 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Look Only Once: Towards Multimodal Interactive Reasoning with Selective Visual Revisitation
May 24, 2025We present v1, a lightweight extension to Multimodal Large Language Models (MLLMs) that enables selective visual revisitation during inference. While current MLLMs typically consume visual input only once and reason purely over internal memory, v1 introduces a simple point-and-copy mechanism that allows the model to dynamically retrieve relevant image regions throughout the reasoning process. This mechanism augments existing architectures with minimal modifications, enabling contextual access to visual tokens based on the model's evolving hypotheses. To train this capability, we construct v1g, a dataset of 300K multimodal reasoning traces with interleaved visual grounding annotations. Experiments on three multimodal mathematical reasoning benchmarks -- MathVista, MathVision, and MathVerse -- demonstrate that v1 consistently improves performance over comparable baselines, particularly on tasks requiring fine-grained visual reference and multi-step reasoning. Our results suggest that dynamic visual access is a promising direction for enhancing grounded multimodal reasoning. Code, models, and data will be released to support future research.
DUET: Detection Utilizing Enhancement for Text in Scanned or Captured Documents
Jun 10, 2021

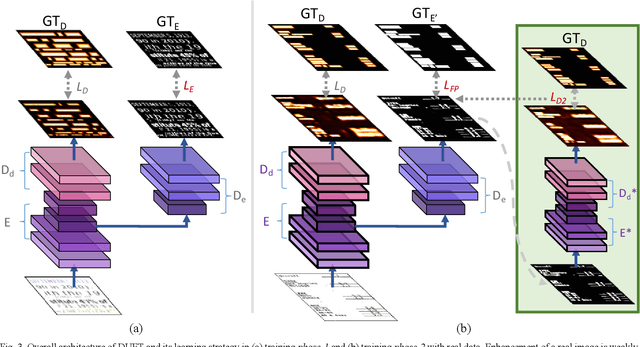

We present a novel deep neural model for text detection in document images. For robust text detection in noisy scanned documents, the advantages of multi-task learning are adopted by adding an auxiliary task of text enhancement. Namely, our proposed model is designed to perform noise reduction and text region enhancement as well as text detection. Moreover, we enrich the training data for the model with synthesized document images that are fully labeled for text detection and enhancement, thus overcome the insufficiency of labeled document image data. For the effective exploitation of the synthetic and real data, the training process is separated in two phases. The first phase is training only synthetic data in a fully-supervised manner. Then real data with only detection labels are added in the second phase. The enhancement task for the real data is weakly-supervised with information from their detection labels. Our methods are demonstrated in a real document dataset with performances exceeding those of other text detection methods. Moreover, ablations are conducted and the results confirm the effectiveness of the synthetic data, auxiliary task, and weak-supervision. Whereas the existing text detection studies mostly focus on the text in scenes, our proposed method is optimized to the applications for the text in scanned documents.
PLAM: a Posit Logarithm-Approximate Multiplier for Power Efficient Posit-based DNNs
Feb 18, 2021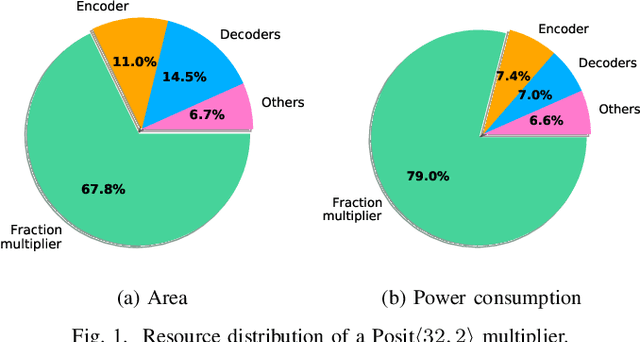

