 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Self-Attention: Generalizing Neural Attention Mechanics to Multi-Scale Problems
Sep 18, 2025



Transformers and their attention mechanism have been revolutionary in the field of Machine Learning. While originally proposed for the language data, they quickly found their way to the image, video, graph, etc. data modalities with various signal geometries. Despite this versatility, generalizing the attention mechanism to scenarios where data is presented at different scales from potentially different modalities is not straightforward. The attempts to incorporate hierarchy and multi-modality within transformers are largely based on ad hoc heuristics, which are not seamlessly generalizable to similar problems with potentially different structures. To address this problem, in this paper, we take a fundamentally different approach: we first propose a mathematical construct to represent multi-modal, multi-scale data. We then mathematically derive the neural attention mechanics for the proposed construct from the first principle of entropy minimization. We show that the derived formulation is optimal in the sense of being the closest to the standard Softmax attention while incorporating the inductive biases originating from the hierarchical/geometric information of the problem. We further propose an efficient algorithm based on dynamic programming to compute our derived attention mechanism. By incorporating it within transformers, we show that the proposed hierarchical attention mechanism not only can be employed to train transformer models in hierarchical/multi-modal settings from scratch, but it can also be used to inject hierarchical information into classical, pre-trained transformer models post training, resulting in more efficient models in zero-shot manner.
Weakly-supervised Audio Separation via Bi-modal Semantic Similarity
Apr 02, 2024



Conditional sound separation in multi-source audio mixtures without having access to single source sound data during training is a long standing challenge. Existing mix-and-separate based methods suffer from significant performance drop with multi-source training mixtures due to the lack of supervision signal for single source separation cases during training. However, in the case of language-conditional audio separation, we do have access to corresponding text descriptions for each audio mixture in our training data, which can be seen as (rough) representations of the audio samples in the language modality. To this end, in this paper, we propose a generic bi-modal separation framework which can enhance the existing unsupervised frameworks to separate single-source signals in a target modality (i.e., audio) using the easily separable corresponding signals in the conditioning modality (i.e., language), without having access to single-source samples in the target modality during training. We empirically show that this is well within reach if we have access to a pretrained joint embedding model between the two modalities (i.e., CLAP). Furthermore, we propose to incorporate our framework into two