inference time. However, as we show later in our experiments, there are three significant impediments: (1) needing unrealistically large memory module to achieve good performance, (2) suffering from negative transfer, (3) requiring multiple local adaptation steps for each test example that significantly slows down the inference speed. In this paper, we identify three common principles of lifelong learning methods and propose an efficient meta-lifelong framework that combines them in a synergistic fashion. To achieve sample efficiency, our method trains the model in a manner that it learns a better initialization for local adaptation. Extensive experiments on text classification and question answering benchmarks demonstrate the effectiveness of our framework by achieving state-of-the-art performance using merely 1% memory size and narrowing the gap with multi-task learning. We further show that our method alleviates both catastrophic forgetting and negative transfer at the same time.
Soft Gazetteers for Low-Resource Named Entity Recognition
May 04, 2020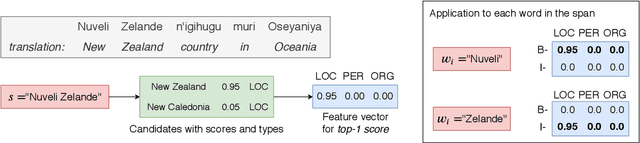
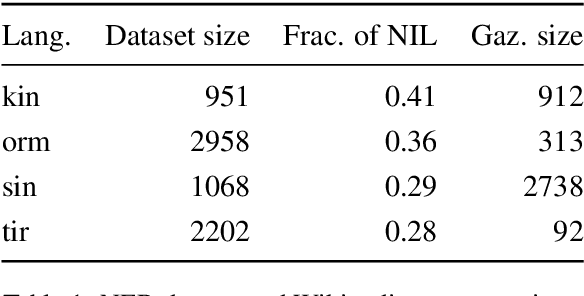
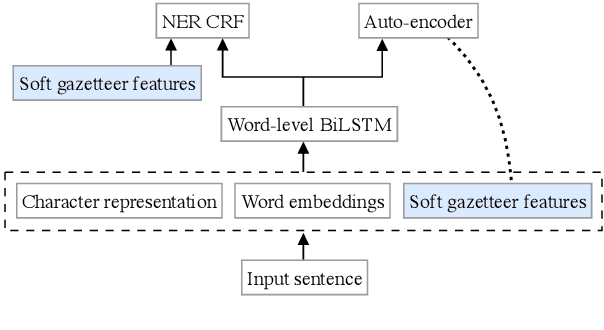
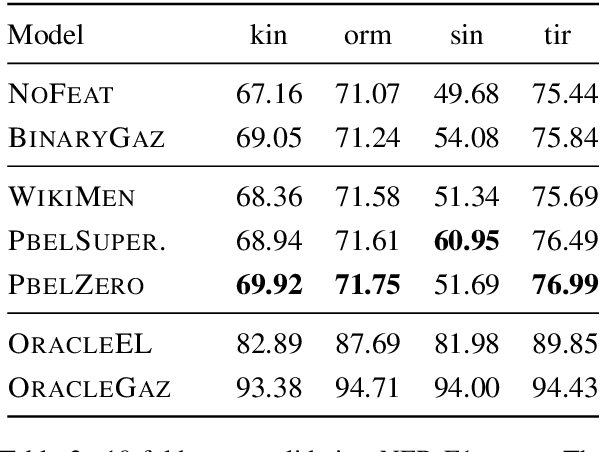
Traditional named entity recognition models use gazetteers (lists of entities) as features to improve performance. Although modern neural network models do not require such hand-crafted features for strong performance, recent work has demonstrated their utility for named entity recognition on English data. However, designing such features for low-resource languages is challenging, because exhaustive entity gazetteers do not exist in these languages. To address this problem, we propose a method of "soft gazetteers" that incorporates ubiquitously available information from English knowledge bases, such as Wikipedia, into neural named entity recognition models through cross-lingual entity linking. Our experiments on four low-resource languages show an average improvement of 4 points in F1 score. Code and data are available at https://github.com/neulab/soft-gazetteers.
