 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeByte Latent Transformer: Patches Scale Better Than Tokens
Dec 13, 2024We introduce the Byte Latent Transformer (BLT), a new byte-level LLM architecture that, for the first time, matches tokenization-based LLM performance at scale with significant improvements in inference efficiency and robustness. BLT encodes bytes into dynamically sized patches, which serve as the primary units of computation. Patches are segmented based on the entropy of the next byte, allocating more compute and model capacity where increased data complexity demands it. We present the first FLOP controlled scaling study of byte-level models up to 8B parameters and 4T training bytes. Our results demonstrate the feasibility of scaling models trained on raw bytes without a fixed vocabulary. Both training and inference efficiency improve due to dynamically selecting long patches when data is predictable, along with qualitative improvements on reasoning and long tail generalization. Overall, for fixed inference costs, BLT shows significantly better scaling than tokenization-based models, by simultaneously growing both patch and model size.
Predicting vs. Acting: A Trade-off Between World Modeling & Agent Modeling
Jul 02, 2024
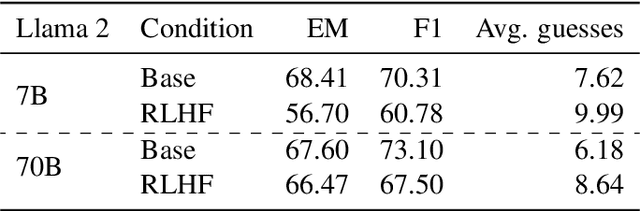


RLHF-aligned LMs have shown unprecedented ability on both benchmarks and long-form text generation, yet they struggle with one foundational task: next-token prediction. As RLHF models become agent models aimed at interacting with humans, they seem to lose their world modeling -- the ability to predict what comes next in arbitrary documents, which is the foundational training objective of the Base LMs that RLHF adapts. Besides empirically demonstrating this trade-off, we propose a potential explanation: to perform coherent long-form generation, RLHF models restrict randomness via implicit blueprints. In particular, RLHF models concentrate probability on sets of anchor spans that co-occur across multiple generations for the same prompt, serving as textual scaffolding but also limiting a model's ability to generate documents that do not include these spans. We study this trade-off on the most effective current agent models, those aligned with RLHF, while exploring why this may remain a fundamental trade-off between models that act and those that predict, even as alignment techniques improve.
QLoRA: Efficient Finetuning of Quantized LLMs
May 23, 2023



We present QLoRA, an efficient finetuning approach that reduces memory usage enough to finetune a 65B parameter model on a single 48GB GPU while preserving full 16-bit finetuning task performance. QLoRA backpropagates gradients through a frozen, 4-bit quantized pretrained language model into Low Rank Adapters~(LoRA). Our best model family, which we name Guanaco, outperforms all previous openly released models on the Vicuna benchmark, reaching 99.3% of the performance level of ChatGPT while only requiring 24 hours of finetuning on a single GPU. QLoRA introduces a number of innovations to save memory without sacrificing performance: (a) 4-bit NormalFloat (NF4), a new data type that is information theoretically optimal for normally distributed weights (b) double quantization to reduce the average memory footprint by quantizing the quantization constants, and (c) paged optimziers to manage memory spikes. We use QLoRA to finetune more than 1,000 models, providing a detailed analysis of instruction following and chatbot performance across 8 instruction datasets, multiple model types (LLaMA, T5), and model scales that would be infeasible to run with regular finetuning (e.g. 33B and 65B parameter models). Our results show that QLoRA finetuning on a small high-quality dataset leads to state-of-the-art results, even when using smaller models than the previous SoTA. We provide a detailed analysis of chatbot performance based on both human and GPT-4 evaluations showing that GPT-4 evaluations are a cheap and reasonable alternative to human evaluation. Furthermore, we find that current chatbot benchmarks are not trustworthy to accurately evaluate the performance levels of chatbots. A lemon-picked analysis demonstrates where Guanaco fails compared to ChatGPT. We release all of our models and code, including CUDA kernels for 4-bit training.
