 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerra: Imperative-Symbolic Co-Execution of Imperative Deep Learning Programs
Jan 23, 2022

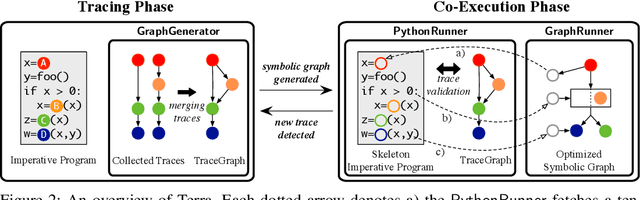
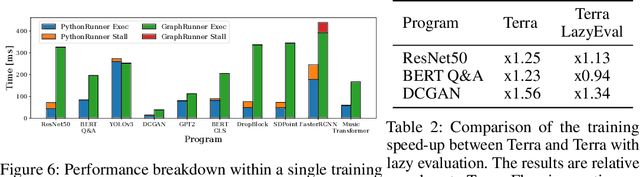
Imperative programming allows users to implement their deep neural networks (DNNs) easily and has become an essential part of recent deep learning (DL) frameworks. Recently, several systems have been proposed to combine the usability of imperative programming with the optimized performance of symbolic graph execution. Such systems convert imperative Python DL programs to optimized symbolic graphs and execute them. However, they cannot fully support the usability of imperative programming. For example, if an imperative DL program contains a Python feature with no corresponding symbolic representation (e.g., third-party library calls or unsupported dynamic control flows) they fail to execute the program. To overcome this limitation, we propose Terra, an imperative-symbolic co-execution system that can handle any imperative DL programs while achieving the optimized performance of symbolic graph execution. To achieve this, Terra builds a symbolic graph by decoupling DL operations from Python features. Then, Terra conducts the imperative execution to support all Python features, while delegating the decoupled operations to the symbolic execution. We evaluated the performance improvement and coverage of Terra with ten imperative DL programs for several DNN architectures. The results show that Terra can speed up the execution of all ten imperative DL programs, whereas AutoGraph, one of the state-of-the-art systems, fails to execute five of them.
Nimble: Lightweight and Parallel GPU Task Scheduling for Deep Learning
Dec 04, 2020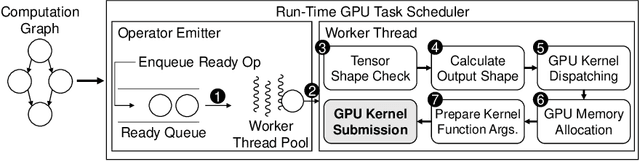
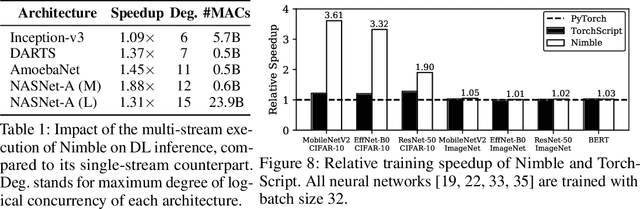
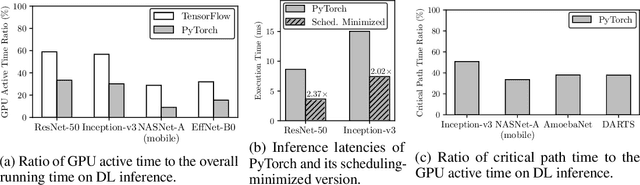
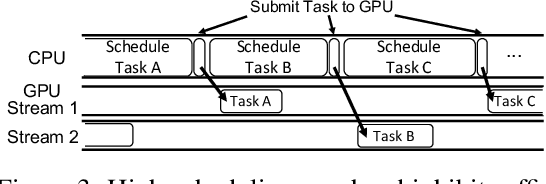
Deep learning (DL) frameworks take advantage of GPUs to improve the speed of DL inference and training. Ideally, DL frameworks should be able to fully utilize the computation power of GPUs such that the running time depends on the amount of computation assigned to GPUs. Yet, we observe that in scheduling GPU tasks, existing DL frameworks suffer from inefficiencies such as large scheduling overhead and unnecessary serial execution. To this end, we propose Nimble, a DL execution engine that runs GPU tasks in parallel with minimal scheduling overhead. Nimble introduces a novel technique called ahead-of-time (AoT) scheduling. Here, the scheduling procedure finishes before executing the GPU kernel, thereby removing most of the scheduling overhead during run time. Furthermore, Nimble automatically parallelizes the execution of GPU tasks by exploiting multiple GPU streams in a single GPU. Evaluation on a variety of neural networks shows that compared to PyTorch, Nimble speeds up inference and training by up to 22.34$\times$ and 3.61$\times$, respectively. Moreover, Nimble outperforms state-of-the-art inference systems, TensorRT and TVM, by up to 2.81$\times$ and 1.70$\times$, respectively.
