 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQE-EBM: Using Quality Estimators as Energy Loss for Machine Translation
Oct 14, 2024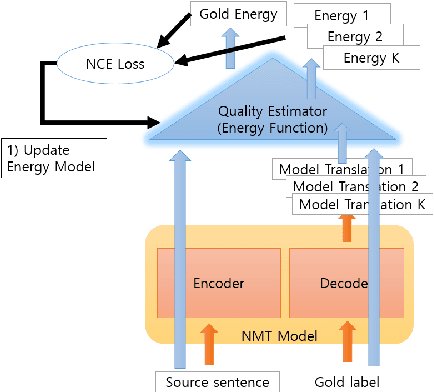



Reinforcement learning has shown great promise in aligning language models with human preferences in a variety of text generation tasks, including machine translation. For translation tasks, rewards can easily be obtained from quality estimation (QE) models which can generate rewards for unlabeled data. Despite its usefulness, reinforcement learning cannot exploit the gradients with respect to the QE score. We propose QE-EBM, a method of employing quality estimators as trainable loss networks that can directly backpropagate to the NMT model. We examine our method on several low and high resource target languages with English as the source language. QE-EBM outperforms strong baselines such as REINFORCE and proximal policy optimization (PPO) as well as supervised fine-tuning for all target languages, especially low-resource target languages. Most notably, for English-to-Mongolian translation, our method achieves improvements of 2.5 BLEU, 7.1 COMET-KIWI, 5.3 COMET, and 6.4 XCOMET relative to the supervised baseline.
Improved Latent Tree Induction with Distant Supervision via Span Constraints
Sep 10, 2021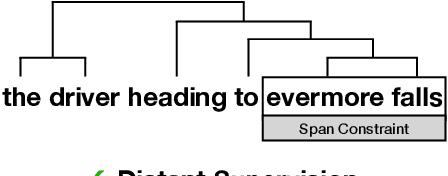

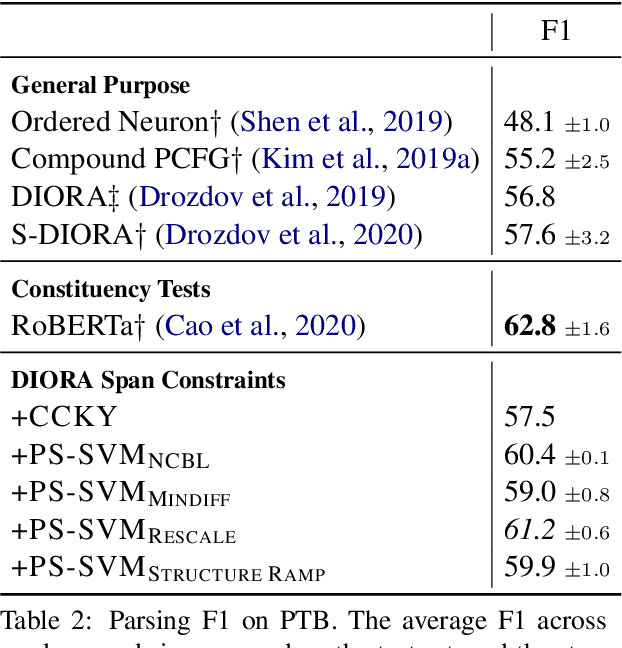
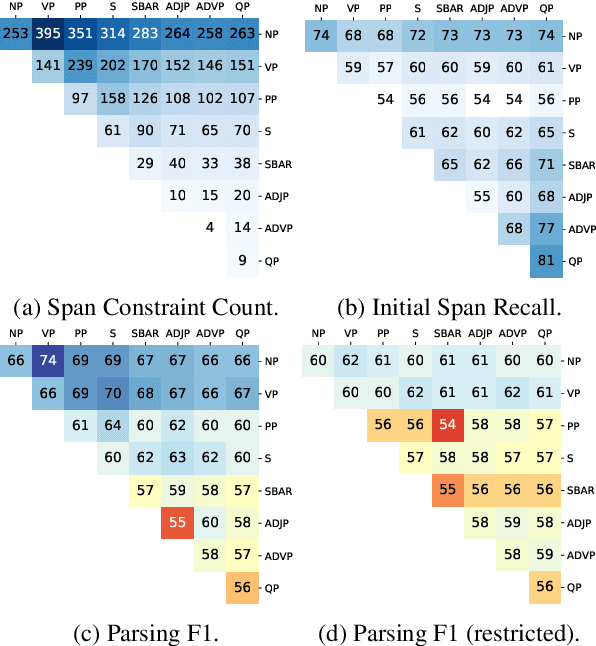
For over thirty years, researchers have developed and analyzed methods for latent tree induction as an approach for unsupervised syntactic parsing. Nonetheless, modern systems still do not perform well enough compared to their supervised counterparts to have any practical use as structural annotation of text. In this work, we present a technique that uses distant supervision in the form of span constraints (i.e. phrase bracketing) to improve performance in unsupervised constituency parsing. Using a relatively small number of span constraints we can substantially improve the output from DIORA, an already competitive unsupervised parsing system. Compared with full parse tree annotation, span constraints can be acquired with minimal effort, such as with a lexicon derived from Wikipedia, to find exact text matches. Our experiments show span constraints based on entities improves constituency parsing on English WSJ Penn Treebank by more than 5 F1. Furthermore, our method extends to any domain where span constraints are easily attainable, and as a case study we demonstrate its effectiveness by parsing biomedical text from the CRAFT dataset.