fundamental scenarios to enhance separation performance. First, we show that our proposed methodology significantly improves the performance of purely unsupervised baselines by reducing the distribution shift between training and test samples. In particular, we show that our framework can achieve 71% boost in terms of Signal-to-Distortion Ratio (SDR) over the baseline, reaching 97.5% of the supervised learning performance. Second, we show that we can further improve the performance of the supervised learning itself by 17% if we augment it by our proposed weakly-supervised framework, that enables a powerful semi-supervised framework for audio separation.
Neuro-Symbolic Visual Reasoning: Disentangling "Visual" from "Reasoning"
Jun 30, 2020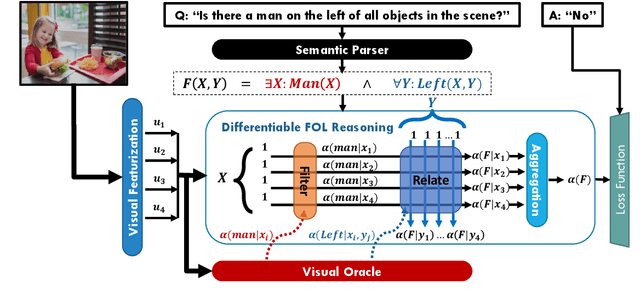
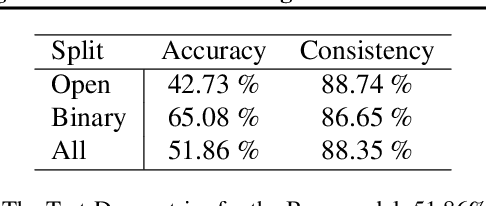
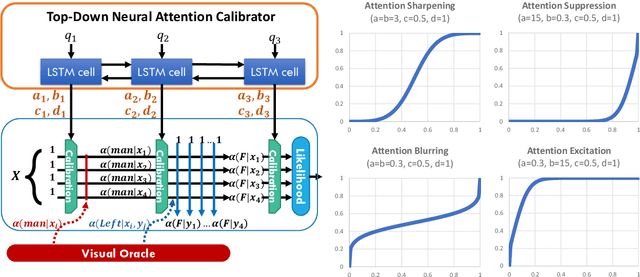
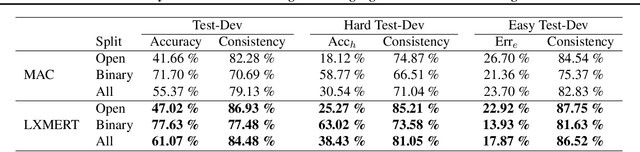
Visual reasoning tasks such as visual question answering (VQA) require an interplay of visual perception with reasoning about the question semantics grounded in perception. Various benchmarks for reasoning across language and vision like VQA, VCR and more recently GQA for compositional question answering facilitate scientific progress from perception models to visual reasoning. However, recent advances are still primarily driven by perception improvements (e.g. scene graph generation) rather than reasoning. Neuro-symbolic models such as Neural Module Networks bring the benefits of compositional reasoning to VQA, but they are still entangled with visual representation learning, and thus neural reasoning is hard to improve and assess on its own. To address this, we propose (1) a framework to isolate and evaluate the reasoning aspect of VQA separately from its perception, and (2) a novel top-down calibration technique that allows the model to answer reasoning questions even with imperfect perception. To this end, we introduce a differentiable first-order logic formalism for VQA that explicitly decouples question answering from visual perception. On the challenging GQA dataset, this framework is used to perform in-depth, disentangled comparisons between well-known VQA models leading to informative insights regarding the participating models as well as the task.
Making Classical Machine Learning Pipelines Differentiable: A Neural Translation Approach
Jun 10, 2019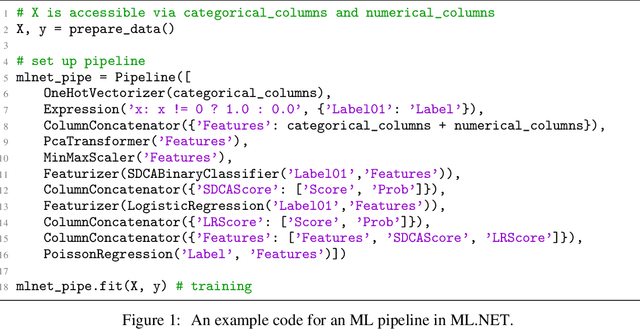

Classical Machine Learning (ML) pipelines often comprise of multiple ML models where models, within a pipeline, are trained in isolation. Conversely, when training neural network models, layers composing the neural models are simultaneously trained using backpropagation. We argue that the isolated training scheme of ML pipelines is sub-optimal, since it cannot jointly optimize multiple components. To this end, we propose a framework that translates a pre-trained ML pipeline into a neural network and fine-tunes the ML models within the pipeline jointly using backpropagation. Our experiments show that fine-tuning of the translated pipelines is a promising technique able to increase the final accuracy.
