 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Geometry Is Not Enough for Vision Representations
Feb 03, 2026A common assumption in representation learning is that globally well-distributed embeddings support robust and generalizable representations. This focus has shaped both training objectives and evaluation protocols, implicitly treating global geometry as a proxy for representational competence. While global geometry effectively encodes which elements are present, it is often insensitive to how they are composed. We investigate this limitation by testing the ability of geometric metrics to predict compositional binding across 21 vision encoders. We find that standard geometry-based statistics exhibit near-zero correlation with compositional binding. In contrast, functional sensitivity, as measured by the input-output Jacobian, reliably tracks this capability. We further provide an analytic account showing that this disparity arises from objective design, as existing losses explicitly constrain embedding geometry but leave the local input-output mapping unconstrained. These results suggest that global embedding geometry captures only a partial view of representational competence and establish functional sensitivity as a critical complementary axis for modeling composite structure.
What MLLMs Learn about When they Learn about Multimodal Reasoning: Perception, Reasoning, or their Integration?
Oct 02, 2025Multimodal reasoning models have recently shown promise on challenging domains such as olympiad-level geometry, yet their evaluation remains dominated by aggregate accuracy, a single score that obscures where and how models are improving. We introduce MathLens, a benchmark designed to disentangle the subskills of multimodal reasoning while preserving the complexity of textbook-style geometry problems. The benchmark separates performance into three components: Perception: extracting information from raw inputs, Reasoning: operating on available information, and Integration: selecting relevant perceptual evidence and applying it within reasoning. To support each test, we provide annotations: visual diagrams, textual descriptions to evaluate reasoning in isolation, controlled questions that require both modalities, and probes for fine-grained perceptual skills, all derived from symbolic specifications of the problems to ensure consistency and robustness. Our analysis reveals that different training approaches have uneven effects: First, reinforcement learning chiefly strengthens perception, especially when supported by textual supervision, while textual SFT indirectly improves perception through reflective reasoning. Second, reasoning improves only in tandem with perception. Third, integration remains the weakest capacity, with residual errors concentrated there once other skills advance. Finally, robustness diverges: RL improves consistency under diagram variation, whereas multimodal SFT reduces it through overfitting. We will release all data and experimental logs.
Are Any-to-Any Models More Consistent Across Modality Transfers Than Specialists?
May 30, 2025Any-to-any generative models aim to enable seamless interpretation and generation across multiple modalities within a unified framework, yet their ability to preserve relationships across modalities remains uncertain. Do unified models truly achieve cross-modal coherence, or is this coherence merely perceived? To explore this, we introduce ACON, a dataset of 1,000 images (500 newly contributed) paired with captions, editing instructions, and Q&A pairs to evaluate cross-modal transfers rigorously. Using three consistency criteria-cyclic consistency, forward equivariance, and conjugated equivariance-our experiments reveal that any-to-any models do not consistently demonstrate greater cross-modal consistency than specialized models in pointwise evaluations such as cyclic consistency. However, equivariance evaluations uncover weak but observable consistency through structured analyses of the intermediate latent space enabled by multiple editing operations. We release our code and data at https://github.com/JiwanChung/ACON.
Don't Look Only Once: Towards Multimodal Interactive Reasoning with Selective Visual Revisitation
May 24, 2025We present v1, a lightweight extension to Multimodal Large Language Models (MLLMs) that enables selective visual revisitation during inference. While current MLLMs typically consume visual input only once and reason purely over internal memory, v1 introduces a simple point-and-copy mechanism that allows the model to dynamically retrieve relevant image regions throughout the reasoning process. This mechanism augments existing architectures with minimal modifications, enabling contextual access to visual tokens based on the model's evolving hypotheses. To train this capability, we construct v1g, a dataset of 300K multimodal reasoning traces with interleaved visual grounding annotations. Experiments on three multimodal mathematical reasoning benchmarks -- MathVista, MathVision, and MathVerse -- demonstrate that v1 consistently improves performance over comparable baselines, particularly on tasks requiring fine-grained visual reference and multi-step reasoning. Our results suggest that dynamic visual access is a promising direction for enhancing grounded multimodal reasoning. Code, models, and data will be released to support future research.
Explain with Visual Keypoints Like a Real Mentor! A Benchmark for Multimodal Solution Explanation
Apr 07, 2025



With the rapid advancement of mathematical reasoning capabilities in Large Language Models (LLMs), AI systems are increasingly being adopted in educational settings to support students' comprehension of problem-solving processes. However, a critical component remains underexplored in current LLM-generated explanations: visual explanation. In real-world instructional contexts, human tutors routinely employ visual aids - such as diagrams, markings, and highlights - to enhance conceptual clarity. To bridge this gap, we introduce a novel task of visual solution explanation, which requires generating explanations that incorporate newly introduced visual elements essential for understanding (e.g., auxiliary lines, annotations, or geometric constructions). To evaluate model performance on this task, we propose MathExplain, a multimodal benchmark consisting of 997 math problems annotated with visual keypoints and corresponding explanatory text that references those elements. Our empirical results show that while some closed-source models demonstrate promising capabilities on visual solution-explaining, current open-source general-purpose models perform inconsistently, particularly in identifying relevant visual components and producing coherent keypoint-based explanations. We expect that visual solution-explaining and the MathExplain dataset will catalyze further research on multimodal LLMs in education and advance their deployment as effective, explanation-oriented AI tutors. Code and data will be released publicly.