StructSum: Incorporating Latent and Explicit Sentence Dependencies for Single Document Summarization
Mar 01, 2020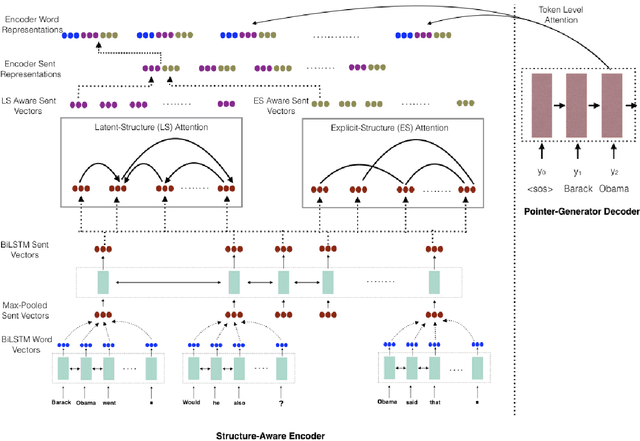
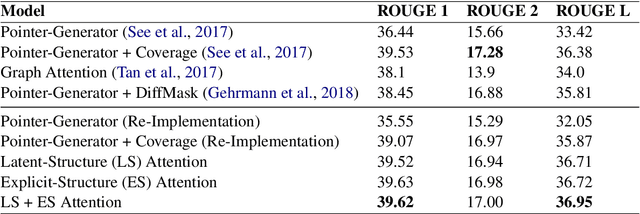
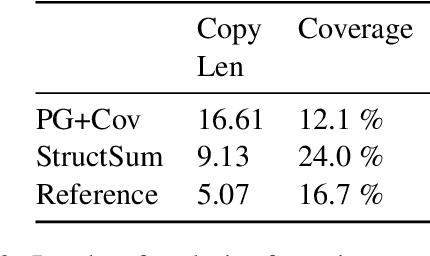
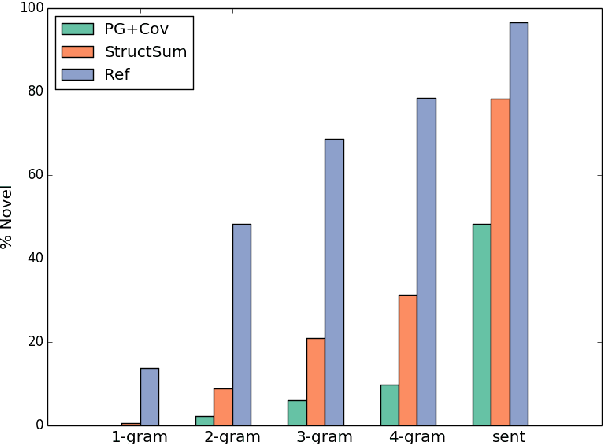
Traditional preneural approaches to single document summarization relied on modeling the intermediate structure of a document before generating the summary. In contrast, the current state of the art neural summarization models do not preserve any intermediate structure, resorting to encoding the document as a sequence of tokens. The goal of this work is two-fold: to improve the quality of generated summaries and to learn interpretable document representations for summarization. To this end, we propose incorporating latent and explicit sentence dependencies into single-document summarization models. We use structure-aware encoders to induce latent sentence relations, and inject explicit coreferring mention graph across sentences to incorporate explicit structure. On the CNN/DM dataset, our model outperforms standard baselines and provides intermediate latent structures for analysis. We present an extensive analysis of our summaries and show that modeling document structure reduces copying long sequences and incorporates richer content from the source document while maintaining comparable summary lengths and an increased degree of abstraction.