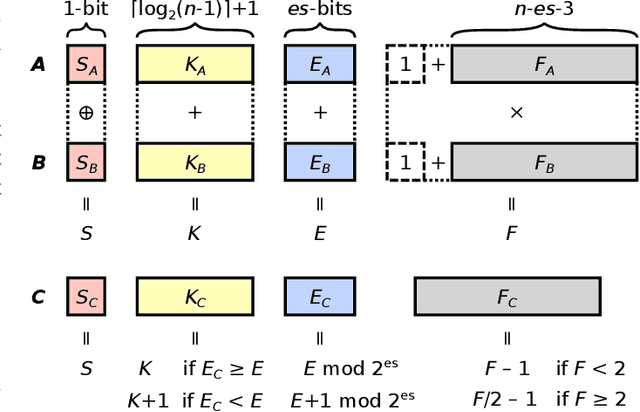
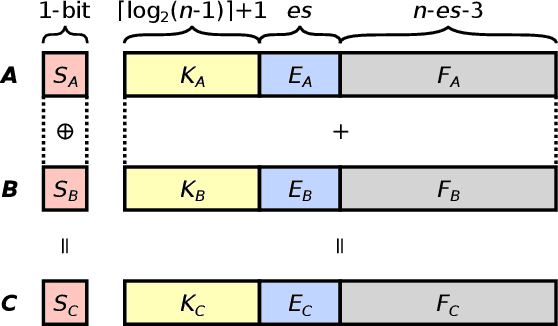
The Posit Number System was introduced in 2017 as a replacement for floating-point numbers. Since then, the community has explored its application in Neural Network related tasks and produced some unit designs which are still far from being competitive with their floating-point counterparts. This paper proposes a Posit Logarithm-Approximate Multiplication (PLAM) scheme to significantly reduce the complexity of posit multipliers, the most power-hungry units within Deep Neural Network architectures. When comparing with state-of-the-art posit multipliers, experiments show that the proposed technique reduces the area, power, and delay of hardware multipliers up to 72.86%, 81.79%, and 17.01%, respectively, without accuracy degradation.
Effects of Approximate Multiplication on Convolutional Neural Networks
Jul 20, 2020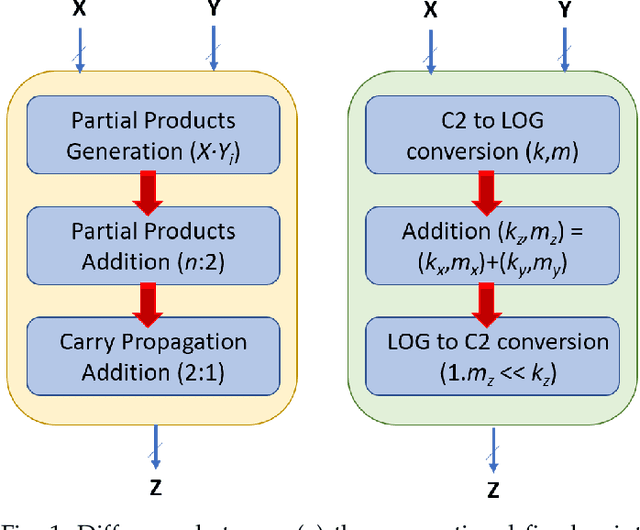
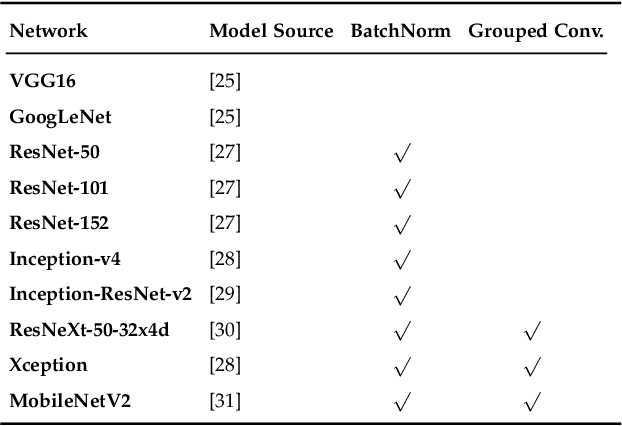
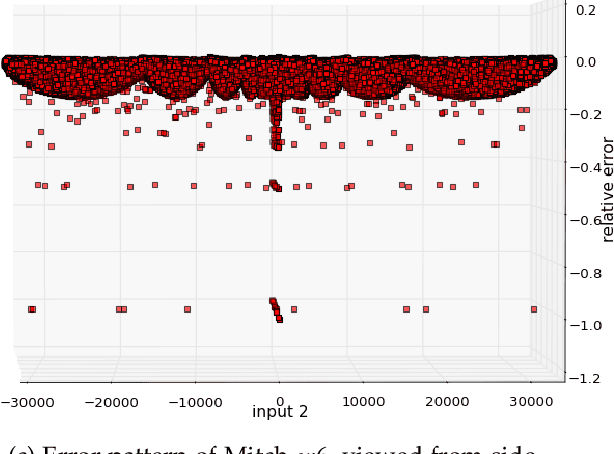

This paper analyzes the effects of approximate multiplication when performing inferences on deep convolutional neural networks (CNNs). The approximate multiplication can reduce the cost of underlying circuits so that CNN inferences can be performed more efficiently in hardware accelerators. The study identifies the critical factors in the convolution, fully-connected, and batch normalization layers that allow more accurate CNN predictions despite the errors from approximate multiplication. The same factors also provide an arithmetic explanation of why bfloat16 multiplication performs well on CNNs. The experiments are performed with recognized network architectures to show that the approximate multipliers can produce predictions that are nearly as accurate as the FP32 references, without additional training. For example, the ResNet and Inception-v4 models with Mitch-$w$6 multiplication produces Top-5 errors that are within 0.2% compared to the FP32 references. A brief cost comparison of Mitch-$w$6 against bfloat16 is presented, where a MAC operation saves up to 80% of energy compared to the bfloat16 arithmetic. The most far-reaching contribution of this paper is the analytical justification that multiplications can be approximated while additions need to be exact in CNN MAC operations.