 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Visual Text Design Transfer Across Languages
Paper and Code



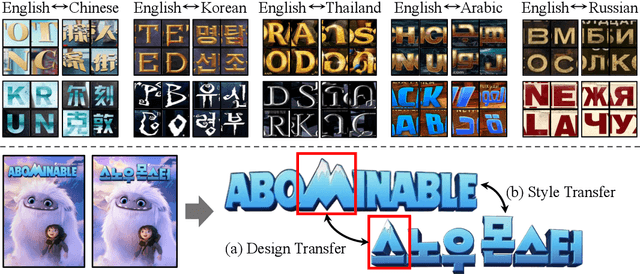
Visual text design plays a critical role in conveying themes, emotions, and atmospheres in multimodal formats such as film posters and album covers. Translating these visual and textual elements across languages extends the concept of translation beyond mere text, requiring the adaptation of aesthetic and stylistic features. To address this, we introduce a novel task of Multimodal Style Translation (MuST-Bench), a benchmark designed to evaluate the ability of visual text generation models to perform translation across different writing systems while preserving design intent. Our initial experiments on MuST-Bench reveal that existing visual text generation models struggle with the proposed task due to the inadequacy of textual descriptions in conveying visual design. In response, we introduce SIGIL, a framework for multimodal style translation that eliminates the need for style descriptions. SIGIL enhances image generation models through three innovations: glyph latent for multilingual settings, pretrained VAEs for stable style guidance, and an OCR model with reinforcement learning feedback for optimizing readable character generation. SIGIL outperforms existing baselines by achieving superior style consistency and legibility while maintaining visual fidelity, setting itself apart from traditional description-based approaches. We release MuST-Bench publicly for broader use and exploration https://huggingface.co/datasets/yejinc/MuST-Bench.