 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlex-Judge: Think Once, Judge Anywhere
May 24, 2025Human-generated reward signals are critical for aligning generative models with human preferences, guiding both training and inference-time evaluations. While large language models (LLMs) employed as proxy evaluators, i.e., LLM-as-a-Judge, significantly reduce the costs associated with manual annotations, they typically require extensive modality-specific training data and fail to generalize well across diverse multimodal tasks. In this paper, we propose Flex-Judge, a reasoning-guided multimodal judge model that leverages minimal textual reasoning data to robustly generalize across multiple modalities and evaluation formats. Our core intuition is that structured textual reasoning explanations inherently encode generalizable decision-making patterns, enabling an effective transfer to multimodal judgments, e.g., with images or videos. Empirical results demonstrate that Flex-Judge, despite being trained on significantly fewer text data, achieves competitive or superior performance compared to state-of-the-art commercial APIs and extensively trained multimodal evaluators. Notably, Flex-Judge presents broad impact in modalities like molecule, where comprehensive evaluation benchmarks are scarce, underscoring its practical value in resource-constrained domains. Our framework highlights reasoning-based text supervision as a powerful, cost-effective alternative to traditional annotation-intensive approaches, substantially advancing scalable multimodal model-as-a-judge.
MAVFlow: Preserving Paralinguistic Elements with Conditional Flow Matching for Zero-Shot AV2AV Multilingual Translation
Mar 14, 2025



Despite recent advances in text-to-speech (TTS) models, audio-visual to audio-visual (AV2AV) translation still faces a critical challenge: maintaining speaker consistency between the original and translated vocal and facial features. To address this issue, we propose a conditional flow matching (CFM) zero-shot audio-visual renderer that utilizes strong dual guidance from both audio and visual modalities. By leveraging multi-modal guidance with CFM, our model robustly preserves speaker-specific characteristics and significantly enhances zero-shot AV2AV translation abilities. For the audio modality, we enhance the CFM process by integrating robust speaker embeddings with x-vectors, which serve to bolster speaker consistency. Additionally, we convey emotional nuances to the face rendering module. The guidance provided by both audio and visual cues remains independent of semantic or linguistic content, allowing our renderer to effectively handle zero-shot translation tasks for monolingual speakers in different languages. We empirically demonstrate that the inclusion of high-quality mel-spectrograms conditioned on facial information not only enhances the quality of the synthesized speech but also positively influences facial generation, leading to overall performance improvements.
FedDr+: Stabilizing Dot-regression with Global Feature Distillation for Federated Learning
Jun 04, 2024Federated Learning (FL) has emerged as a pivotal framework for the development of effective global models (global FL) or personalized models (personalized FL) across clients with heterogeneous, non-iid data distribution. A key challenge in FL is client drift, where data heterogeneity impedes the aggregation of scattered knowledge. Recent studies have tackled the client drift issue by identifying significant divergence in the last classifier layer. To mitigate this divergence, strategies such as freezing the classifier weights and aligning the feature extractor accordingly have proven effective. Although the local alignment between classifier and feature extractor has been studied as a crucial factor in FL, we observe that it may lead the model to overemphasize the observed classes within each client. Thus, our objectives are twofold: (1) enhancing local alignment while (2) preserving the representation of unseen class samples. This approach aims to effectively integrate knowledge from individual clients, thereby improving performance for both global and personalized FL. To achieve this, we introduce a novel algorithm named FedDr+, which empowers local model alignment using dot-regression loss. FedDr+ freezes the classifier as a simplex ETF to align the features and improves aggregated global models by employing a feature distillation mechanism to retain information about unseen/missing classes. Consequently, we provide empirical evidence demonstrating that our algorithm surpasses existing methods that use a frozen classifier to boost alignment across the diverse distribution.
Deep Collective Knowledge Distillation
Apr 18, 2023



Many existing studies on knowledge distillation have focused on methods in which a student model mimics a teacher model well. Simply imitating the teacher's knowledge, however, is not sufficient for the student to surpass that of the teacher. We explore a method to harness the knowledge of other students to complement the knowledge of the teacher. We propose deep collective knowledge distillation for model compression, called DCKD, which is a method for training student models with rich information to acquire knowledge from not only their teacher model but also other student models. The knowledge collected from several student models consists of a wealth of information about the correlation between classes. Our DCKD considers how to increase the correlation knowledge of classes during training. Our novel method enables us to create better performing student models for collecting knowledge. This simple yet powerful method achieves state-of-the-art performances in many experiments. For example, for ImageNet, ResNet18 trained with DCKD achieves 72.27\%, which outperforms the pretrained ResNet18 by 2.52\%. For CIFAR-100, the student model of ShuffleNetV1 with DCKD achieves 6.55\% higher top-1 accuracy than the pretrained ShuffleNetV1.
Stage-based Hyper-parameter Optimization for Deep Learning
Nov 24, 2019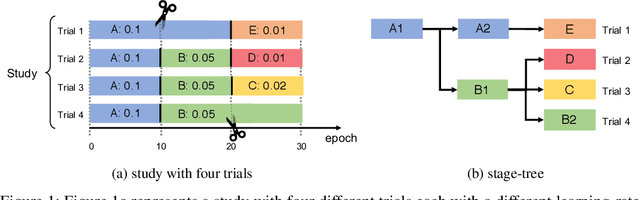