A Tensor Compiler for Unified Machine Learning Prediction Serving
Oct 19, 2020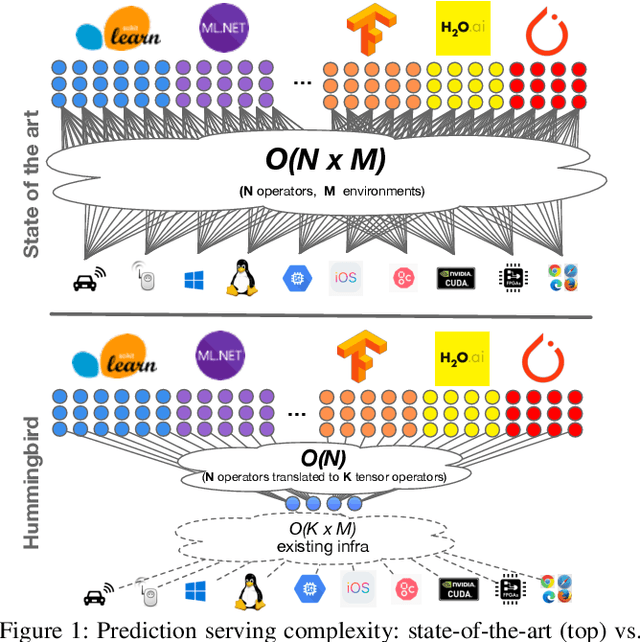

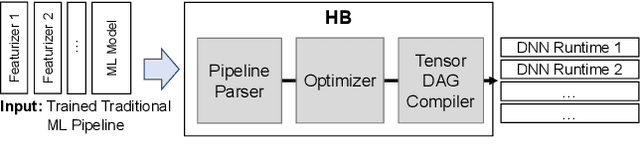

Machine Learning (ML) adoption in the enterprise requires simpler and more efficient software infrastructure---the bespoke solutions typical in large web companies are simply untenable. Model scoring, the process of obtaining predictions from a trained model over new data, is a primary contributor to infrastructure complexity and cost as models are trained once but used many times. In this paper we propose HUMMINGBIRD, a novel approach to model scoring, which compiles featurization operators and traditional ML models (e.g., decision trees) into a small set of tensor operations. This approach inherently reduces infrastructure complexity and directly leverages existing investments in Neural Network compilers and runtimes to generate efficient computations for both CPU and hardware accelerators. Our performance results are intriguing: despite replacing imperative computations (e.g., tree traversals) with tensor computation abstractions, HUMMINGBIRD is competitive and often outperforms hand-crafted kernels on micro-benchmarks on both CPU and GPU, while enabling seamless end-to-end acceleration of ML pipelines. We have released HUMMINGBIRD as open source.
Accelerating Multi-Model Inference by Merging DNNs of Different Weights
Sep 28, 2020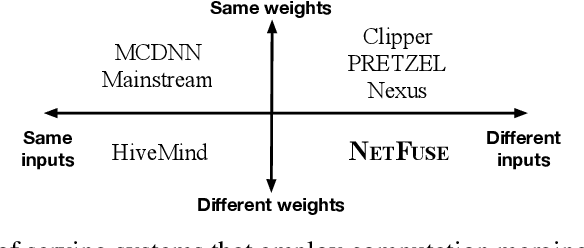
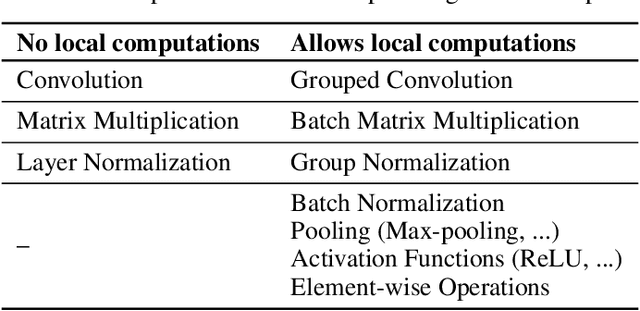
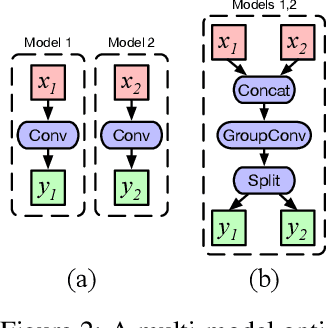

Standardized DNN models that have been proved to perform well on machine learning tasks are widely used and often adopted as-is to solve downstream tasks, forming the transfer learning paradigm. However, when serving multiple instances of such DNN models from a cluster of GPU servers, existing techniques to improve GPU utilization such as batching are inapplicable because models often do not share weights due to fine-tuning. We propose NetFuse, a technique of merging multiple DNN models that share the same architecture but have different weights and different inputs. NetFuse is made possible by replacing operations with more general counterparts that allow a set of weights to be associated with only a certain set of inputs. Experiments on ResNet-50, ResNeXt-50, BERT, and XLNet show that NetFuse can speed up DNN inference time up to 3.6x on a NVIDIA V100 GPU, and up to 3.0x on a TITAN Xp GPU when merging 32 model instances, while only using up a small additional amount of GPU memory.
