 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Collective Knowledge Distillation
Apr 18, 2023



Many existing studies on knowledge distillation have focused on methods in which a student model mimics a teacher model well. Simply imitating the teacher's knowledge, however, is not sufficient for the student to surpass that of the teacher. We explore a method to harness the knowledge of other students to complement the knowledge of the teacher. We propose deep collective knowledge distillation for model compression, called DCKD, which is a method for training student models with rich information to acquire knowledge from not only their teacher model but also other student models. The knowledge collected from several student models consists of a wealth of information about the correlation between classes. Our DCKD considers how to increase the correlation knowledge of classes during training. Our novel method enables us to create better performing student models for collecting knowledge. This simple yet powerful method achieves state-of-the-art performances in many experiments. For example, for ImageNet, ResNet18 trained with DCKD achieves 72.27\%, which outperforms the pretrained ResNet18 by 2.52\%. For CIFAR-100, the student model of ShuffleNetV1 with DCKD achieves 6.55\% higher top-1 accuracy than the pretrained ShuffleNetV1.
DUET: Detection Utilizing Enhancement for Text in Scanned or Captured Documents
Jun 10, 2021

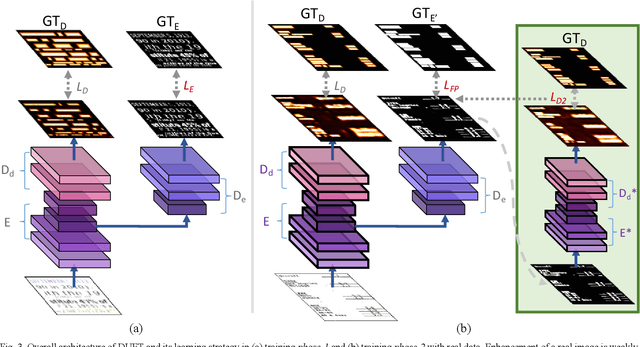

We present a novel deep neural model for text detection in document images. For robust text detection in noisy scanned documents, the advantages of multi-task learning are adopted by adding an auxiliary task of text enhancement. Namely, our proposed model is designed to perform noise reduction and text region enhancement as well as text detection. Moreover, we enrich the training data for the model with synthesized document images that are fully labeled for text detection and enhancement, thus overcome the insufficiency of labeled document image data. For the effective exploitation of the synthetic and real data, the training process is separated in two phases. The first phase is training only synthetic data in a fully-supervised manner. Then real data with only detection labels are added in the second phase. The enhancement task for the real data is weakly-supervised with information from their detection labels. Our methods are demonstrated in a real document dataset with performances exceeding those of other text detection methods. Moreover, ablations are conducted and the results confirm the effectiveness of the synthetic data, auxiliary task, and weak-supervision. Whereas the existing text detection studies mostly focus on the text in scenes, our proposed method is optimized to the applications for the text in scanned documents.