Machine Learning at Microsoft with ML .NET
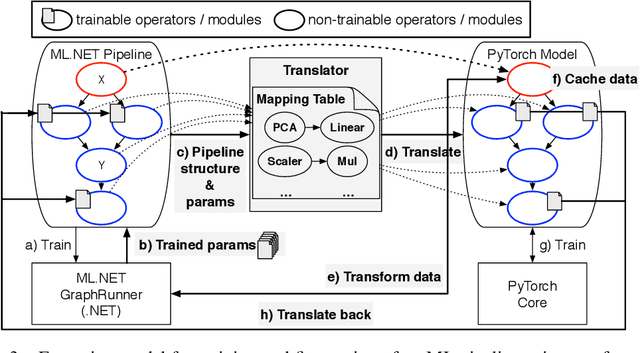
May 15, 2019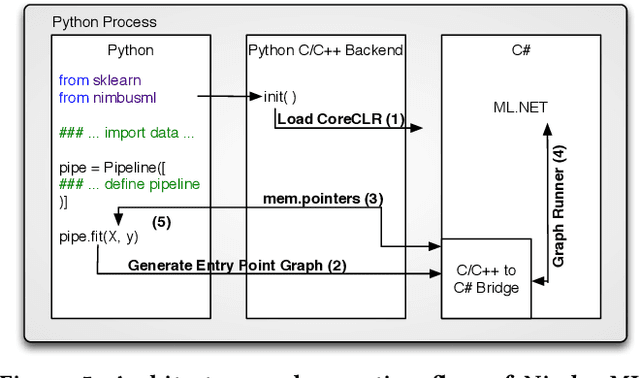
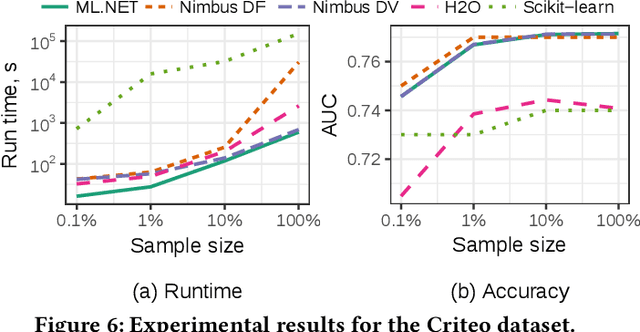
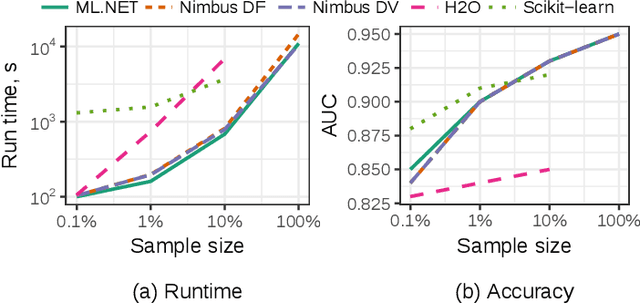
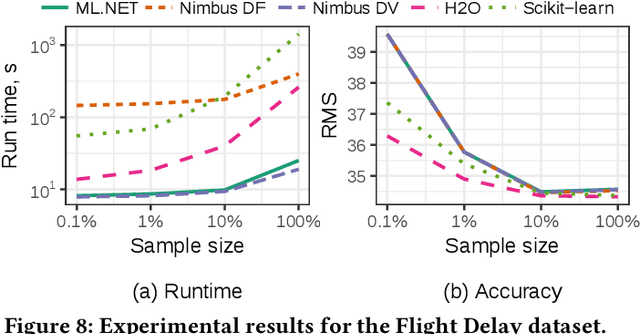
Machine Learning is transitioning from an art and science into a technology available to every developer. In the near future, every application on every platform will incorporate trained models to encode data-based decisions that would be impossible for developers to author. This presents a significant engineering challenge, since currently data science and modeling are largely decoupled from standard software development processes. This separation makes incorporating machine learning capabilities inside applications unnecessarily costly and difficult, and furthermore discourage developers from embracing ML in first place. In this paper we present ML .NET, a framework developed at Microsoft over the last decade in response to the challenge of making it easy to ship machine learning models in large software applications. We present its architecture, and illuminate the application demands that shaped it. Specifically, we introduce DataView, the core data abstraction of ML .NET which allows it to capture full predictive pipelines efficiently and consistently across training and inference lifecycles. We close the paper with a surprisingly favorable performance study of ML .NET compared to more recent entrants, and a discussion of some lessons learned.