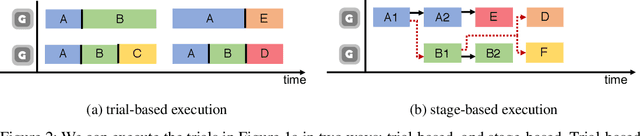
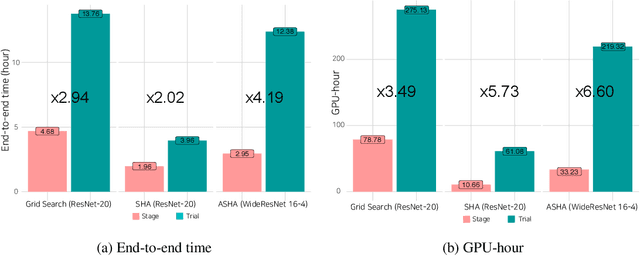
As deep learning techniques advance more than ever, hyper-parameter optimization is the new major workload in deep learning clusters. Although hyper-parameter optimization is crucial in training deep learning models for high model performance, effectively executing such a computation-heavy workload still remains a challenge. We observe that numerous trials issued from existing hyper-parameter optimization algorithms share common hyper-parameter sequence prefixes, which implies that there are redundant computations from training the same hyper-parameter sequence multiple times. We propose a stage-based execution strategy for efficient execution of hyper-parameter optimization algorithms. Our strategy removes redundancy in the training process by splitting the hyper-parameter sequences of trials into homogeneous stages, and generating a tree of stages by merging the common prefixes. Our preliminary experiment results show that applying stage-based execution to hyper-parameter optimization algorithms outperforms the original trial-based method, saving required GPU-hours and end-to-end training time by up to 6.60 times and 4.13 times, respectively.
JANUS: Fast and Flexible Deep Learning via Symbolic Graph Execution of Imperative Programs
Dec 04, 2018
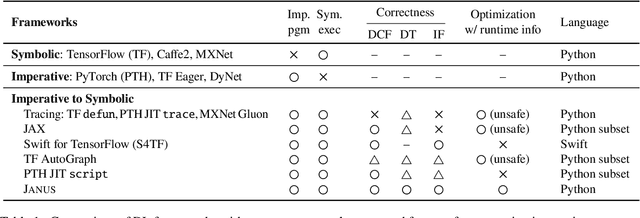
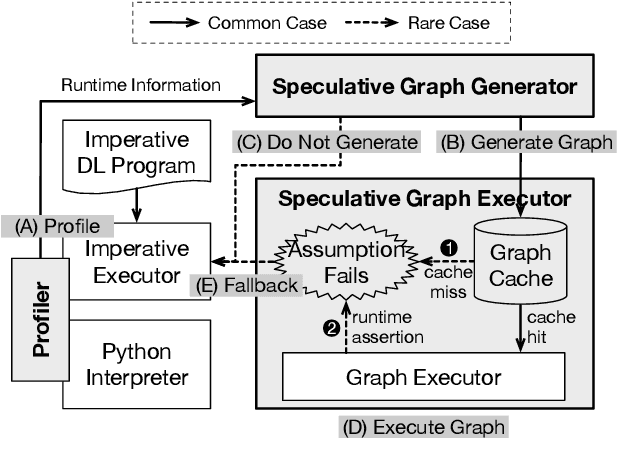
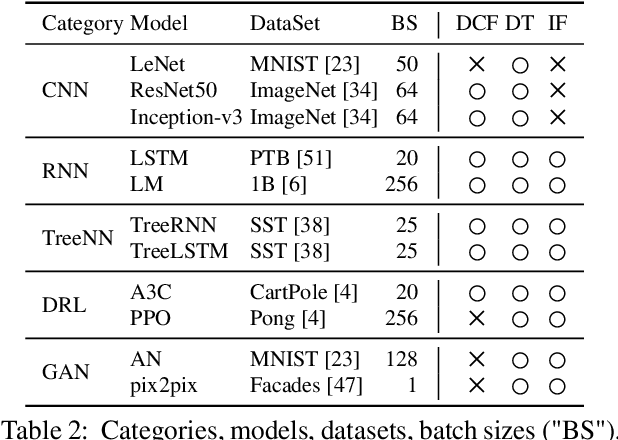
The rapid evolution of deep neural networks is demanding deep learning (DL) frameworks not only to satisfy the traditional requirement of quickly executing large computations, but also to support straightforward programming models for quickly implementing and experimenting with complex network structures. However, existing frameworks fail to excel in both departments simultaneously, leading to diverged efforts for optimizing performance and improving usability. This paper presents JANUS, a system that combines the advantages from both sides by transparently converting an imperative DL program written in Python, the de-facto scripting language for DL, into an efficiently executable symbolic dataflow graph. JANUS can convert various dynamic features of Python, including dynamic control flow, dynamic types, and impure functions, into elements of a symbolic dataflow graph. Experiments demonstrate that JANUS can achieve fast DL training by exploiting the techniques imposed by symbolic graph-based DL frameworks, while maintaining the simple and flexible programmability of imperative DL frameworks at the same time.
* To appear at NSDI 2019