 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAUGUSTE: Online-Learning dApp for Predictive URLLC Scheduling
Jun 02, 2026Ultra Reliable and Low Latency Communications (URLLC) was one of the main motivations behind 5G, with 3GPP advertising 1-10 ms latency targets for applications such as industrial automation, Vehicle-To-Everything (V2X), tactical edge networking, and unmanned-system control. Years on, real 5G Time Division Duplexing (TDD) networks still show median Uplink (UL) round-trip times in the 50-70 ms range, largely because of the Scheduling Request (SR) procedure that a User Equipment (UE) must complete before transmitting UL data. Existing remedies, primarily Configured Grant (CG) scheduling, only eliminate this overhead for strictly periodic traffic and require cross-layer synchronization, which has limited their adoption. We propose AUGUSTE (Anticipatory Uplink Grants for URLLC via Self-Adapting Temporal Estimation), a learning-based Medium Access Control (MAC) scheduling framework that embeds online Machine Learning (ML) models in the UL scheduler to predict packet arrivals and proactively allocate resources before an SR is issued. An adaptive state machine alternates between a learning phase that collects unbiased arrival statistics and a confident phase that exploits the learned predictions to schedule only when traffic is expected. We evaluate AUGUSTE on a real 5G testbed running OpenAirInterface across three URLLC traffic patterns (request-response, ML edge inference, and periodic autonomous reporting), and show that it operates at the best achievable point on the latency-overhead trade-off: it matches always-on scheduling's median Round Trip Time (RTT) (around 10 ms, halving the 20 ms SR-based baseline) at roughly one-tenth its resource cost (7-10 percent overhead).
Puzzle: Scheduling Multiple Deep Learning Models on Mobile Device with Heterogeneous Processors
Aug 25, 2025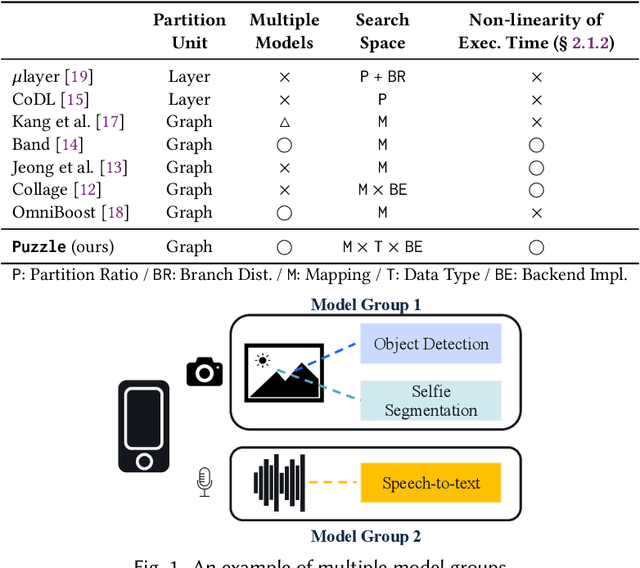
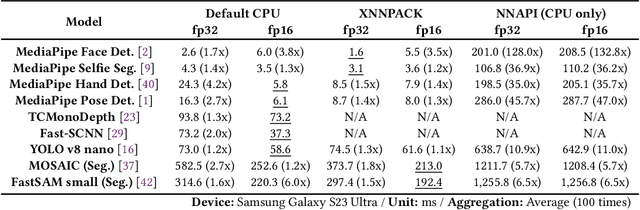

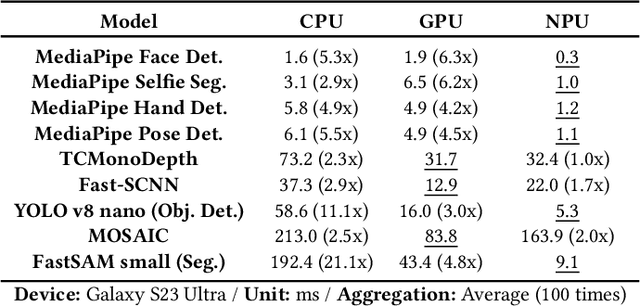
As deep learning models are increasingly deployed on mobile devices, modern mobile devices incorporate deep learning-specific accelerators to handle the growing computational demands, thus increasing their hardware heterogeneity. However, existing works on scheduling deep learning workloads across these processors have significant limitations: most studies focus on single-model scenarios rather than realistic multi-model scenarios, overlook performance variations from different hardware/software configurations, and struggle with accurate execution time estimation. To address these challenges, we propose a novel genetic algorithm-based methodology for scheduling multiple deep learning networks on heterogeneous processors by partitioning the networks into multiple subgraphs. Our approach incorporates three different types of chromosomes for partition/mapping/priority exploration, and leverages device-in-the-loop profiling and evaluation for accurate execution time estimation. Based on this methodology, our system, Puzzle, demonstrates superior performance in extensive evaluations with randomly generated scenarios involving nine state-of-the-art networks. The results demonstrate Puzzle can support 3.7 and 2.2 times higher request frequency on average compared to the two heuristic baselines, NPU Only and Best Mapping, respectively, while satisfying the equivalent level of real-time requirements.