Socratic Pretraining: Question-Driven Pretraining for Controllable Summarization
Dec 20, 2022
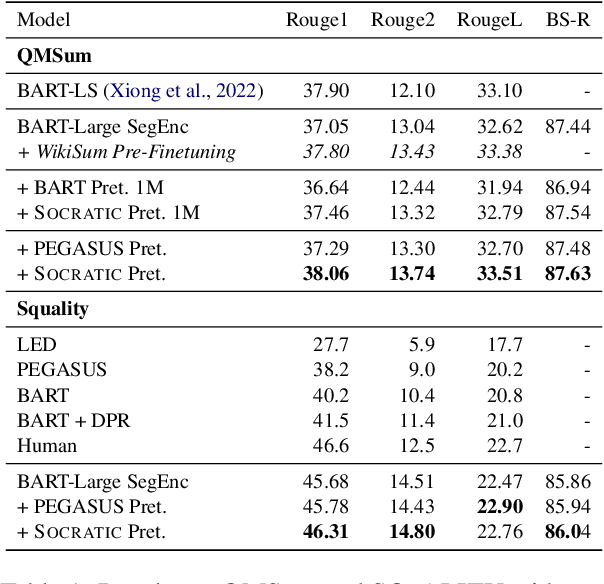
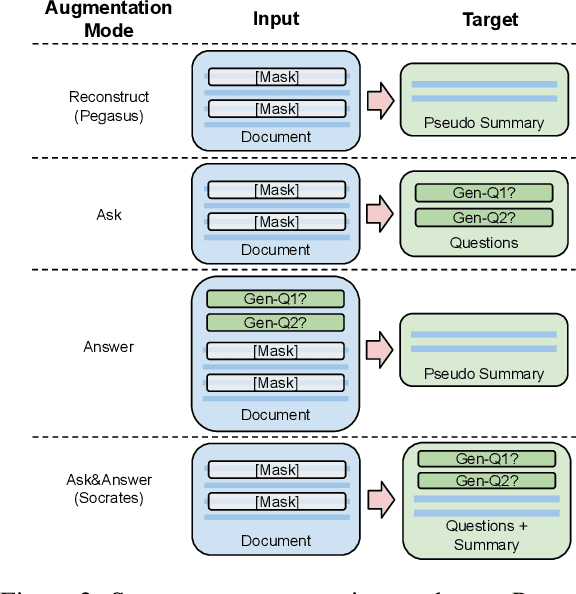
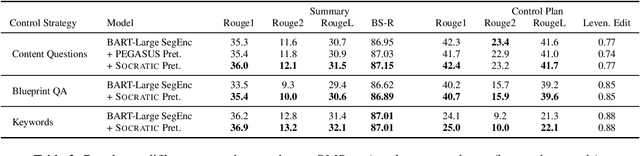
In long document controllable summarization, where labeled data is scarce, pretrained models struggle to adapt to the task and effectively respond to user queries. In this paper, we introduce Socratic pretraining, a question-driven, unsupervised pretraining objective specifically designed to improve controllability in summarization tasks. By training a model to generate and answer relevant questions in a given context, Socratic pretraining enables the model to more effectively adhere to user-provided queries and identify relevant content to be summarized. We demonstrate the effectiveness of this approach through extensive experimentation on two summarization domains, short stories and dialogue, and multiple control strategies: keywords, questions, and factoid QA pairs. Our pretraining method relies only on unlabeled documents and a question generation system and outperforms pre-finetuning approaches that use additional supervised data. Furthermore, our results show that Socratic pretraining cuts task-specific labeled data requirements in half, is more faithful to user-provided queries, and achieves state-of-the-art performance on QMSum and SQuALITY.
EvEntS ReaLM: Event Reasoning of Entity States via Language Models
Nov 10, 2022



This paper investigates models of event implications. Specifically, how well models predict entity state-changes, by targeting their understanding of physical attributes. Nominally, Large Language models (LLM) have been exposed to procedural knowledge about how objects interact, yet our benchmarking shows they fail to reason about the world. Conversely, we also demonstrate that existing approaches often misrepresent the surprising abilities of LLMs via improper task encodings and that proper model prompting can dramatically improve performance of reported baseline results across multiple tasks. In particular, our results indicate that our prompting technique is especially useful for unseen attributes (out-of-domain) or when only limited data is available.