Towards Semi-Supervised Learning for Deep Semantic Role Labeling
Aug 28, 2018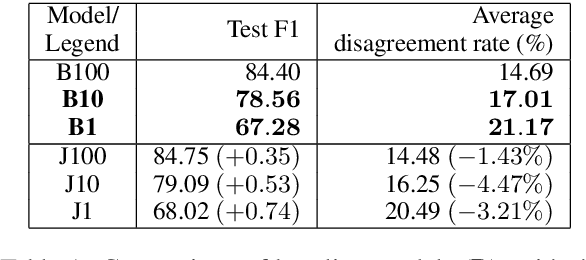
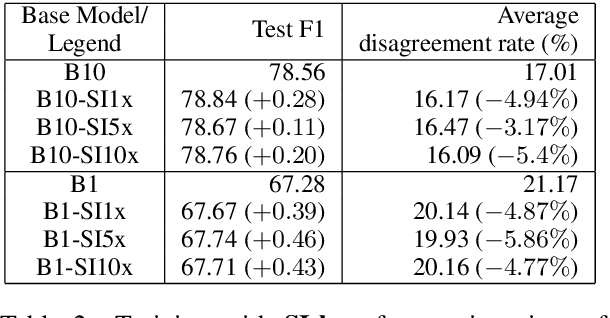
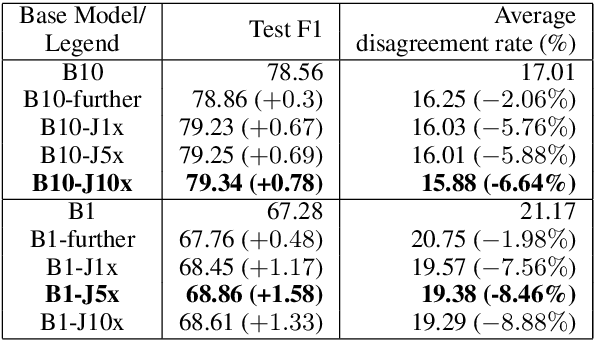
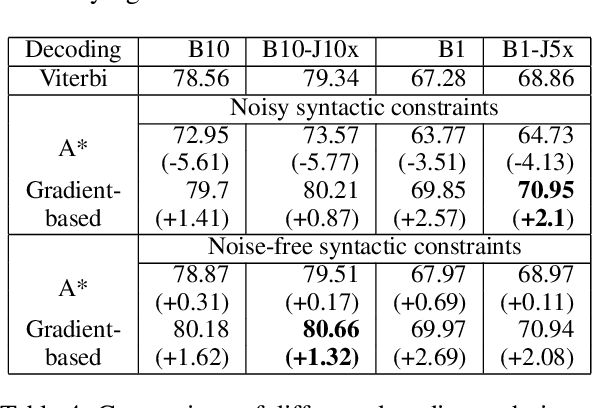
Neural models have shown several state-of-the-art performances on Semantic Role Labeling (SRL). However, the neural models require an immense amount of semantic-role corpora and are thus not well suited for low-resource languages or domains. The paper proposes a semi-supervised semantic role labeling method that outperforms the state-of-the-art in limited SRL training corpora. The method is based on explicitly enforcing syntactic constraints by augmenting the training objective with a syntactic-inconsistency loss component and uses SRL-unlabeled instances to train a joint-objective LSTM. On CoNLL-2012 English section, the proposed semi-supervised training with 1%, 10% SRL-labeled data and varying amounts of SRL-unlabeled data achieves +1.58, +0.78 F1, respectively, over the pre-trained models that were trained on SOTA architecture with ELMo on the same SRL-labeled data. Additionally, by using the syntactic-inconsistency loss on inference time, the proposed model achieves +3.67, +2.1 F1 over pre-trained model on 1%, 10% SRL-labeled data, respectively.
Gradient-based Inference for Networks with Output Constraints
Aug 26, 2018


Practitioners apply neural networks to increasingly complex problems in natural language processing (NLP), such as syntactic parsing that have rich output structures. Many such structured-prediction problems require deterministic constraints on the output values; for example, in sequence-to-sequence syntactic parsing, we require that the sequential outputs encode valid trees. While hidden units might capture such properties, the network is not always able to learn such constraints from the training data alone, and practitioners must then resort to post-processing. In this paper, we present an inference method for neural networks that enforces deterministic constraints on outputs without performing rule-based post-processing or expensive discrete search. Instead, in the spirit of gradient-based training, we enforce constraints with gradient-based inference: for each input at test-time, we nudge continuous weights until the network's unconstrained inference procedure generates an output that satisfies the constraints. We apply our methods to three tasks with hard constraints: sequence transduction, constituency parsing, and semantic role labeling (SRL). In each case, the algorithm not only satisfies constraints but improves accuracy, even when the underlying network is state-of-the-art.