Improving Candidate Generation for Low-resource Cross-lingual Entity Linking
Mar 03, 2020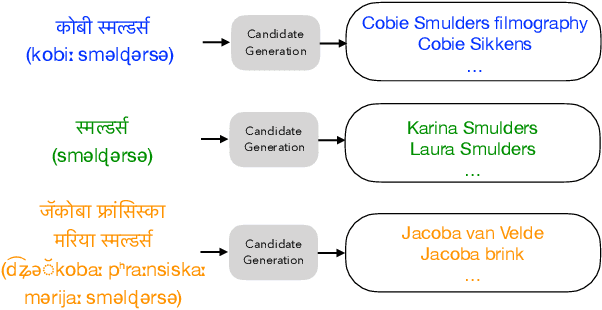
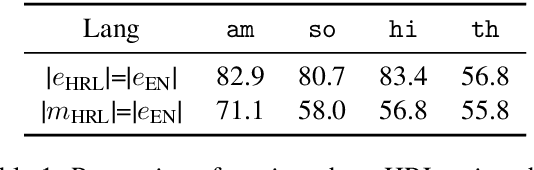
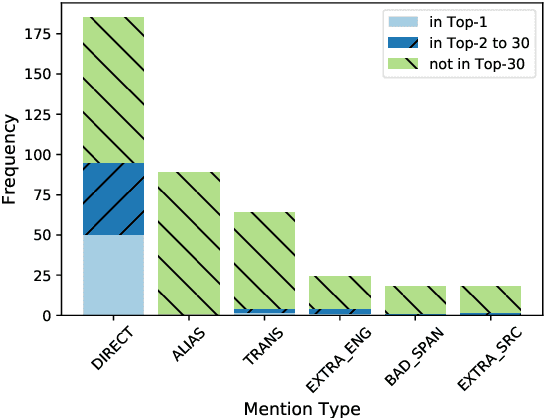
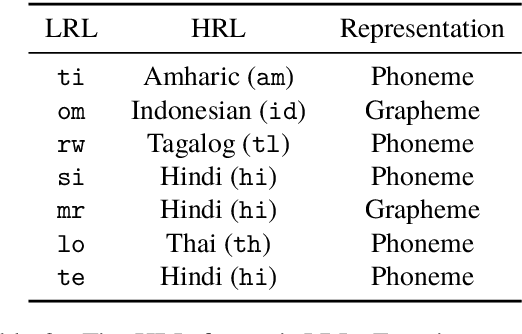
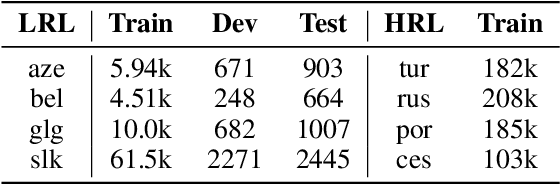
Cross-lingual entity linking (XEL) is the task of finding referents in a target-language knowledge base (KB) for mentions extracted from source-language texts. The first step of (X)EL is candidate generation, which retrieves a list of plausible candidate entities from the target-language KB for each mention. Approaches based on resources from Wikipedia have proven successful in the realm of relatively high-resource languages (HRL), but these do not extend well to low-resource languages (LRL) with few, if any, Wikipedia pages. Recently, transfer learning methods have been shown to reduce the demand for resources in the LRL by utilizing resources in closely-related languages, but the performance still lags far behind their high-resource counterparts. In this paper, we first assess the problems faced by current entity candidate generation methods for low-resource XEL, then propose three improvements that (1) reduce the disconnect between entity mentions and KB entries, and (2) improve the robustness of the model to low-resource scenarios. The methods are simple, but effective: we experiment with our approach on seven XEL datasets and find that they yield an average gain of 16.9% in Top-30 gold candidate recall, compared to state-of-the-art baselines. Our improved model also yields an average gain of 7.9% in in-KB accuracy of end-to-end XEL.