Understanding Factuality in Abstractive Summarization with FRANK: A Benchmark for Factuality Metrics
Apr 27, 2021

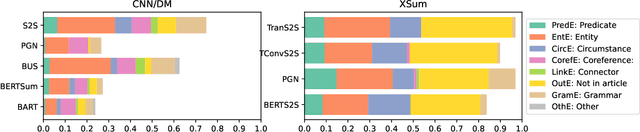
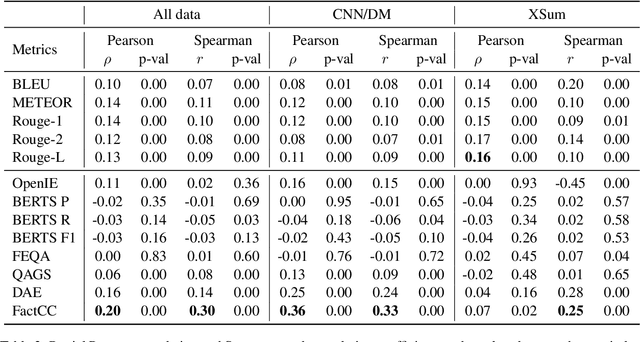
Modern summarization models generate highly fluent but often factually unreliable outputs. This motivated a surge of metrics attempting to measure the factuality of automatically generated summaries. Due to the lack of common benchmarks, these metrics cannot be compared. Moreover, all these methods treat factuality as a binary concept and fail to provide deeper insights into the kinds of inconsistencies made by different systems. To address these limitations, we devise a typology of factual errors and use it to collect human annotations of generated summaries from state-of-the-art summarization systems for the CNN/DM and XSum datasets. Through these annotations, we identify the proportion of different categories of factual errors in various summarization models and benchmark factuality metrics, showing their correlation with human judgment as well as their specific strengths and weaknesses.
StructSum: Incorporating Latent and Explicit Sentence Dependencies for Single Document Summarization
Mar 01, 2020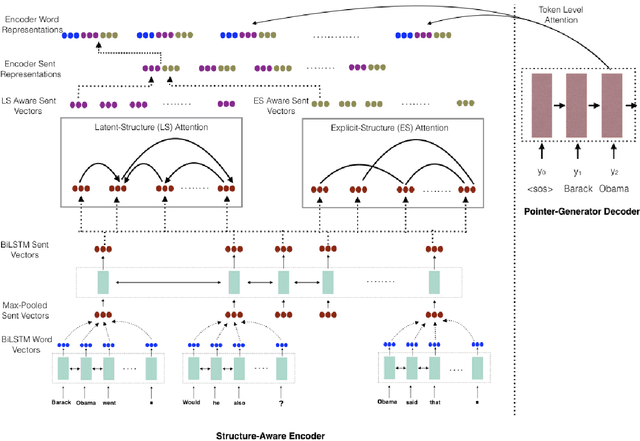
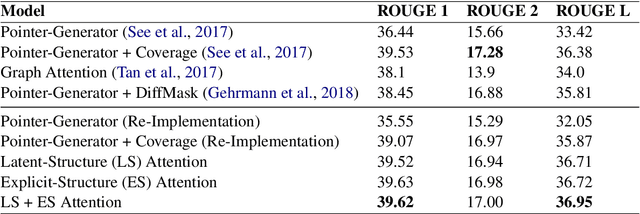
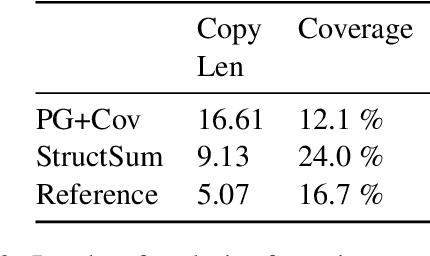
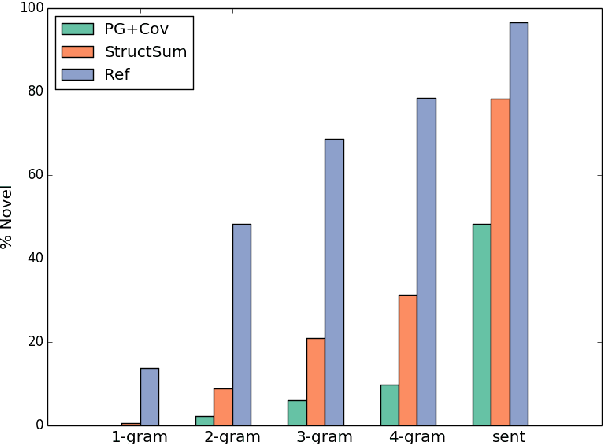
Traditional preneural approaches to single document summarization relied on modeling the intermediate structure of a document before generating the summary. In contrast, the current state of the art neural summarization models do not preserve any intermediate structure, resorting to encoding the document as a sequence of tokens. The goal