 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDUET: Detection Utilizing Enhancement for Text in Scanned or Captured Documents
Paper and Code
Jun 10, 2021

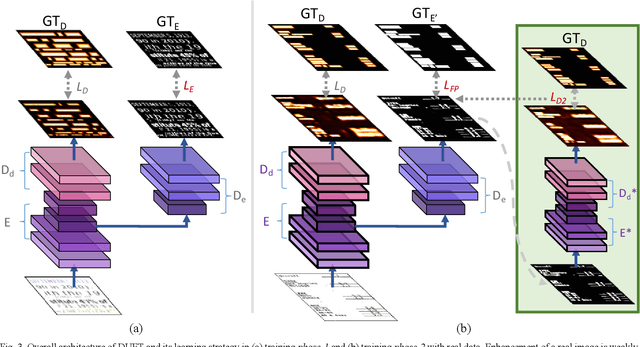

We present a novel deep neural model for text detection in document images. For robust text detection in noisy scanned documents, the advantages of multi-task learning are adopted by adding an auxiliary task of text enhancement. Namely, our proposed model is designed to perform noise reduction and text region enhancement as well as text detection. Moreover, we enrich the training data for the model with synthesized document images that are fully labeled for text detection and enhancement, thus overcome the insufficiency of labeled document image data. For the effective exploitation of the synthetic and real data, the training process is separated in two phases. The first phase is training only synthetic data in a fully-supervised manner. Then real data with only detection labels are added in the second phase. The enhancement task for the real data is weakly-supervised with information from their detection labels. Our methods are demonstrated in a real document dataset with performances exceeding those of other text detection methods. Moreover, ablations are conducted and the results confirm the effectiveness of the synthetic data, auxiliary task, and weak-supervision. Whereas the existing text detection studies mostly focus on the text in scenes, our proposed method is optimized to the applications for the text in scanned documents.