PDP: A General Neural Framework for Learning Constraint Satisfaction Solvers
Mar 05, 2019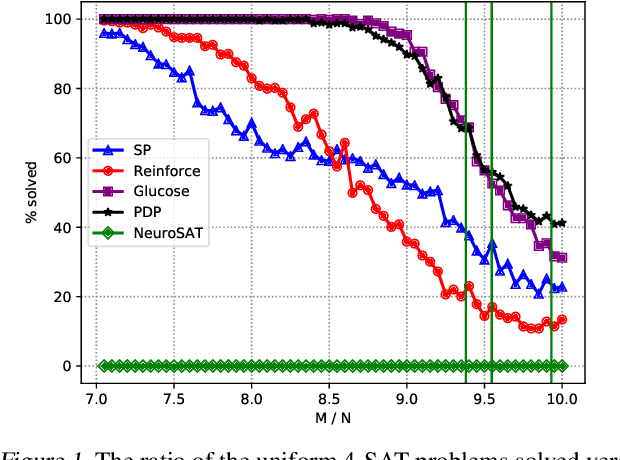
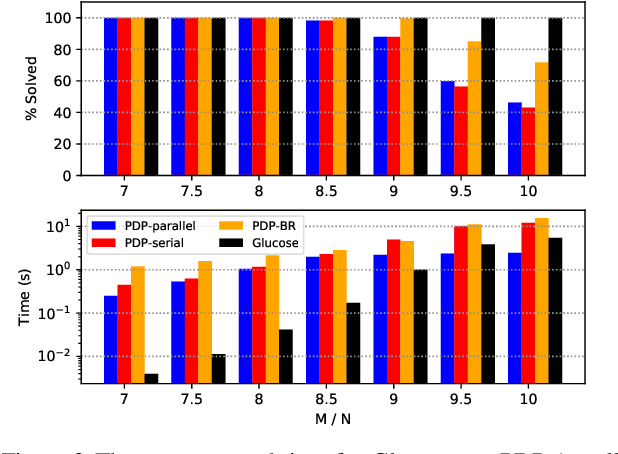
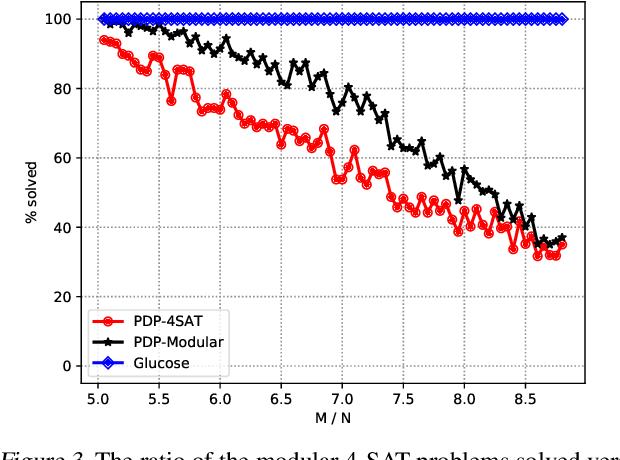
There have been recent efforts for incorporating Graph Neural Network models for learning full-stack solvers for constraint satisfaction problems (CSP) and particularly Boolean satisfiability (SAT). Despite the unique representational power of these neural embedding models, it is not clear how the search strategy in the learned models actually works. On the other hand, by fixing the search strategy (e.g. greedy search), we would effectively deprive the neural models of learning better strategies than those given. In this paper, we propose a generic neural framework for learning CSP solvers that can be described in terms of probabilistic inference and yet learn search strategies beyond greedy search. Our framework is based on the idea of propagation, decimation and prediction (and hence the name PDP) in graphical models, and can be trained directly toward solving CSP in a fully unsupervised manner via energy minimization, as shown in the paper. Our experimental results demonstrate the effectiveness of our framework for SAT solving compared to both neural and the state-of-the-art baselines.