of this work is two-fold: to improve the quality of generated summaries and to learn interpretable document representations for summarization. To this end, we propose incorporating latent and explicit sentence dependencies into single-document summarization models. We use structure-aware encoders to induce latent sentence relations, and inject explicit coreferring mention graph across sentences to incorporate explicit structure. On the CNN/DM dataset, our model outperforms standard baselines and provides intermediate latent structures for analysis. We present an extensive analysis of our summaries and show that modeling document structure reduces copying long sequences and incorporates richer content from the source document while maintaining comparable summary lengths and an increased degree of abstraction.
Making Classical Machine Learning Pipelines Differentiable: A Neural Translation Approach
Jun 10, 2019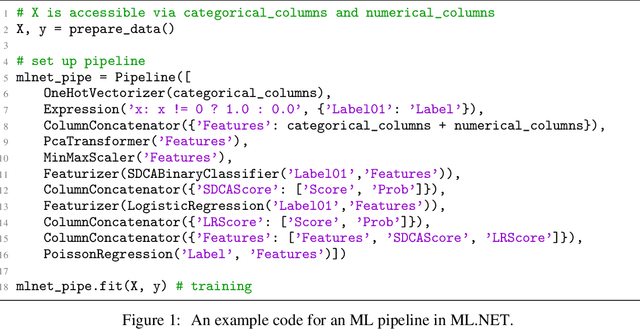

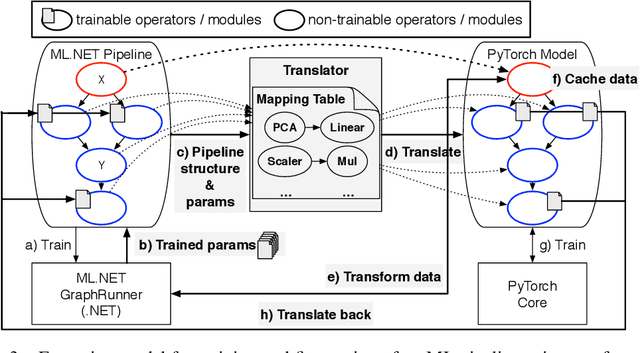
Classical Machine Learning (ML) pipelines often comprise of multiple ML models where models, within a pipeline, are trained in isolation. Conversely, when training neural network models, layers composing the neural models are simultaneously trained using backpropagation. We argue that the isolated training scheme of ML pipelines is sub-optimal, since it cannot jointly optimize multiple components. To this end, we propose a framework that translates a pre-trained ML pipeline into a neural network and fine-tunes the ML models within the pipeline jointly using backpropagation. Our experiments show that fine-tuning of the translated pipelines is a promising technique able to increase the final accuracy.
