 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructSum: Incorporating Latent and Explicit Sentence Dependencies for Single Document Summarization
Paper and Code
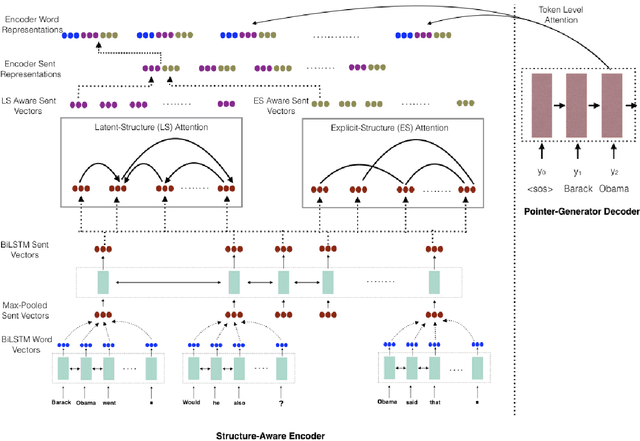
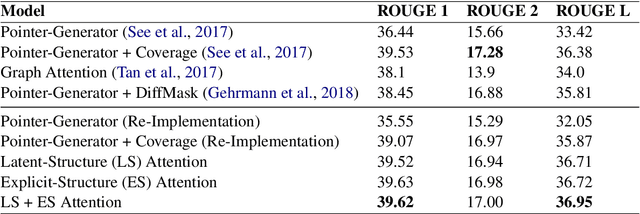
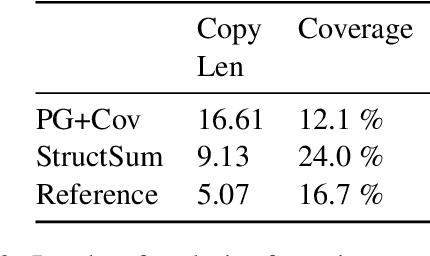
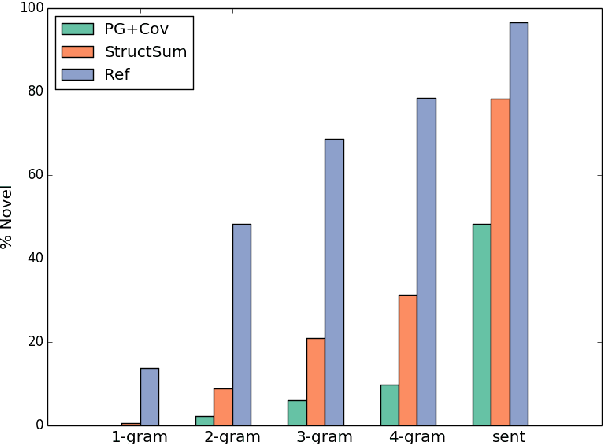
Traditional preneural approaches to single document summarization relied on modeling the intermediate structure of a document before generating the summary. In contrast, the current state of the art neural summarization models do not preserve any intermediate structure, resorting to encoding the document as a sequence of tokens. The goal of this work is two-fold: to improve the quality of generated summaries and to learn interpretable document representations for summarization. To this end, we propose incorporating latent and explicit sentence dependencies into single-document summarization models. We use structure-aware encoders to induce latent sentence relations, and inject explicit coreferring mention graph across sentences to incorporate explicit structure. On the CNN/DM dataset, our model outperforms standard baselines and provides intermediate latent structures for analysis. We present an extensive analysis of our summaries and show that modeling document structure reduces copying long sequences and incorporates richer content from the source document while maintaining comparable summary lengths and an increased degree of abstraction.