 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Meta Lifelong-Learning with Limited Memory
Paper and Code
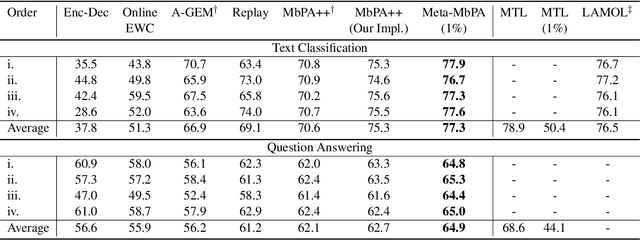
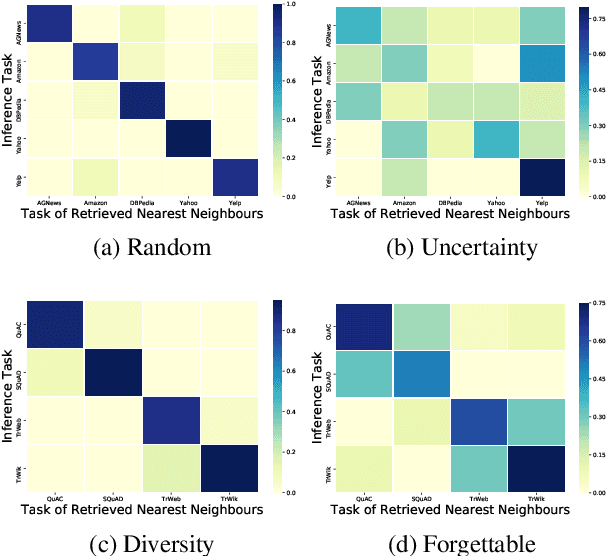
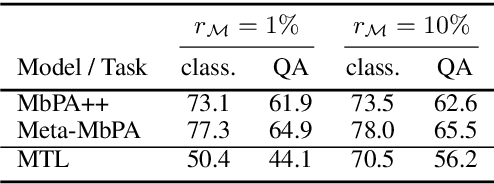
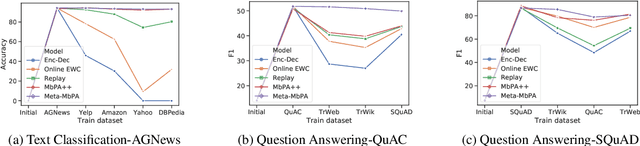
Current natural language processing models work well on a single task, yet they often fail to continuously learn new tasks without forgetting previous ones as they are re-trained throughout their lifetime, a challenge known as lifelong learning. State-of-the-art lifelong language learning methods store past examples in episodic memory and replay them at both training and inference time. However, as we show later in our experiments, there are three significant impediments: (1) needing unrealistically large memory module to achieve good performance, (2) suffering from negative transfer, (3) requiring multiple local adaptation steps for each test example that significantly slows down the inference speed. In this paper, we identify three common principles of lifelong learning methods and propose an efficient meta-lifelong framework that combines them in a synergistic fashion. To achieve sample efficiency, our method trains the model in a manner that it learns a better initialization for local adaptation. Extensive experiments on text classification and question answering benchmarks demonstrate the effectiveness of our framework by achieving state-of-the-art performance using merely 1% memory size and narrowing the gap with multi-task learning. We further show that our method alleviates both catastrophic forgetting and negative transfer at the same time.