Stage-based Hyper-parameter Optimization for Deep Learning
Nov 24, 2019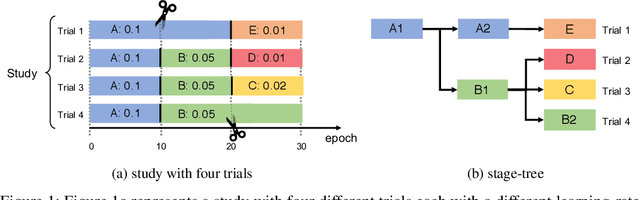

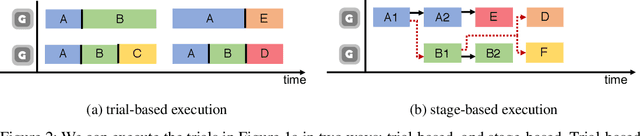
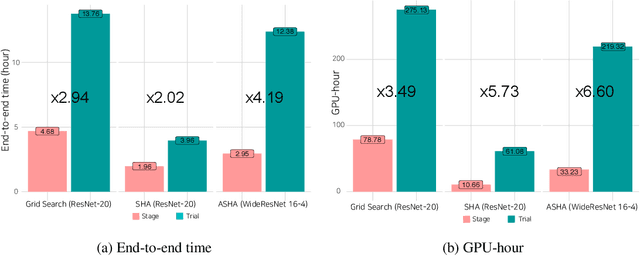
As deep learning techniques advance more than ever, hyper-parameter optimization is the new major workload in deep learning clusters. Although hyper-parameter optimization is crucial in training deep learning models for high model performance, effectively executing such a computation-heavy workload still remains a challenge. We observe that numerous trials issued from existing hyper-parameter optimization algorithms share common hyper-parameter sequence prefixes, which implies that there are redundant computations from training the same hyper-parameter sequence multiple times. We propose a stage-based execution strategy for efficient execution of hyper-parameter optimization algorithms. Our strategy removes redundancy in the training process by splitting the hyper-parameter sequences of trials into homogeneous stages, and generating a tree of stages by merging the common prefixes. Our preliminary experiment results show that applying stage-based execution to hyper-parameter optimization algorithms outperforms the original trial-based method, saving required GPU-hours and end-to-end training time by up to 6.60 times and 4.13 times, respectively.