Machine Learning at Microsoft with ML .NET
May 15, 2019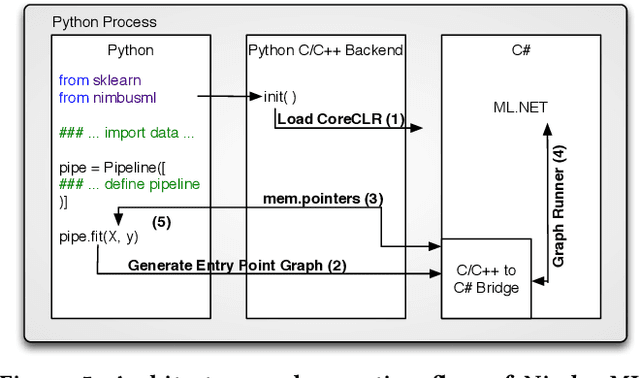
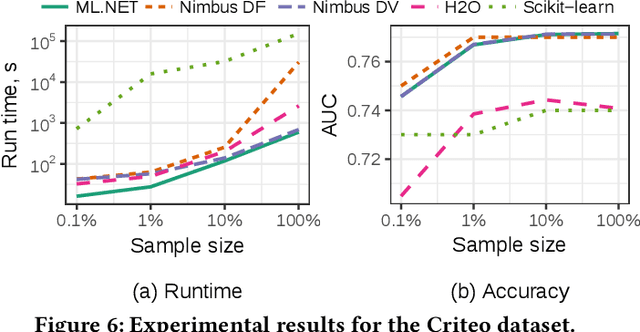
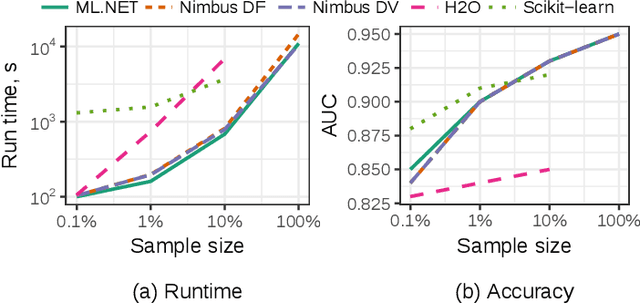
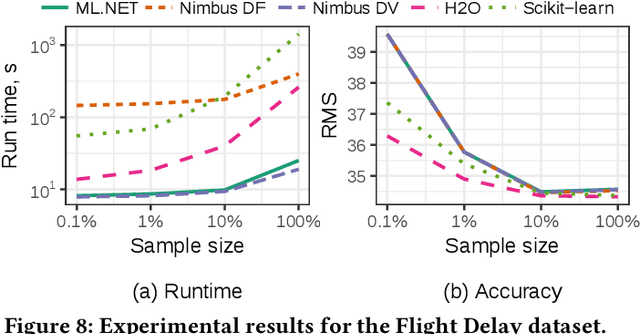
Machine Learning is transitioning from an art and science into a technology available to every developer. In the near future, every application on every platform will incorporate trained models to encode data-based decisions that would be impossible for developers to author. This presents a significant engineering challenge, since currently data science and modeling are largely decoupled from standard software development processes. This separation makes incorporating machine learning capabilities inside applications unnecessarily costly and difficult, and furthermore discourage developers from embracing ML in first place. In this paper we present ML .NET, a framework developed at Microsoft over the last decade in response to the challenge of making it easy to ship machine learning models in large software applications. We present its architecture, and illuminate the application demands that shaped it. Specifically, we introduce DataView, the core data abstraction of ML .NET which allows it to capture full predictive pipelines efficiently and consistently across training and inference lifecycles. We close the paper with a surprisingly favorable performance study of ML .NET compared to more recent entrants, and a discussion of some lessons learned.
PAC Learning Guarantees Under Covariate Shift
Dec 16, 2018We consider the Domain Adaptation problem, also known as the covariate shift problem, where the distributions that generate the training and test data differ while retaining the same labeling function. This problem occurs across a large range of practical applications, and is related to the more general challenge of transfer learning. Most recent work on the topic focuses on optimization techniques that are specific to an algorithm or practical use case rather than a more general approach. The sparse literature attempting to provide general bounds seems to suggest that efficient learning even under strong assumptions is not possible for covariate shift. Our main contribution is to recontextualize these results by showing that any Probably Approximately Correct (PAC) learnable concept class is still PAC learnable under covariate shift conditions with only a polynomial increase in the number of training samples. This approach essentially demonstrates that the Domain Adaptation learning problem is as hard as the underlying PAC learning problem, provided some conditions over the training and test distributions. We also present bounds for the rejection sampling algorithm, justifying it as a solution to the Domain Adaptation problem in certain scenarios.