StructSum: Incorporating Latent and Explicit Sentence Dependencies for Single Document Summarization
Mar 01, 2020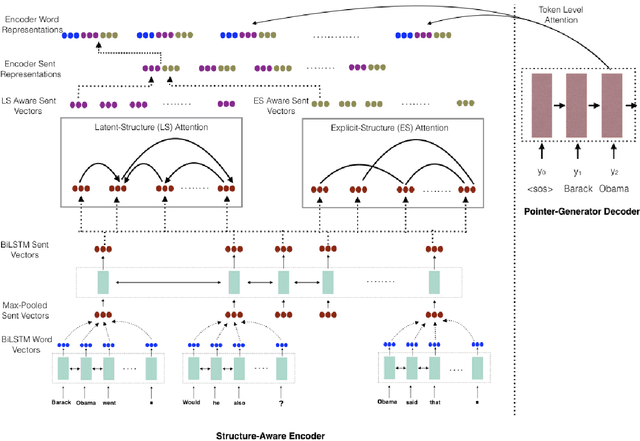
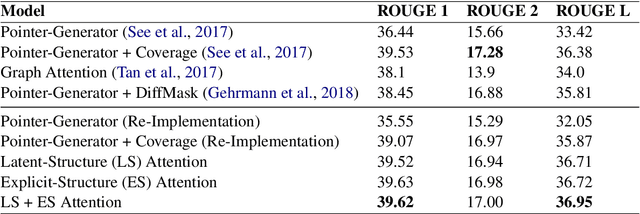
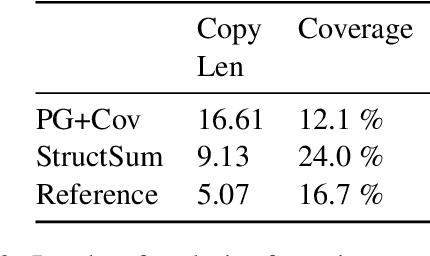
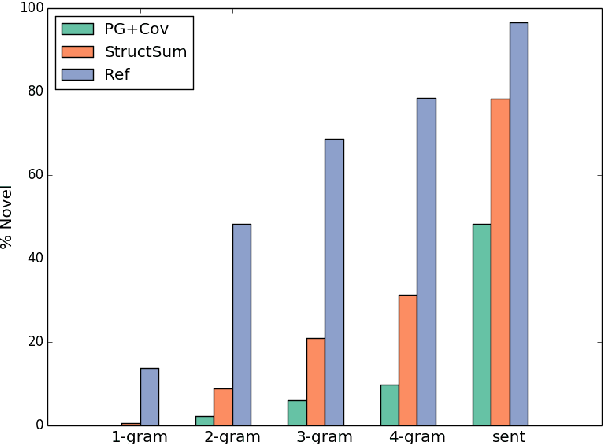
Traditional preneural approaches to single document summarization relied on modeling the intermediate structure of a document before generating the summary. In contrast, the current state of the art neural summarization models do not preserve any intermediate structure, resorting to encoding the document as a sequence of tokens. The goal of this work is two-fold: to improve the quality of generated summaries and to learn interpretable document representations for summarization. To this end, we propose incorporating latent and explicit sentence dependencies into single-document summarization models. We use structure-aware encoders to induce latent sentence relations, and inject explicit coreferring mention graph across sentences to incorporate explicit structure. On the CNN/DM dataset, our model outperforms standard baselines and provides intermediate latent structures for analysis. We present an extensive analysis of our summaries and show that modeling document structure reduces copying long sequences and incorporates richer content from the source document while maintaining comparable summary lengths and an increased degree of abstraction.
Optimizing Data Usage via Differentiable Rewards
Nov 22, 2019


To acquire a new skill, humans learn better and faster if a tutor, based on their current knowledge level, informs them of how much attention they should pay to particular content or practice problems. Similarly, a machine learning model could potentially be trained better with a scorer that "adapts" to its current learning state and estimates the importance of each training data instance. Training such an adaptive scorer efficiently is a challenging problem; in order to precisely quantify the effect of a data instance at a given time during the training, it is typically necessary to first complete the entire training process. To efficiently optimize data usage, we propose a reinforcement learning approach called Differentiable Data Selection (DDS). In DDS, we formulate a scorer network as a learnable function of the training data, which can be efficiently updated along with the main model being trained. Specifically, DDS updates the scorer with an intuitive reward signal: it should up-weigh the data that has a similar gradient with a dev set upon which we would finally like to perform well. Without significant computing overhead, DDS delivers strong and consistent improvements over several strong baselines on two very different tasks of machine translation and image classification.