Making Classical Machine Learning Pipelines Differentiable: A Neural Translation Approach
Jun 10, 2019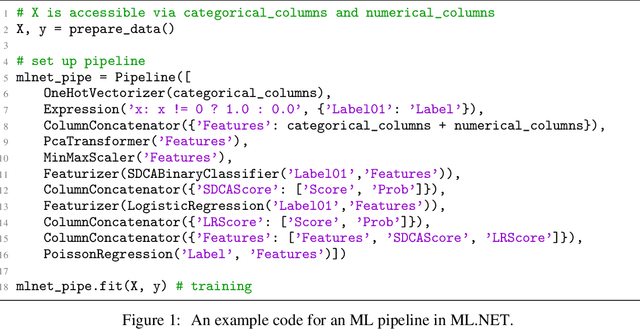

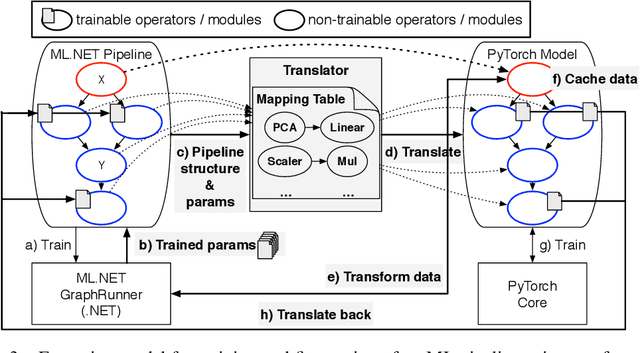
Classical Machine Learning (ML) pipelines often comprise of multiple ML models where models, within a pipeline, are trained in isolation. Conversely, when training neural network models, layers composing the neural models are simultaneously trained using backpropagation. We argue that the isolated training scheme of ML pipelines is sub-optimal, since it cannot jointly optimize multiple components. To this end, we propose a framework that translates a pre-trained ML pipeline into a neural network and fine-tunes the ML models within the pipeline jointly using backpropagation. Our experiments show that fine-tuning of the translated pipelines is a promising technique able to increase the final accuracy.
JANUS: Fast and Flexible Deep Learning via Symbolic Graph Execution of Imperative Programs
Dec 04, 2018
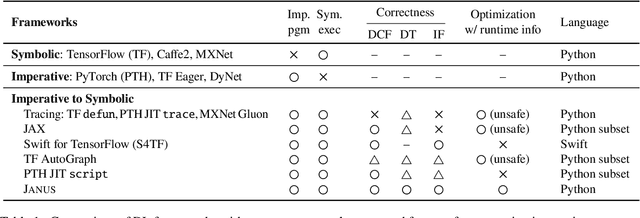
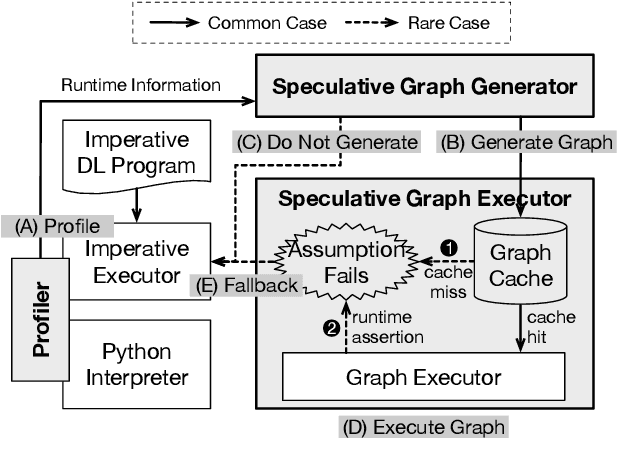
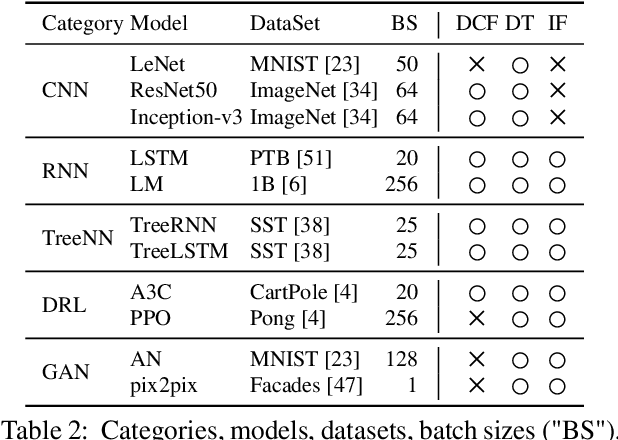
The rapid evolution of deep neural networks is demanding deep learning (DL) frameworks not only to satisfy the traditional requirement of quickly executing large computations, but also to support straightforward programming models for quickly implementing and experimenting with complex network structures. However, existing frameworks fail to excel in both departments simultaneously, leading to diverged efforts for optimizing performance and improving usability. This paper presents JANUS, a system that combines the advantages from both sides by transparently converting an imperative DL program written in Python, the de-facto scripting language for DL, into an efficiently executable symbolic dataflow graph. JANUS can convert various dynamic features of Python, including dynamic control flow, dynamic types, and impure functions, into elements of a symbolic dataflow graph. Experiments demonstrate that JANUS can achieve fast DL training by exploiting the techniques imposed by symbolic graph-based DL frameworks, while maintaining the simple and flexible programmability of imperative DL frameworks at the same time.