The Bregman Variational Dual-Tree Framework
Sep 26, 2013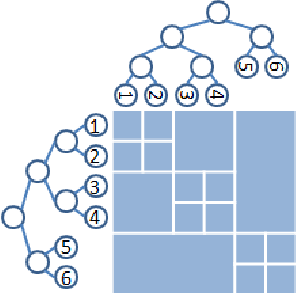


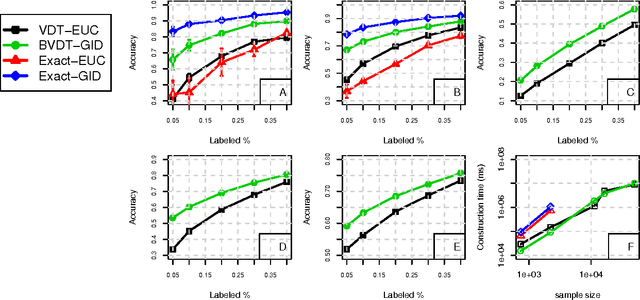
Graph-based methods provide a powerful tool set for many non-parametric frameworks in Machine Learning. In general, the memory and computational complexity of these methods is quadratic in the number of examples in the data which makes them quickly infeasible for moderate to large scale datasets. A significant effort to find more efficient solutions to the problem has been made in the literature. One of the state-of-the-art methods that has been recently introduced is the Variational Dual-Tree (VDT) framework. Despite some of its unique features, VDT is currently restricted only to Euclidean spaces where the Euclidean distance quantifies the similarity. In this paper, we extend the VDT framework beyond the Euclidean distance to more general Bregman divergences that include the Euclidean distance as a special case. By exploiting the properties of the general Bregman divergence, we show how the new framework can maintain all the pivotal features of the VDT framework and yet significantly improve its performance in non-Euclidean domains. We apply the proposed framework to different text categorization problems and demonstrate its benefits over the original VDT.
Variational Dual-Tree Framework for Large-Scale Transition Matrix Approximation
Oct 16, 2012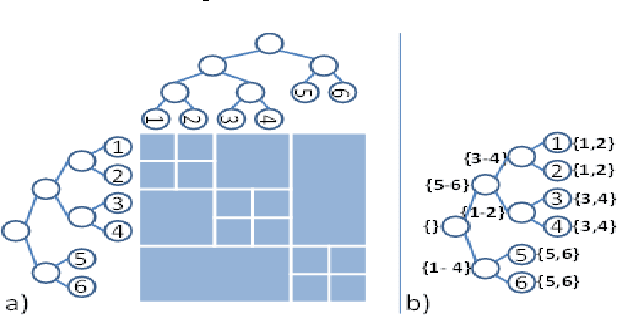

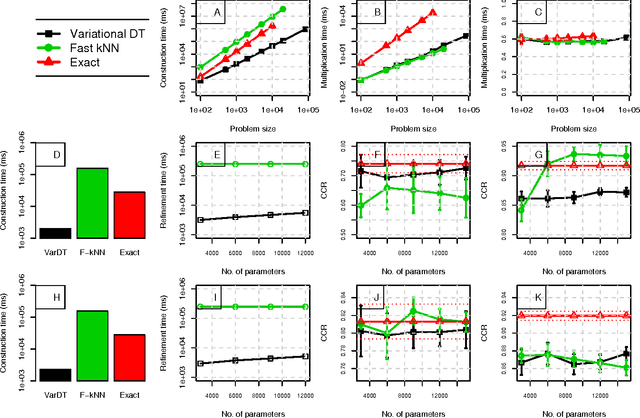

In recent years, non-parametric methods utilizing random walks on graphs have been used to solve a wide range of machine learning problems, but in their simplest form they do not scale well due to the quadratic complexity. In this paper, a new dual-tree based variational approach for approximating the transition matrix and efficiently performing the random walk is proposed. The approach exploits a connection between kernel density estimation, mixture modeling, and random walk on graphs in an optimization of the transition matrix for the data graph that ties together edge transitions probabilities that are similar. Compared to the de facto standard approximation method based on k-nearestneighbors, we demonstrate order of magnitudes speedup without sacrificing accuracy for Label Propagation tasks on benchmark data sets in semi-supervised learning.