Cross-lingual Alignment vs Joint Training: A Comparative Study and A Simple Unified Framework
Oct 13, 2019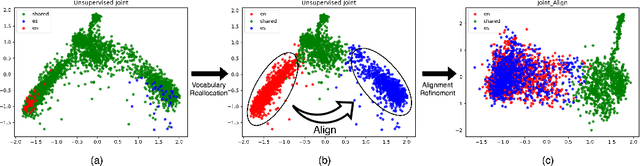
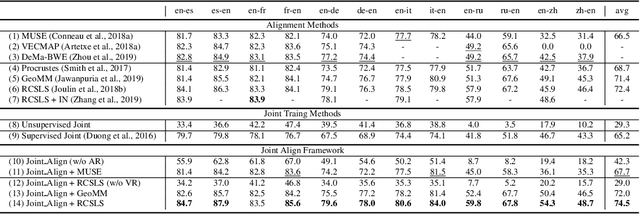


Learning multilingual representations of text has proven a successful method for many cross-lingual transfer learning tasks. There are two main paradigms for learning such representations: (1) alignment, which maps different independently trained monolingual representations into a shared space, and (2) joint training, which directly learns unified multilingual representations using monolingual and cross-lingual objectives jointly. In this paper, we first conduct direct comparisons of representations learned using both of these methods across diverse cross-lingual tasks. Our empirical results reveal a set of pros and cons for both methods, and show that the relative performance of alignment versus joint training is task-dependent. Stemming from this analysis, we propose a simple and novel framework that combines these two previously mutually-exclusive approaches. Extensive experiments on various tasks demonstrate that our proposed framework alleviates limitations of both approaches, and outperforms existing methods on the MUSE bilingual lexicon induction (BLI) benchmark. We further show that our proposed framework can generalize to contextualized representations and achieves state-of-the-art results on the CoNLL cross-lingual NER benchmark.
Learning Rhyming Constraints using Structured Adversaries
Sep 15, 2019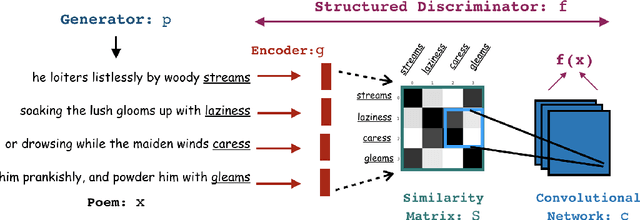


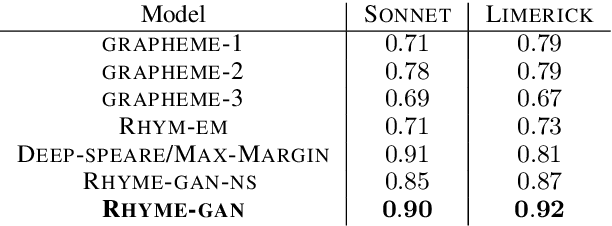
Existing recurrent neural language models often fail to capture higher-level structure present in text: for example, rhyming patterns present in poetry. Much prior work on poetry generation uses manually defined constraints which are satisfied during decoding using either specialized decoding procedures or rejection sampling. The rhyming constraints themselves are typically not learned by the generator. We propose an alternate approach that uses a structured discriminator to learn a poetry generator that directly captures rhyming constraints in a generative adversarial setup. By causing the discriminator to compare poems based only on a learned similarity matrix of pairs of line ending words, the proposed approach is able to successfully learn rhyming patterns in two different English poetry datasets (Sonnet and Limerick) without explicitly being provided with any phonetic information.