AgentRAN: An Agentic AI Architecture for Autonomous Control of Open 6G Networks
Aug 25, 2025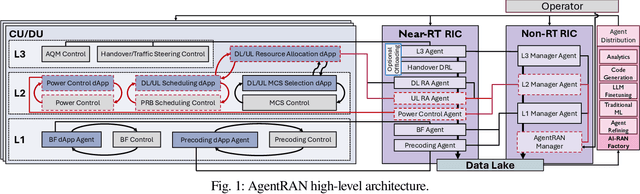
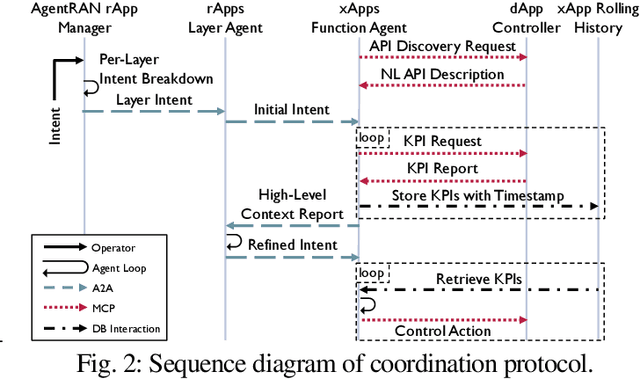

The Open RAN movement has catalyzed a transformation toward programmable, interoperable cellular infrastructures. Yet, today's deployments still rely heavily on static control and manual operations. To move beyond this limitation, we introduce AgenRAN, an AI-native, Open RAN-aligned agentic framework that generates and orchestrates a fabric of distributed AI agents based on Natural Language (NL) intents. Unlike traditional approaches that require explicit programming, AgentRAN's LLM-powered agents interpret natural language intents, negotiate strategies through structured conversations, and orchestrate control loops across the network. AgentRAN instantiates a self-organizing hierarchy of agents that decompose complex intents across time scales (from sub-millisecond to minutes), spatial domains (cell to network-wide), and protocol layers (PHY/MAC to RRC). A central innovation is the AI-RAN Factory, an automated synthesis pipeline that observes agent interactions and continuously generates new agents embedding improved control algorithms, effectively transforming the network from a static collection of functions into an adaptive system capable of evolving its own intelligence. We demonstrate AgentRAN through live experiments on 5G testbeds where competing user demands are dynamically balanced through cascading intents. By replacing rigid APIs with NL coordination, AgentRAN fundamentally redefines how future 6G networks autonomously interpret, adapt, and optimize their behavior to meet operator goals.