VisEscape: A Benchmark for Evaluating Exploration-driven Decision-making in Virtual Escape Rooms
Mar 18, 2025Escape rooms present a unique cognitive challenge that demands exploration-driven planning: players should actively search their environment, continuously update their knowledge based on new discoveries, and connect disparate clues to determine which elements are relevant to their objectives. Motivated by this, we introduce VisEscape, a benchmark of 20 virtual escape rooms specifically designed to evaluate AI models under these challenging conditions, where success depends not only on solving isolated puzzles but also on iteratively constructing and refining spatial-temporal knowledge of a dynamically changing environment. On VisEscape, we observed that even state-of-the-art multimodal models generally fail to escape the rooms, showing considerable variation in their levels of progress and trajectories. To address this issue, we propose VisEscaper, which effectively integrates Memory, Feedback, and ReAct modules, demonstrating significant improvements by performing 3.7 times more effectively and 5.0 times more efficiently on average.
GuideDog: A Real-World Egocentric Multimodal Dataset for Blind and Low-Vision Accessibility-Aware Guidance
Mar 17, 2025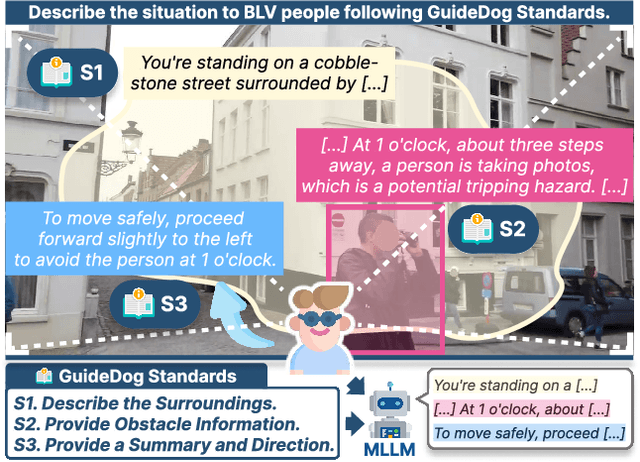



Mobility remains a significant challenge for the 2.2 billion people worldwide affected by blindness and low vision (BLV), with 7% of visually impaired individuals experiencing falls at least once a month. While recent advances in Multimodal Large Language Models (MLLMs) offer promising opportunities for BLV assistance, their development has been hindered by limited datasets. This limitation stems from the fact that BLV-aware annotation requires specialized domain knowledge and intensive labor. To address this gap, we introduce GuideDog, a novel accessibility-aware guide dataset containing 22K image-description pairs (including 2K human-annotated pairs) that capture diverse real-world scenes from a pedestrian's viewpoint. Our approach shifts the annotation burden from generation to verification through a collaborative human-AI framework grounded in established accessibility standards, significantly improving efficiency while maintaining high-quality annotations. We also develop GuideDogQA, a subset of 818 samples featuring multiple-choice questions designed to evaluate fine-grained visual perception capabilities, specifically object recognition and relative depth perception. Our experimental results highlight the importance of accurate spatial understanding for effective BLV guidance. GuideDog and GuideDogQA will advance research in MLLM-based assistive technologies for BLV individuals while contributing to broader applications in understanding egocentric scenes for robotics and augmented reality. The code and dataset will be publicly available.
Teaching Metric Distance to Autoregressive Multimodal Foundational Models
Mar 04, 2025As large language models expand beyond natural language to domains such as mathematics, multimodal understanding, and embodied agents, tokens increasingly reflect metric relationships rather than purely linguistic meaning. We introduce DIST2Loss, a distance-aware framework designed to train autoregressive discrete models by leveraging predefined distance relationships among output tokens. At its core, DIST2Loss transforms continuous exponential family distributions derived from inherent distance metrics into discrete, categorical optimization targets compatible with the models' architectures. This approach enables the models to learn and preserve meaningful distance relationships during token generation while maintaining compatibility with existing architectures. Empirical evaluations show consistent performance gains in diverse multimodal applications, including visual grounding, robotic manipulation, generative reward modeling, and image generation using vector-quantized features. These improvements are pronounced in cases of limited training data, highlighting DIST2Loss's effectiveness in resource-constrained settings.
MASS: Overcoming Language Bias in Image-Text Matching
Jan 20, 2025Pretrained visual-language models have made significant advancements in multimodal tasks, including image-text retrieval. However, a major challenge in image-text matching lies in language bias, where models predominantly rely on language priors and neglect to adequately consider the visual content. We thus present Multimodal ASsociation Score (MASS), a framework that reduces the reliance on language priors for better visual accuracy in image-text matching problems. It can be seamlessly incorporated into existing visual-language models without necessitating additional training. Our experiments have shown that MASS effectively lessens language bias without losing an understanding of linguistic compositionality. Overall, MASS offers a promising solution for enhancing image-text matching performance in visual-language models.
SEAL: Entangled White-box Watermarks on Low-Rank Adaptation
Jan 16, 2025Recently, LoRA and its variants have become the de facto strategy for training and sharing task-specific versions of large pretrained models, thanks to their efficiency and simplicity. However, the issue of copyright protection for LoRA weights, especially through watermark-based techniques, remains underexplored. To address this gap, we propose SEAL (SEcure wAtermarking on LoRA weights), the universal whitebox watermarking for LoRA. SEAL embeds a secret, non-trainable matrix between trainable LoRA weights, serving as a passport to claim ownership. SEAL then entangles the passport with the LoRA weights through training, without extra loss for entanglement, and distributes the finetuned weights after hiding the passport. When applying SEAL, we observed no performance degradation across commonsense reasoning, textual/visual instruction tuning, and text-to-image synthesis tasks. We demonstrate that SEAL is robust against a variety of known attacks: removal, obfuscation, and ambiguity attacks.