XLNet: Generalized Autoregressive Pretraining for Language Understanding
Jun 19, 2019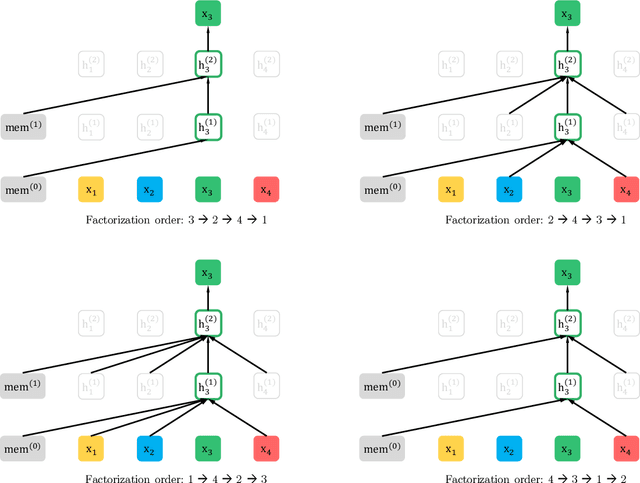

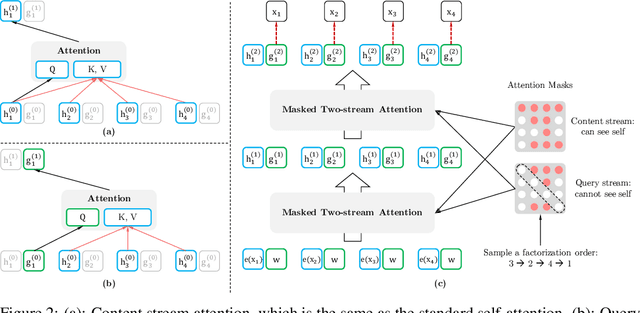

With the capability of modeling bidirectional contexts, denoising autoencoding based pretraining like BERT achieves better performance than pretraining approaches based on autoregressive language modeling. However, relying on corrupting the input with masks, BERT neglects dependency between the masked positions and suffers from a pretrain-finetune discrepancy. In light of these pros and cons, we propose XLNet, a generalized autoregressive pretraining method that (1) enables learning bidirectional contexts by maximizing the expected likelihood over all permutations of the factorization order and (2) overcomes the limitations of BERT thanks to its autoregressive formulation. Furthermore, XLNet integrates ideas from Transformer-XL, the state-of-the-art autoregressive model, into pretraining. Empirically, XLNet outperforms BERT on 20 tasks, often by a large margin, and achieves state-of-the-art results on 18 tasks including question answering, natural language inference, sentiment analysis, and document ranking.
Domain Adaptation of Neural Machine Translation by Lexicon Induction
Jun 02, 2019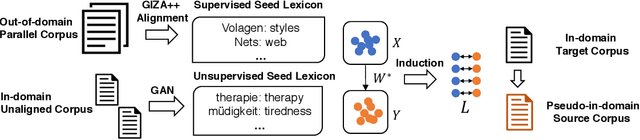
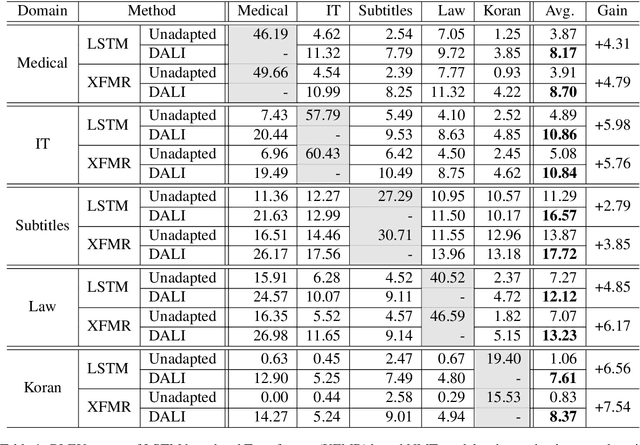
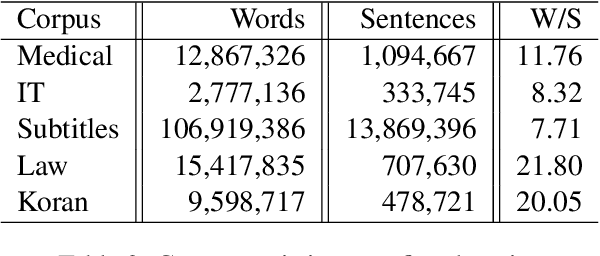
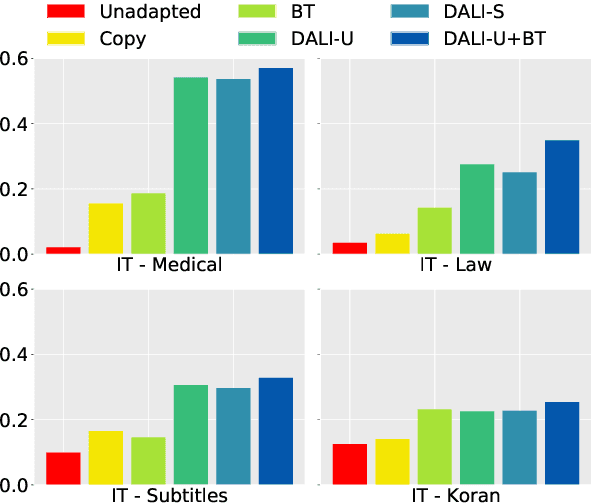
It has been previously noted that neural machine translation (NMT) is very sensitive to domain shift. In this paper, we argue that this is a dual effect of the highly lexicalized nature of NMT, resulting in failure for sentences with large numbers of unknown words, and lack of supervision for domain-specific words. To remedy this problem, we propose an unsupervised adaptation method which fine-tunes a pre-trained out-of-domain NMT model using a pseudo-in-domain corpus. Specifically, we perform lexicon induction to extract an in-domain lexicon, and construct a pseudo-parallel in-domain corpus by performing word-for-word back-translation of monolingual in-domain target sentences. In five domains over twenty pairwise adaptation settings and two model architectures, our method achieves consistent improvements without using any in-domain parallel sentences, improving up to 14 BLEU over unadapted models, and up to 2 BLEU over strong back-translation baselines.