Accelerating Multi-Model Inference by Merging DNNs of Different Weights
Sep 28, 2020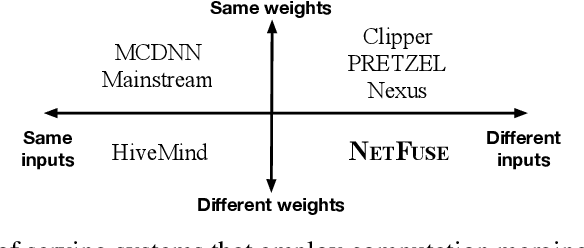
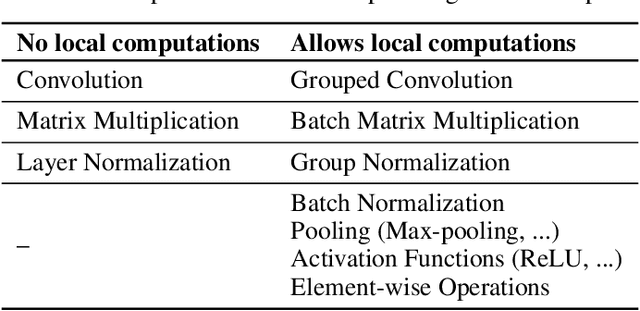
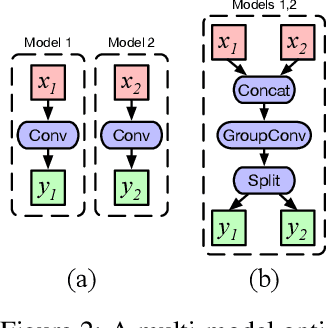

Standardized DNN models that have been proved to perform well on machine learning tasks are widely used and often adopted as-is to solve downstream tasks, forming the transfer learning paradigm. However, when serving multiple instances of such DNN models from a cluster of GPU servers, existing techniques to improve GPU utilization such as batching are inapplicable because models often do not share weights due to fine-tuning. We propose NetFuse, a technique of merging multiple DNN models that share the same architecture but have different weights and different inputs. NetFuse is made possible by replacing operations with more general counterparts that allow a set of weights to be associated with only a certain set of inputs. Experiments on ResNet-50, ResNeXt-50, BERT, and XLNet show that NetFuse can speed up DNN inference time up to 3.6x on a NVIDIA V100 GPU, and up to 3.0x on a TITAN Xp GPU when merging 32 model instances, while only using up a small additional amount of GPU memory.
PRETZEL: Opening the Black Box of Machine Learning Prediction Serving Systems
Oct 14, 2018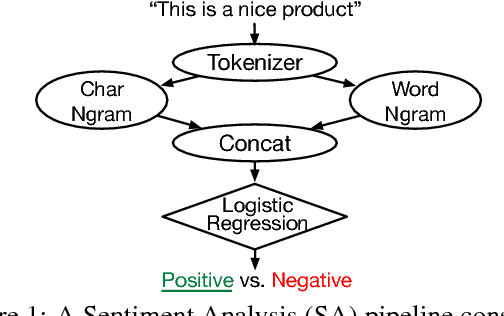

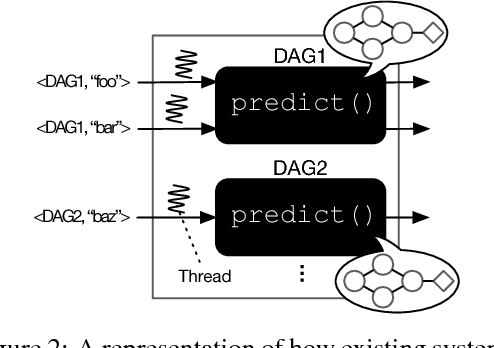
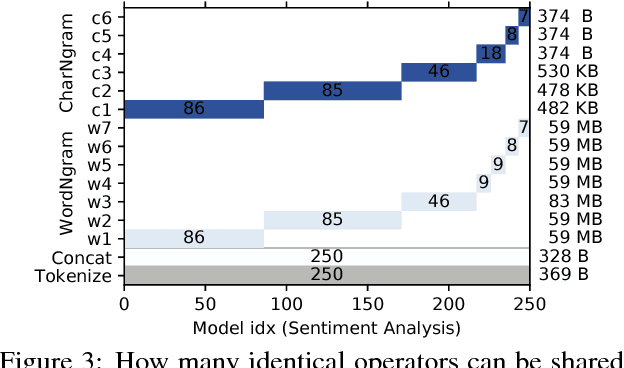
Machine Learning models are often composed of pipelines of transformations. While this design allows to efficiently execute single model components at training time, prediction serving has different requirements such as low latency, high throughput and graceful performance degradation under heavy load. Current prediction serving systems consider models as black boxes, whereby prediction-time-specific optimizations are ignored in favor of ease of deployment. In this paper, we present PRETZEL, a prediction serving system introducing a novel white box architecture enabling both end-to-end and multi-model optimizations. Using production-like model pipelines, our experiments show that PRETZEL is able to introduce performance improvements over different dimensions; compared to state-of-the-art approaches PRETZEL is on average able to reduce 99th percentile latency by 5.5x while reducing memory footprint by 25x, and increasing throughput by 4.7x.