* To appear at NSDI 2019
Improving the Expressiveness of Deep Learning Frameworks with Recursion
Sep 04, 2018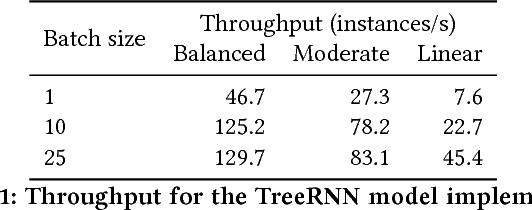

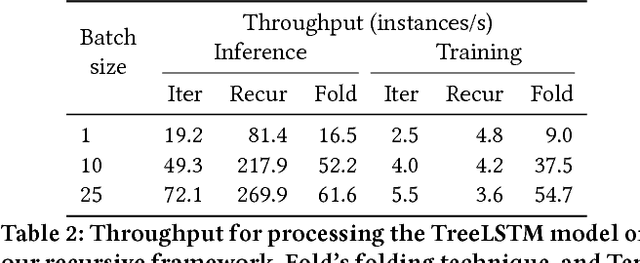
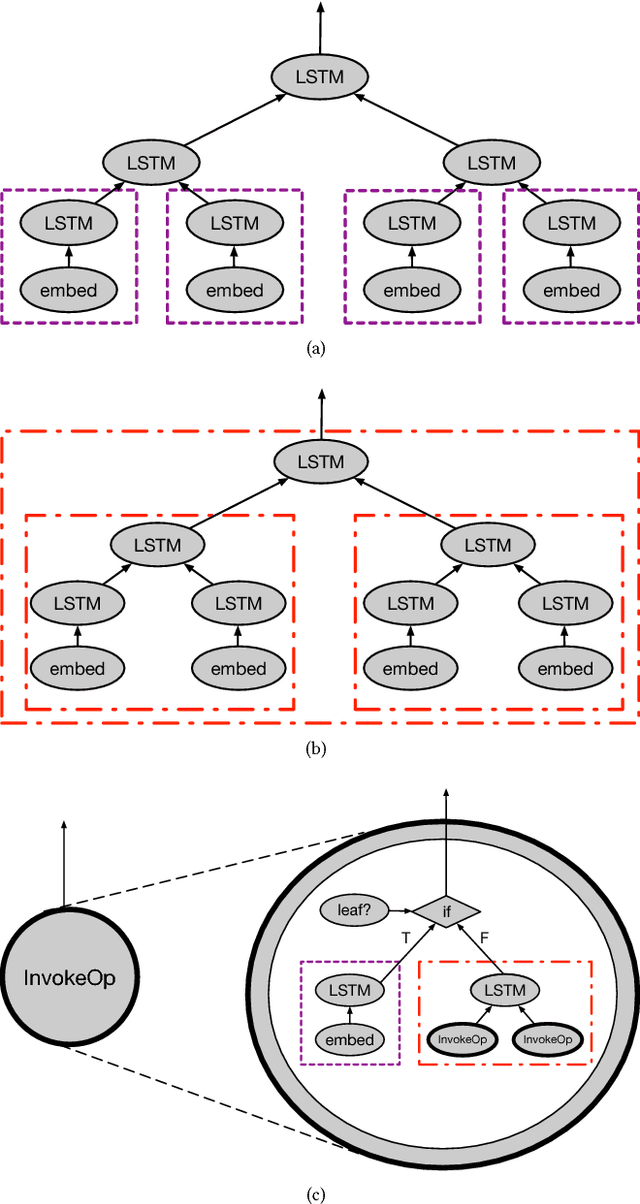
Recursive neural networks have widely been used by researchers to handle applications with recursively or hierarchically structured data. However, embedded control flow deep learning frameworks such as TensorFlow, Theano, Caffe2, and MXNet fail to efficiently represent and execute such neural networks, due to lack of support for recursion. In this paper, we add recursion to the programming model of existing frameworks by complementing their design with recursive execution of dataflow graphs as well as additional APIs for recursive definitions. Unlike iterative implementations, which can only understand the topological index of each node in recursive data structures, our recursive implementation is able to exploit the recursive relationships between nodes for efficient execution based on parallel computation. We present an implementation on TensorFlow and evaluation results with various recursive neural network models, showing that our recursive implementation not only conveys the recursive nature of recursive neural networks better than other implementations, but also uses given resources more effectively to reduce training and inference time.
* Appeared in EuroSys 2018. 13 pages, 11 figures