The ARIEL-CMU Systems for LoReHLT18
Feb 24, 2019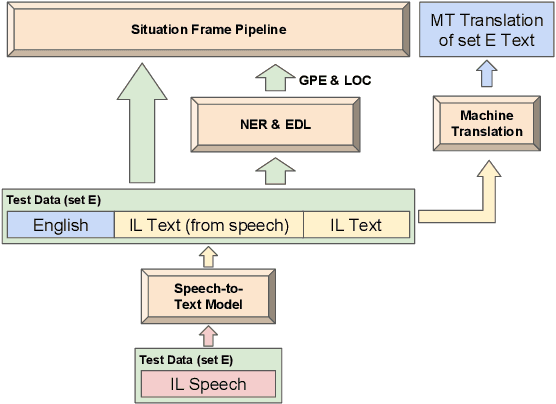
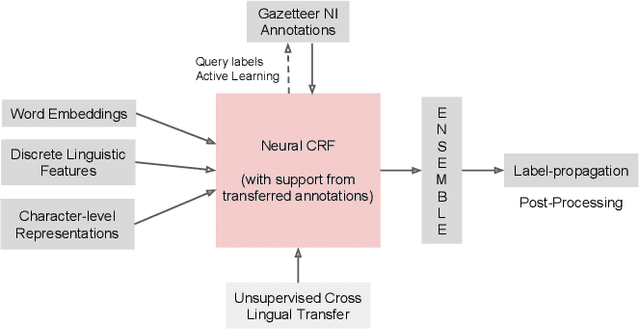
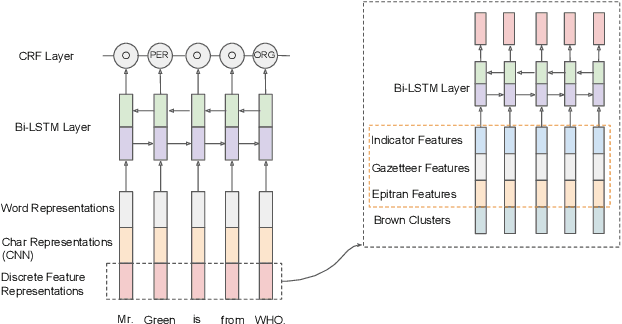
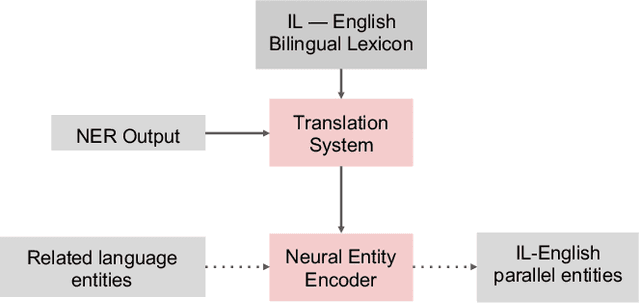
This paper describes the ARIEL-CMU submissions to the Low Resource Human Language Technologies (LoReHLT) 2018 evaluations for the tasks Machine Translation (MT), Entity Discovery and Linking (EDL), and detection of Situation Frames in Text and Speech (SF Text and Speech).